ELK
本文最后更新于:2023年12月5日 晚上
什么是 ELK
https://www.elastic.co/cn/what-is/elk-stack
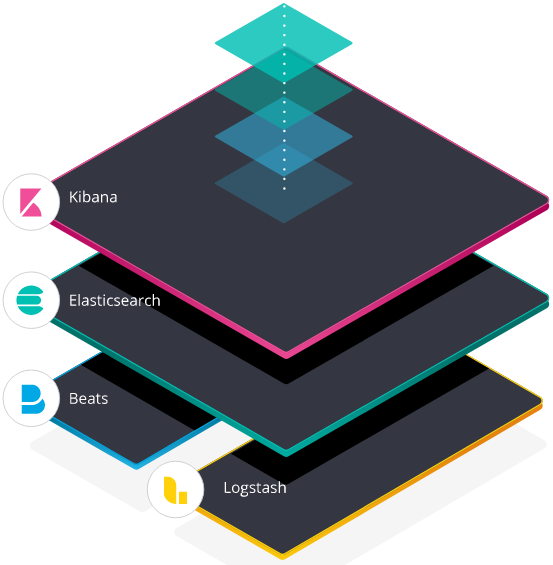
ELK 全称 ELK Stack,它的更新换代产品叫 Elastic Stack
ELK = Elasticsearch + Logstash + Kibana
- Elasticsearch:搜索和分析引擎
- Logstash:服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中
- Kibana:让用户在 Elasticsearch 中使用图形和图表对数据进行可视化
什么是 Elasticsearch
https://www.elastic.co/cn/what-is/elasticsearch
什么是 Logstash
Logstash 是 Elastic Stack 的核心产品之一,可用来对数据进行聚合和处理,并将数据发送到 Elasticsearch。Logstash 是一个开源的服务器端数据处理管道,允许您在将数据索引到 Elasticsearch 之前同时从多个来源采集数据,并对数据进行充实和转换。
什么是 kibana
https://www.elastic.co/cn/what-is/kibana
为什么使用 ELK
ELK 组件在海量日志系统的运维中,可用于解决以下主要问题:
- 分布式日志数据统一收集,实现集中式查询和管理
- 故障排查
- 安全信息和事件管理
- 报表功能
elasticsearch
基本概念
参考博客:https://www.cnblogs.com/qdhxhz/p/11448451.html
重点理解 index 和 document 这两个概念:index(索引)类似 kafka 的 topic,oss 的 bucket,要尽量控制 index 的数量;index 中的单条数据称为 document(文档),相当于 mysql 表中的行
之前的版本中,索引和文档中间还有个 type(类型)的概念,每个索引下可以建立多个 type,document 存储时需要指定 index 和 type,因为一个 index 中的 type 并不隔离,document 不能重名,所以 type 并没有多少意义。从 7.0 版本开始,一个 index 只能建一个名为_doc 的 type,8.0.0 以后将完全取消
下面是一个 document 的源数据:
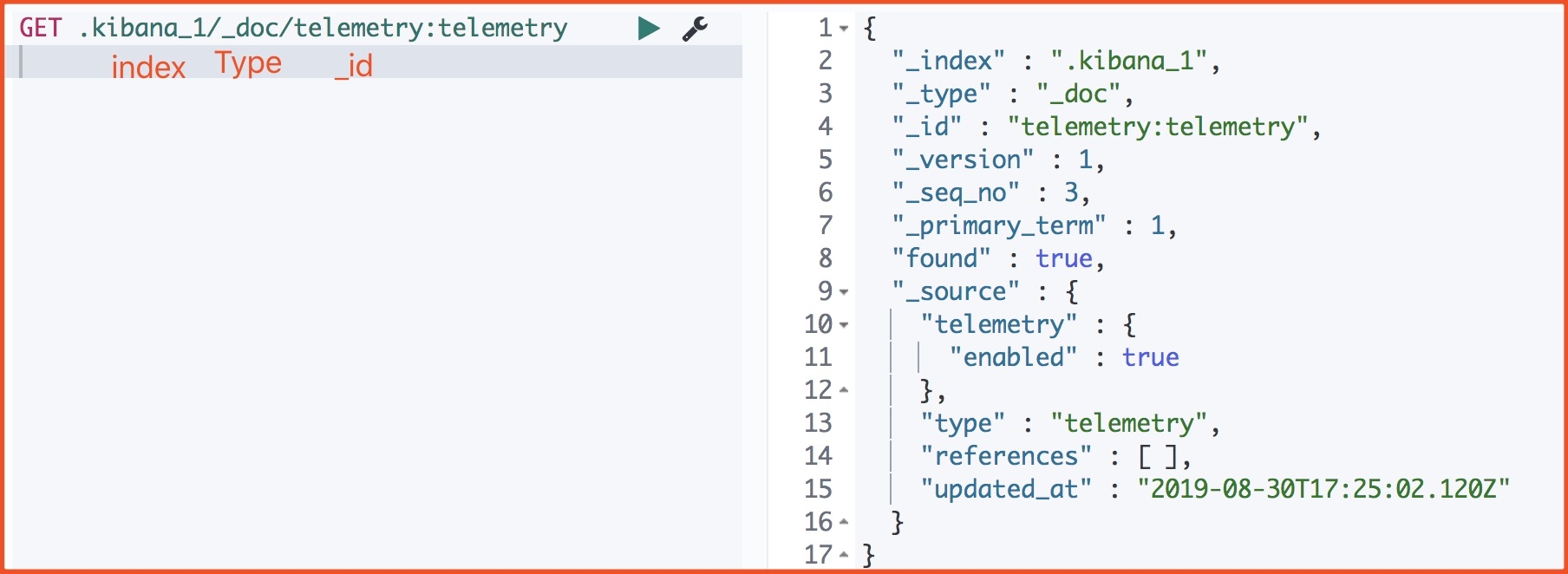
_index:文档所属索引名称_type:文档所属类型名_id:doc 主键,写入时指定,如果不指定,则系统自动生成一个唯一的 UUID 值_version:doc 版本信息,保证 doc 的变更能以正确的顺序执行,避免乱序造成的数据丢失_seq_no:严格递增的顺序号,shard 级别严格递增,保证后写入的 doc 的_seq_no大于先写入的 doc 的_seq_no_primary_term:和_seq_no一样是一个整数,每当 primary shard 发生重新分配时,比如重启,primary 选举等,_primary_term 会递增 1found:查询的 ID 正确那么 ture, 如果 Id 不正确,就查不到数据,found 字段就是 false_source:文档的原始 JSON 数据
apt 安装
elasticsearch 集群中 master 与 slave 的区别:
master:统计各节点状态信息、集群状态信息统计、索引的创建和删除、索引分配的管理、关闭节点等
slave:从 master 同步数据、等待机会成为 master
apt 安装
[root@elk2-ljk src]$dpkg -i elasticsearch-7.11.1-amd64.deb主要目录:
/usr/share/elasticsearch # 主目录 /etc/elasticsearch # 配置文件目录 ...修改 hosts
[root@elk2-ljk src]$vim /etc/hosts ... 10.0.1.121 elk1-ljk.local 10.0.1.122 elk2-ljk.local 10.0.1.123 elk3-ljk.local修改配置文件 elasticsearch.yml
