Keepalived
本文最后更新于:2023年12月5日 晚上
高可用集群
集群类型
- LB:load balance,负载均衡,例如 LVS / HAProxy / Nginx(http/upstream、stream/upstream)
- HA:high availability 高可用集群
- HPC:High Performance Computing,高性能集群,例如 超级计算机天河二号
系统可用性
SLA:Service-Level Agreement,服务等级协议,指标:99.9%, 99.99%, 99.999%,99.9999%
MTBF:Mean Time Between Failure,平均无故障工作时间
MTTR:Mean Time To Repair,平均故障时间
A = MTBF / (MTBF+MTTR)
# 99.95%
(60*24*30)*(1-0.9995)=21.6分钟 # 一般按一个月停机时间统计HA Cluster 实现方案 VRRP
Virtual Router Redundancy Protocol,虚拟路由冗余协议,解决静态网关单点风险
- 物理层:路由器、三层交换机
- 软件层:keeplived
VRRP 网络硬件实现
参考:https://support.huawei.com/enterprise/zh/doc/EDOC1000141382/19258d72/basic-concepts-of-vrrp
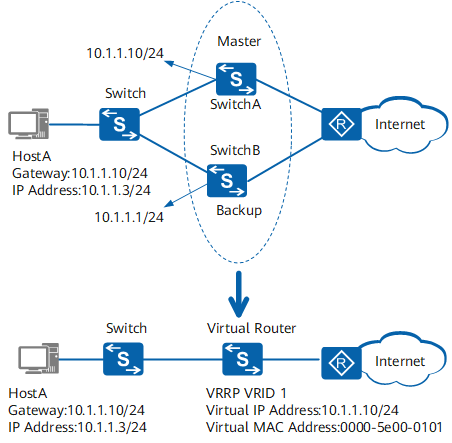
VRRP 备份组示意图:
VRRP 相关术语
- VRRP 路由器(VRRP Router):运行 VRRP 协议的设备,它可能属于一个或多个虚拟路由器,如 SwitchA 和 SwitchB。
- 虚拟路由器(Virtual Router):又称 VRRP 备份组,由一个 Master 设备和多个 Backup 设备组成,被当作一个共享局域网内主机的缺省网关。如 SwitchA 和 SwitchB 共同组成了一个虚拟路由器。
- Master 路由器(Virtual Router Master):承担转发报文任务的 VRRP 设备,如 SwitchA。
- Backup 路由器(Virtual Router Backup):一组没有承担转发任务的 VRRP 设备,当 Master 设备出现故障时,它们将通过竞选成为新的 Master 设备,如 SwitchB。
- VRID:虚拟路由器的标识。如 SwitchA 和 SwitchB 组成的虚拟路由器的 VRID 为 1。
- 虚拟 IP 地址(Virtual IP Address):虚拟路由器的 IP 地址,一个虚拟路由器可以有一个或多个 IP 地址,由用户配置。如 SwitchA 和 SwitchB 组成的虚拟路由器的虚拟 IP 地址为 10.1.1.10/24。
- IP 地址拥有者(IP Address Owner):如果一个 VRRP 设备将虚拟路由器 IP 地址作为真实的接口地址,则该设备被称为 IP 地址拥有者。如果 IP 地址拥有者是可用的,通常它将成为 Master。如 SwitchA,其接口的 IP 地址与虚拟路由器的 IP 地址相同,均为 10.1.1.10/24,因此它是这个 VRRP 备份组的 IP 地址拥有者。
- 虚拟 MAC 地址(Virtual MAC Address):虚拟路由器根据虚拟路由器 ID 生成的 MAC 地址。一个虚拟路由器拥有一个虚拟 MAC 地址,格式为:00-00-5E-00-01-{VRID}(VRRP for IPv4);00-00-5E-00-02-{VRID}(VRRP for IPv6)。当虚拟路由器回应 ARP 请求时,使用虚拟 MAC 地址,而不是接口的真实 MAC 地址。如 SwitchA 和 SwitchB 组成的虚拟路由器的 VRID 为 1,因此这个 VRRP 备份组的 MAC 地址为 00-00-5E-00-01-01。
keepalived 初步介绍
vrrp 协议的软件实现,原生设计目的是为了高可用 ipvs(ip virtual server)服务
负载均衡有 LVS、Nginx、HAProxy 可以选择,但是冗余路由只能选择 keepalived,没有其他类似的软件可以选择
- 基于 vrrp 协议完成地址流动