[root@elk2-ljk /]$grep '^[a-Z]' /etc/elasticsearch/elasticsearch.yml cluster.name: es-cluster # ELK的集群名称,名称相同即属于是同一个集群 node.name: node-2 # 当前节点在集群内的节点名称 path.data: /data/elasticsearch/data # ES数据保存目录 path.logs: /data/elasticsearch/logs # ES日志保存目 bootstrap.memory_lock: true # 服务启动的时候锁定足够的内存,防止数据写入swap network.host: 10.0.1.122 # 监听本机ip http.port: 9200 # 监听端口 # 集群中node节点发现列表,最好使用hostname,这里为了方便,使用ip discovery.seed_hosts: ["elk1-ljk.local", "elk2-ljk.local", "elk3-ljk.local"] # 集群初始化那些节点可以被选举为master cluster.initial_master_nodes: ["node-1", "node-2", "node-3"] gateway.recover_after_nodes: 2 # 一个集群中的 N 个节点启动后,才允许进行数据恢复处理,默认是 1 # 设置是否可以通过正则或者_all 删除或者关闭索引库,默认 true 表示必须需要显式指定索引库名称,生产环境建议设置为 true,删除索引库的时候必须指定,否则可能会误删索引库中的索引库 action.destructive_requires_name: true修改内存限制
[root@elk2-ljk src]$vim /usr/lib/systemd/system/elasticsearch.service ... LimitMEMLOCK=infinity # 无限制使用内存[root@elk2-ljk src]$vim /usr/local/elasticsearch/config/jvm.options -Xms2g # 最小内存限制 -Xmx2g # 最大内存限制创建数据目录并修改属主
[root@elk2-ljk src]$mkdir -p /data/elasticsearch [root@elk3-ljk src]$chown -R elasticsearch:elasticsearch /data/elasticsearch启动
[root@elk1-ljk src]$systemctl start elasticsearch.service # 稍等几分钟 [root@elk1-ljk ~]$curl http://10.0.1.121:9200/_cat/nodes 10.0.1.123 13 96 0 0.14 0.32 0.22 cdhilmrstw - node-3 10.0.1.122 28 97 0 0.01 0.02 0.02 cdhilmrstw * node-2 # master 10.0.1.121 26 96 2 0.13 0.07 0.03 cdhilmrstw - node-1
源码编译
启动总是失败,各种报错,解决不了…
安装 elasticsearch 插件
插件是为了完成不同的功能,官方提供了一些插件但大部分是收费的,另外也有一些开发爱好者提供的插件,可以实现对 elasticsearch 集群的状态监控与管理配置等功能
head 插件
在 elasticsearch 5.x 版本以后不再支持直接安装 head 插件,而是需要通过启动一个服务方式
github 地址:https://github.com/mobz/elasticsearch-head
# git太慢,这里用迅雷下载zip包,然后上传
[root@elk1-ljk src]$unzip master.zip
[root@elk1-ljk src]$cd elasticsearch-head-master/
[root@elk1-ljk elasticsearch-head-master]$npm install grunt -save
[root@elk1-ljk elasticsearch-head-master]$npm install # 这一步要等很久
[root@elk1-ljk elasticsearch-head-master]$npm run start # 前台启动
# 开启跨域访问支持,每个节点都需要开启
[root@elk3-ljk ~]$vim /etc/elasticsearch/elasticsearch.yml
...
http.cors.enabled: true
http.cors.allow-origin: "*"
[root@elk2-ljk games]$systemctl restart elasticsearch.service # 重启elasticsearch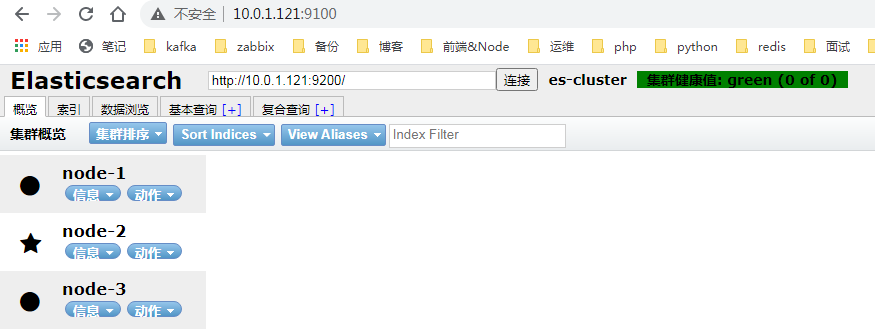
kopf 插件
过时的插件,只支持 elasticsearc 1.x 或 2.x 的版本
cerebro 插件
新开源的 elasticsearch 集群 web 管理程序,需要 java11 或者更高版本
github 地址:https://github.com/lmenezes/cerebro
[root@elk2-ljk src]$unzip cerebro-0.9.3.zip
[root@elk2-ljk src]$cd cerebro-0.9.3/
[root@elk2-ljk cerebro-0.9.3]$vim conf/application.conf
...
# host列表
hosts = [
{
host = "http://10.0.1.122:9200"
name = "es-cluster1" # host的名称,如果有多个elasticsearch集群,可以用这个name区分
# headers-whitelist = [ "x-proxy-user", "x-proxy-roles", "X-Forwarded-For" ]
}
]
[root@elk2-ljk cerebro-0.9.3]$./bin/cerebro # 前台启动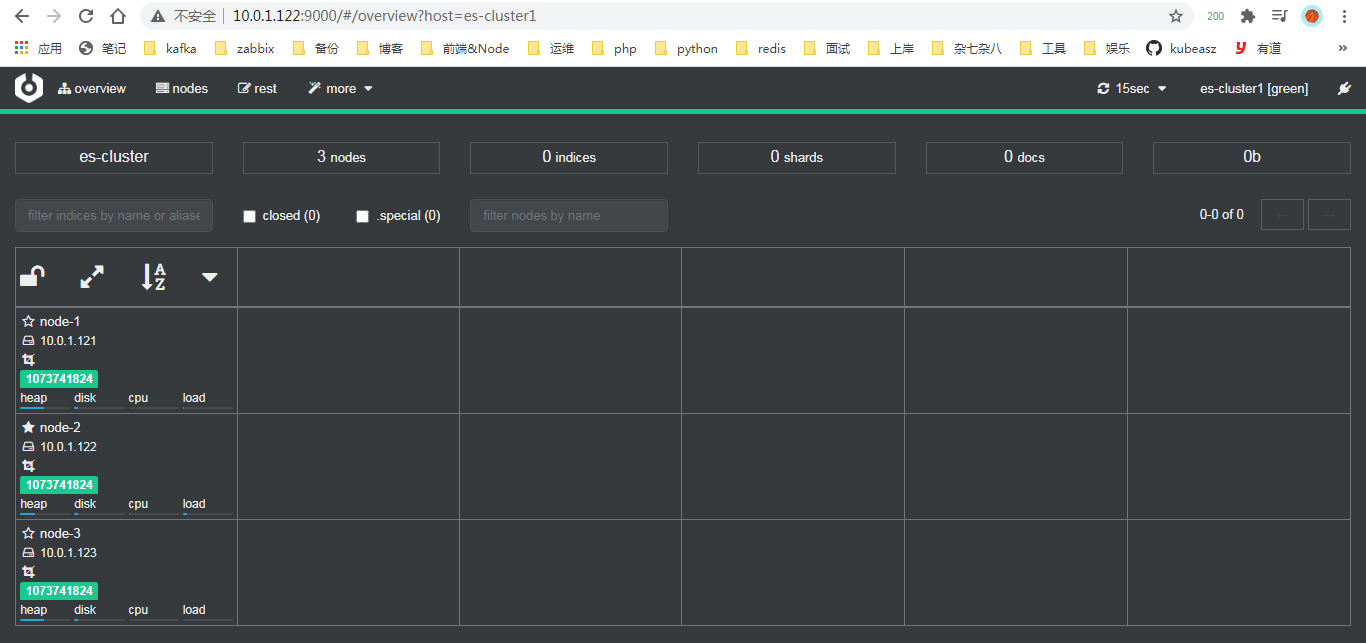
监控 elasticsearch 集群状态
[root@elk3-ljk ~]$curl http://10.0.1.122:9200/_cluster/health?pretty=true