- 为 vip 地址所在的节点生成 ipvs 规则(在配置文件中预先定义)
- 为 ipvs 集群的各 RS 做健康状态检测
- 基于脚本调用接口完成脚本中定义的功能,进而影响集群事务,以此支持 nginx、haproxy 等服务
keepalived 架构

用户空间的核心组件:
- VRRP Stack:最重要的核心功能,实现了 VIP,利用 VIP 就可以做到 IP 地址的浮动,将来用户只需要访问 VIP,至于 VIP 是由哪个机器提供,利用 VRRP 协议可以控制,谁是主谁就提供 VIP
- Checkers:状态监测,可以监测后端服务器(RS)的健康状况,而 LVS 是不提供这个功能的
- System call:在 vrrp 协议状态转换时(就是主节点挂了,把备用节点提升为主节点的时候),可以调用脚本执行一些操作
- SMTP:邮件组件,比如 当服务器挂了,可以发邮件报警
- IPVS wrapper:管理 ipvs 规则
- Netlink Reflector:网络接口,监控网卡状态,和网卡进行通信
- WatchDog:监控其他组件,其他组件出现问题,由 watchdog 进行解决
- 控制组件:提供 keepalived.conf 的解析器,完成 Keepalived 配置
- IO 复用器:针对网络目的而优化的自己的线程抽象
- 内存管理组件:为某些通用的内存管理功能(例如分配,重新分配,发布等)提供访问权限
keepalived 启动后会有三个进程:
- 父进程:内存管理,子进程管理等等
- 子进程:VRRP 子进程
- 子进程:healthchecker 子进程
Keepalived <-- Parent process monitoring children # 一个主进程
\_ Keepalived <-- VRRP child # 子进程,负责VRRP
\_ Keepalived <-- Healthchecking child # 子进程,负责健康性检查有图可知,两个子进程都被系统 WatchDog 看管,两个子进程各自复杂自己的事,healthchecker 子进程复杂检查各自服务器的健康程度,例如 HTTP,LVS 等等,如果 healthchecker 子进程检查到 MASTER 上服务不可用了,就会通知本机上的兄弟 VRRP 子进程,让他删除通告,并且去掉虚拟 IP,转换为 BACKUP 状态。
keepalived 安装
[root@c71 ~]$yum install keepalived -y
[root@c71 ~]$rpm -ql keepalived
/etc/keepalived
/etc/keepalived/keepalived.conf # 配置文件
/etc/sysconfig/keepalived
/usr/bin/genhash
/usr/lib/systemd/system/keepalived.service
/usr/libexec/keepalived
/usr/sbin/keepalived # 主程序文件
...
各种配置示例文件
...注意:CentOS7 上重启可能失败
systemctl restart keepalived # 可能失败,新配置无法生效
systemctl stop keepalived; systemctl start keepalived # 将重启分为停止和启动两步来执行keepalived 配置文件
参考:https://blog.csdn.net/weixin_42256765/article/details/103223793
keepalived 配置文件:/etc/keepalived/keepalived.conf
global_defs # 全局配置
vrrp_instance # vrrp配置
virtual_server # 和lvs相关的设置生产环境复杂时,keepalived.conf 中内容过多,不易管理,可以将不同集群的配置放在单独的子配置文件,利用 include 指令包含子配置文件
[root@c71 ~]$cd /etc/keepalived/
[root@c71 keepalived]$mkdir conf.d
[root@c71 keepalived]$cat keepalived.conf
global_defs {
...
}
vrrp_instance VI_1 {
...