{
"cluster_name" : "es-cluster",
"status" : "green", # green:运行正常、yellow:副本分片丢失、red:主分片丢失
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}如果是单节点,status 会显示 yellow,设置副本数为 0 即可解决:
[root@elk1-ljk ~]$curl -X PUT "10.0.1.121:9200/_settings" -H 'Content-Type: application/json' -d' {"number_of_replicas":0}'
{"acknowledged":true}或者:
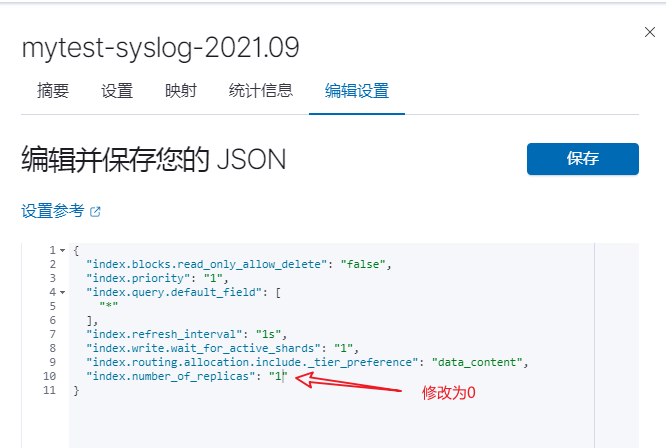
zabbix 添加监控
logstash
官方参考文档:https://www.elastic.co/guide/en/logstash/current/index.html
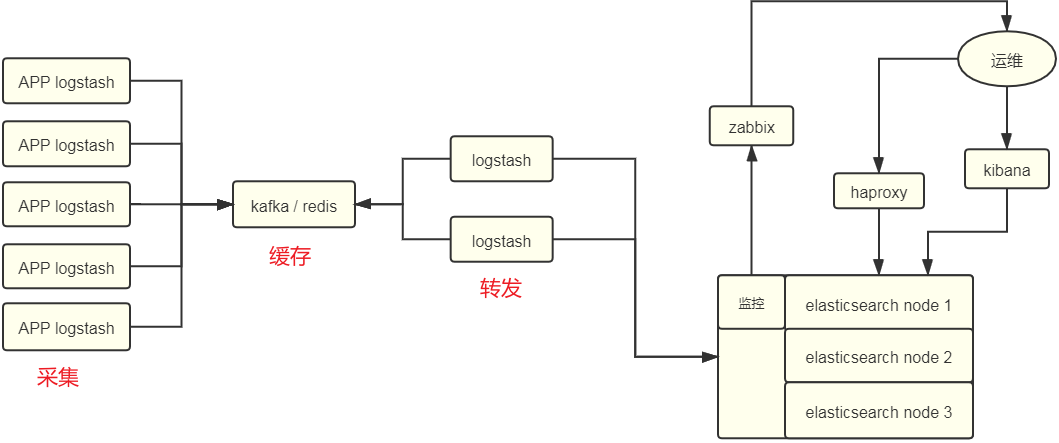
logstash 是一个具有 3 个阶段的处理管道:输入 –> 过滤器 –> 输出
输入生成事件,过滤器修改数据(日志),输出将数据(日志)发送到其他地方
安装
logstash 依赖 java,可以自己配置 java 环境,如果不配置,logstash 会使用其自带的 openjdk
[root@elk2-ljk src]$dpkg -i logstash-7.11.1-amd64.deb
# 修改启动用户为root,不然因为权限问题,后面会出现各种莫名其妙的错误,有些根本找不到报错
[root@elk2-ljk conf.d]$vim /etc/systemd/system/logstash.service
...
User=root
Group=root
...命令
[root@elk2-ljk bin]$./logstash --help-n:node name,就是节点的 hostname,例如:elk2-ljk.local
-f:从特定的文件或目录加载 logstash 配置。如果给定一个目录,该目录中的所有文件将按字典顺序合并,然后作为单个配置文件进行解析。您还可以指定通配符(globs),任何匹配的文件将按照上面描述的顺序加载
-e:从命令行加载 logstash 配置,一般不用
-t:检查配置文件是否合法,配合-f 使用,-f 指定配置文件,-t 检查
# 示例:检查test.conf的合法性 $/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/test.conf -t…
插件
logstash 的输入和输出都依赖插件
不同的插件使用不同的配置,但是所有输入插件都支持以下配置选项:
| 配置项 | 类型 | 说明 |
|---|---|---|
add_field |
hash | Add a field to an event |
codec |
codec | 用于输入数据的编解码器。输入编解码器是一种方便的方法,可以在数据进入输入之前对其进行解码,而不需要在 Logstash 管道中使用单独的过滤器 |
enable_metric |
boolean | Disable or enable metric logging for this specific plugin instance by default we record all the metrics we can, but you can disable metrics collection for a specific plugin. |
id |
string | 唯一的 ID,如果没有指定,logstash 会自动生成一个,尤其是多个相同类型的插件时,强烈建议配置此项,例如有多个 file 输入,应当配置此项防止混淆 |
tags |
array | Add any number of arbitrary tags to your event. This can help with processing later. |
type |
string | 类型,例如收集 /var/log/syslog 日志,type 可以设置为 “system”;收集网站日志,type 可以设置为 “web”。 此项用的较多,一般会根据判断 type 值来进行输出或过滤 |
所有输出插件都支持以下配置选项:
| 配置项 | 类型 | 说明 |
|---|---|---|
codec |
codec | 用于输出数据的编解码器。输出编解码器是一种方便的方法,可以在数据离开输出之前对数据进行编码,而不需要在 Logstash 管道中使用单独的过滤器 |
enable_metric |
boolean | Disable or enable metric logging for this specific plugin instance. By default we record all the metrics we can, but you can disable metrics collection for a specific plugin. |
id |
string | 唯一的 ID,如果没有指定,logstash 会自动生成一个,尤其是多个相同类型的插件时,强烈建议配置此项,例如有多个 file 输出,应当配置此项防止混淆 |
可以看到 input 和 output 插件都支持 codec 配置项,input 的 codec 根据被采集的日志文件确定,如果日志是 json 格式,则 input 插件的 codec 应当设置为 json;而 output 的 codec 根据数据库确定,如果是 elasticsearch,codec 保持默认的 rubydebug 即可,如果是 kafka,codec 应该设置为 json
input 插件
stdin
标准输入
file
日志输出到文件
| Setting | 说明 | 备注 |
|---|---|---|
path |
日志路径 | 必需 |
start_position |
从文件的开头或者结尾开始采集数据 | ["beginning", "end"] |
stat_interval |
日志收集的时间间隔 | 每个 input 文件都生成一个 .sincedb_xxxxx 文件,这个文件中记录了上次收集日志位置,下次从记录的位置继续收集 |
tcp
| Setting | 说明 | 备注 |
|---|---|---|
host |
当 mode 是server,host是监听的地址;当 mode 是 client,host是要连接的地址 |
默认0.0.0.0 |
mode |
server:监听客户端连接;client:连接到服务器; |
[“server”, “client”] |
port |
监听的端口或要连接的端口 | 必需 |
kafka
| Setting | 说明 | 备注 |
|---|---|---|
bootstrap_servers |
host1:port1,host2:port2 | |
topics |
要订阅的 topic 列表,默认为[“logstash”] | |
decorate_events |
是否添加一个 kafka 元数据,包含以下信息: topic、consumer_group、partition、offset、key |
布尔值 |
codec |
设置为 json |
output 插件
output
标准输出
elasticsearch
redis
| Setting | 说明 | 备注 |
|---|---|---|
key |
list(列表)名,或者 channel(频道)名, 至于是哪个取决于 data_type |
|
data_type |
如果data_type为list,将数据 push 到 list;如果 data_type为 channel,将数据发布到 channel; |
[“list”, “channel”] |
host |
redis 主机列表,可以是 hostname 或者 ip 地址 | 数组 |
port |
redis 服务端口,默认 6379 | |
db |
数据库编号,默认 0 | |
password |
身份认证,默认不认证 | 不建议设置密码 |