}
include ./conf.d/*.conf全局配置
global_defs {
notification_email {
441757636@qq.com # keepalived发生故障切换时邮件发送的目标邮箱,可以按行区分写多个
}
notification_email_from keepalived@localhost # 发邮件的地址
smtp_server 127.0.0.1 # 邮件服务器地址
smtp_connect_timeout 30 # 邮件服务器连接timeout
# 以上邮箱相关的配置都是无效的,配置了也无法生效
router_id c71 # 每个keepalived主机唯一标识,建议使用当前主机名,但其实重名了也不影响
vrrp_skip_check_adv_addr # 默认对所有通告报文都检查,比较消耗性能,启用此配置后,如果收到的通告报文和上一个报文是同一个路由器,则跳过检查
vrrp_strict # 严格遵守VRRP协议,如果启用此项,以下三种状况将无法启动服务:1.无VIP地址 2.配置了单播邻居 3.在VRRP版本2中有IPv6地址。开启动此项并且没有配置vrrp_iptables时会自动开启iptables防火墙规则,默认导致VIP无法访问,建议注释掉此项配置
vrrp_garp_interval 0 # gratuitous ARP messages 报文发送延迟,0表示不延迟
vrrp_gna_interval 0 # unsolicited NA messages (不请自来)消息发送延迟
vrrp_mcast_group4 224.0.0.18 # 指定组播IP地址范围:224.0.0.0到239.255.255.255,如果有多组keepalived服务器集群,应该每个集群设置不同的组播地址,避免产生干扰
vrrp_iptables # 此项和vrrp_strict同时开启时,则不会添加防火墙规则,如果无配置vrrp_strict项,则无需启用此项配置
}如果启用了vrrp_strict,也需要启用vrrp_iptables,否则因为防火墙,会导致生成的 VIP 无法访问
配置虚拟路由器
允许在一个物理服务器上安装多个 vrrp 实例,每个 vrrp 实例可以单独配置 VIP,例如,有的 vrrp 实例后端是 mysql 服务,有的 vrrp 实例后端是 nginx 服务
vrrp_instance VI_1 { # 指定实例名,VI_1
state MASTER # 指定master或者backup,其实此项不起作用,真正起作用的是优先级 priority
interface eth0 # vrrp实例绑定的网口,因为在虚拟IP的时候必须是在已有的网口上添加
virtual_router_id 51 # 虚拟路由器的id,0-255,一个局域网内,要确保每个虚拟路由器的id都不同
priority 100 # 优先级,1-254,虚拟路由器中的每个keepalived节点的优先级都不同
advert_int 1 # 相互通告优先级,默认1s,超时则认为出故障
authentication { # 相互通告优先级,需要验证
auth_type PASS # 认证方式:PASS为简单密码(建议使用)
auth_pass 123456 # 密码
}
virtual_ipaddress { # 虚拟ip,生产环境可能指定上百个IP地址
# <IPADDR>/<MASK> brd <IPADDR> dev <STRING> scope <SCOPE> label <LABEL>
10.0.0.100/24 dev eth0 label eth0:1
}
# 跟踪接口,设置额外的监控,里面任意一块网卡出现问题,都会进入故障(FAULT)状态,切换主备状态,例如,用nginx做均衡器的时候,内网必须正常工作,如果内网出问题了,这个均衡器也就无法运作了,所以必须对内外网同时做健康检查
track_interface {
eth0
eth1
...
}
}
[root@c71 keepalived]$systemctl restart keepalived.service # 重启
[root@c71 keepalived]$ip a
...
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:02:6d:64 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.71/24 brd 10.0.0.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet 10.0.0.100/24 scope global secondary eth0:1 # 成功将vip10.0.0.100分配给eth0
valid_lft forever preferred_lft forever
inet6 fe80::f850:2415:92a0:3fe6/64 scope link noprefixroute
valid_lft forever preferred_lft forever
...启用 keepalived 日志功能
每个节点都要统一以下配置:
[root@c71 log]$vim /etc/sysconfig/keepalived
KEEPALIVED_OPTIONS="-D -S 6" # 添加 "-S 6" 参数
[root@c71 log]$vim /etc/rsyslog.conf
...
local6.* /var/log/keepalived.log # 添加此行
...
[root@c71 log]$tail -f /var/log/keepalived.log # 查看是否记录日志keepalived 企业应用
单主架构
两台服务器:10.0.0.71、10.0.0.72
master 配置
10.0.0.71
global_defs {
notification_email {
441757636@qq.com
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id c71 # c71
vrrp_skip_check_adv_addr
# vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.0.18
}
vrrp_instance VI_1 {
state MASTER # MASTER
interface eth0
virtual_router_id 1
priority 100 # 优先级
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
10.0.0.100/24 dev eth0 label eth0:1
}
}
# include ./conf.d/*.confbackup 配置
10.0.0.72
# 配置文件和master基本一致,只需修改三行
global_defs {
notification_email {
441757636@qq.com
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id c72