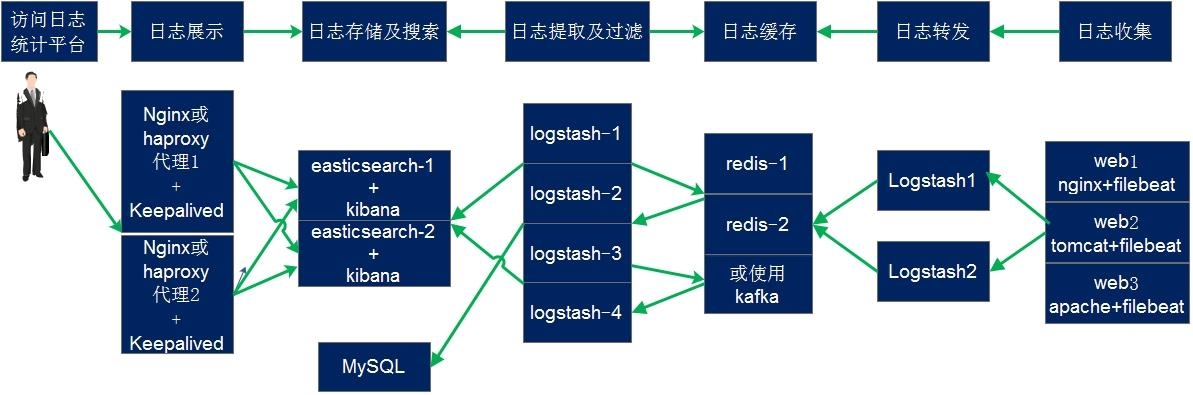
写个脚本统计 redis 的 key 数量,使用 zabbix-agent 定时执行脚本,一旦 key 超过某个数量,就增加 logstash 数量,从而加快从 redis 中取数据的速度
kafka
| Setting | 说明 | 备注 |
|---|---|---|
bootstrap_servers |
host1:port1,host2:port2 | |
topic_id |
主题 | |
codec |
设置为 json |
|
batch_size |
The producer will attempt to batch records together into fewer requests whenever multiple records are being sent to the same partition. This helps performance on both the client and the server. This configuration controls the default batch size in bytes. | 默认 16384 |
codec 插件
multiline
合并多行,比如 java 的一个报错,日志中会记录多行,为了方便查看,应该将一个报错的多行日志合并成一行
| Setting | 说明 | 备注 |
|---|---|---|
| pattern | 正则匹配 | 必需 |
| negate | 匹配成功或失败,就开始多行合并 | 布尔值 |
| what | 如果模式匹配,向前多行合并,还是向后多行合并 | 必需,["previous", "next"] |
配置
配置:https://www.elastic.co/guide/en/logstash/current/configuration.html
配置文件结构:https://www.elastic.co/guide/en/logstash/current/configuration-file-structure.html
配置文件语法:https://www.elastic.co/guide/en/logstash/current/event-dependent-configuration.html
使用环境变量:https://www.elastic.co/guide/en/logstash/current/environment-variables.html
配置文件示例:https://www.elastic.co/guide/en/logstash/current/config-examples.html
数据发送到 es:https://www.elastic.co/guide/en/logstash/current/connecting-to-cloud.html
input {
...
}
filter {
...
}
output {
...
}多配置文件
https://www.elastic.co/guide/en/logstash/current/multiple-pipelines.html
https://elasticstack.blog.csdn.net/article/details/100995868
示例:
# 定义了两个管道
[root@elk2-ljk logstash]$cat pipelines.yml
- pipeline.id: syslog
path.config: "/etc/logstash/conf.d/syslog.conf"
- pipeline.id: tomcat
path.config: "/etc/logstash/conf.d/tomcat.conf"
# syslog.conf 和 tomcat.conf,没有使用条件判断语句做输出判断
[root@elk2-ljk conf.d]$cat syslog.conf
input {
file {
type => "syslog"
path => "/var/log/syslog"
start_position => "end"
stat_interval => 3
}
}
output {
if [type] == "syslog" {
elasticsearch {
hosts => ["10.0.1.121:9200"]
index => "mytest-%{type}-%{+xxxx.ww}"
}
}
}
[root@elk2-ljk conf.d]$cat tomcat.conf
input {
file {
type => "tomcat-access-log"
path => "/usr/local/tomcat/logs/tomcat_access_log.*.log"
start_position => "end"
stat_interval => 3
}
}
output {
elasticsearch {
hosts => ["10.0.1.121:9200"]
index => "mytest-%{type}-%{+xxxx.ww}"
}
}
# 启动,注意一定要以为root用户启动
[root@elk2-ljk conf.d]$systemctl restart logstash.service效果:
测试
标准输入输出
[root@elk2-ljk conf.d]$cat /etc/logstash/conf.d/test.conf
input {
stdin {}
}
output {
stdout {}
}
[root@elk2-ljk conf.d]$/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/test.conf
... # 启动得等一会
[INFO ] 2021-03-04 18:10:06.020 [Api Webserver] agent - Successfully started Logstash API endpoint {:port=>9600}
hello word # 标准输入
{
"@timestamp" => 2021-03-04T10:10:15.528Z, # 当前事件的发生时间
"host" => "elk2-ljk.local", # 标记事件发生的节点
"@version" => "1", # 事件版本号,一个事件就是一个 ruby 对象
"message" => "hello word" # 息的具体内容
}输出到文件
# 1. 修改被采集日志文件权限,至少让logstash用户可以读
[root@elk2-ljk conf.d]$chmod o+r /var/log/syslog
[root@elk2-ljk conf.d]$chmod o+r /var/log/auth.log
# 2. 编写配置文件,采集多个日志文件,输出到不同的文件
[root@elk2-ljk conf.d]$vim system-log.conf
input {
file {
type => "syslog"
path => "/var/log/syslog"
start_position => "end"
stat_interval => 5
}
file {
type => "authlog"
path => "/var/log/auth.log"
start_position => "end"
stat_interval => 5
}
}
output {
if [type] == "syslog" {
file {
path => "/tmp/%{type}.%{+yyyy.MM.dd}"
}
}
if [type] == "authlog" {
file {
path => "/tmp/%{type}.%{+yyyy.MM.dd}"
}
}
}
# 3. 检查配置文件是否合法
[root@elk2-ljk conf.d]$/usr/share/logstash/bin/logstash -f ./system-log.conf -t
# 4. 重启logstash.service
[root@elk2-ljk conf.d]$systemctl restart logstash.service
# 5. 观察输出文件
[root@elk2-ljk conf.d]$tail -f /tmp/syslog.2021.03.05
...
[root@elk2-ljk conf.d]$tail -f /tmp/authlog.2021.03.05
...时间格式参考:http://joda-time.sourceforge.net/apidocs/org/joda/time/format/DateTimeFormat.html
输出到 elasticsearch
elasticsearch 输出插件至少指定 hosts 和index,hosts可以指定 hosts 列表
input {
file {
type => "syslog"
path => "/var/log/syslog"
start_position => "end"
stat_interval => 3
}
}
output {
elasticsearch {
hosts => ["10.0.1.121:9200"]
index => "mytest-%{type}-%{+xxxx.ww}"
}
}kibana
开源的数据分析和可视化平台,可以 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作,可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现
安装
[root@elk1-ljk src]$tar zxf kibana-7.11.1-linux-x86_64.tar.gz
[root@elk1-ljk src]$mv kibana-7.11.1-linux-x86_64 /usr/local/kibana
[root@elk1-ljk src]$cd /usr/local/kibana
[root@elk1-ljk kibana]$grep '^[a-Z]' config/kibana.yml # 修改以下配置项
server.port: 5601
server.host: "10.0.1.121"
elasticsearch.hosts: ["http://10.0.1.121:9200"]
i18n.locale: "zh-CN"
[root@elk1-ljk kibana]$./bin/kibana --allow-root # 启动
# nohup ./bin/kibana --allow-root >/dev/null 2>&1 & # 后台启动因为笔记本的性能问题,将 elasticsearch 集群缩减为 elasticsearch 单节点,这导致 kibana 无法连接到 elasticsearch,启动失败。解决办法:将 elasticsearch 的数据目录清空,然后重启
[root@elk1-ljk data]$systemctl stop elasticsearch.service # 停止elasticsearch
[root@elk1-ljk data]$ls /data/elasticsearch/
data logs
[root@elk1-ljk data]$rm -rf /data/elasticsearch/* # 清空数据目录
[root@elk1-ljk data]$systemctl start elasticsearch.service # 重新启动elasticsearch
[root@elk1-ljk kibana]$./bin/kibana --allow-root # 再次启动kibana查看状态
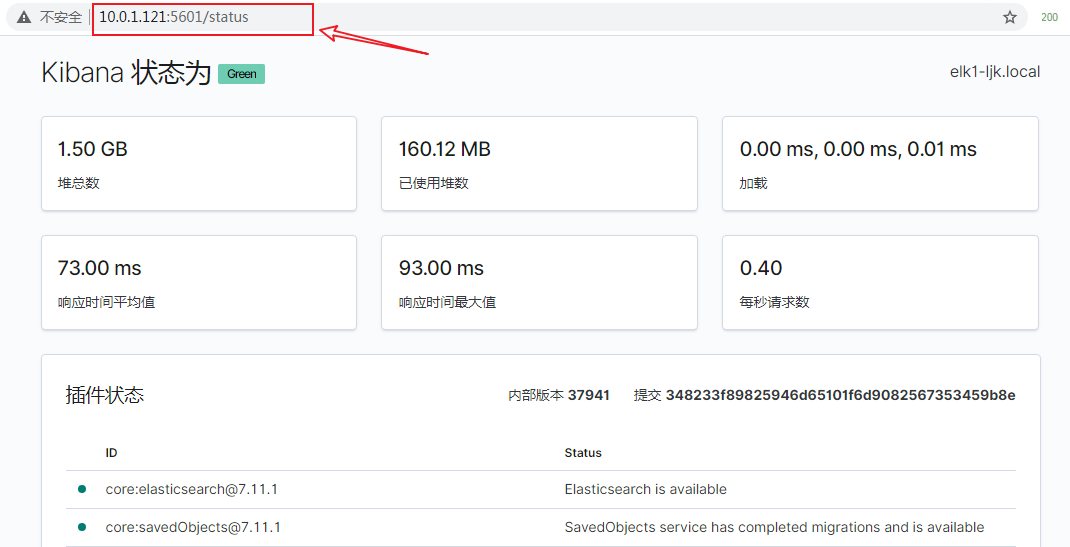
kibana 画图功能详解
添加一个仪表盘
Beats
https://www.elastic.co/cn/beats/
logstash 基于 java,资源消耗很大,容器等场景,大多跑的都是轻量级的服务,没有必要安装 logstash,就可以用 beats 代替 logstash 做日志收集,beats 基于 go,性能更强,资源占用更低,但是功能也相对简单
beats 是一个系列,具体包含以下类型的采集器:
- filebeat:轻量型日志采集器,最常用
- metricbeat:轻量型指标采集器,获取系统级的 CPU 使用率、内存、文件系统、磁盘 IO 和网络 IO 统计数据,还可针对系统上的每个进程获得与 top 命令类似的统计数据
- heartbeat:面向运行状态监测的轻量型采集器,通过 ICMP、TCP 和 HTTP 进行 ping 检测主机、网站可用性
- packetbeat:轻量型网络数据采集器
- winlogbeat:轻量型 Windows 事件日志采集器
- auditbeat:轻量型审计日志采集器
- functionbeat:面向云端数据的无服务器采集器
除了 filebeat,其他的 beat 可以用 zabbix 替代
filebeat
官方文档:https://www.elastic.co/guide/en/beats/filebeat/current/index.html
配置:只需要配置 input 和 output
# ============================== Filebeat inputs ==================
filebeat.inputs:
- type: log # 日志type
enabled: false # 是否启动
paths: # 被采集日志,可以写多个
- /var/log/*.log
exclude_lines: ['^DBG'] # 不采集日志中的哪些行
include_lines: ['^ERR', '^WARN'] # 只采集日志中的哪些行
exclude_files: ['.gz$'] # 从paths的匹配中排除哪些文件
fields: # 自定义字段,可以定义多个,后面用来做条件判断
level: debug
review: 1
multiline.pattern: ^\[ # 合并多行,匹配规则
multiline.negate: false # 合并多行,配皮成功或失败执行合并
multiline.match: after # 合并多行,向前合并还是向后合并
# ============================== Filebeat modules ==============================
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
reload.period: 10s
# ======================= Elasticsearch template setting =======================
setup.template.settings:
index.number_of_shards: 1
index.codec: best_compression
_source.enabled: false
# ================================== General ===================================
#name:
#tags: ["service-X", "web-tier"]
#fields:
# env: staging
# ================================= Dashboards =================================
#setup.dashboards.enabled: false
#setup.dashboards.url:
# =================================== Kibana ===================================
setup.kibana:
#host: "localhost:5601"
#space.id:
# =============================== Elastic Cloud ================================
#cloud.id:
#cloud.auth:
# ================================== Outputs ===================================
# 不同的output,有不同的配置,但是没有条件判断功能,无法根据不同的input使用不用的output
# ---------------------------- Elasticsearch Output ----------------------------
#output.elasticsearch:
#hosts: ["localhost:9200"]
#protocol: "https"
#api_key: "id:api_key"
#username: "elastic"
#password: "changeme"
# ------------------------------ Logstash Output -------------------------------
#output.logstash:
#hosts: ["localhost:5044"]
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
#ssl.certificate: "/etc/pki/client/cert.pem"
#ssl.key: "/etc/pki/client/cert.key"
# ================================= Processors =================================
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
# ================================== Logging ===================================
#logging.level: debug
#logging.selectors: ["*"]
# ============================= X-Pack Monitoring ==============================
#monitoring.enabled: false
#monitoring.cluster_uuid:
#monitoring.elasticsearch:
# ============================== Instrumentation ===============================
#instrumentation:
#enabled: false
#environment: ""
#hosts:
# - http://localhost:8200
#api_key:
#secret_token:
# ================================= Migration ==================================
#migration.6_to_7.enabled: true
示例: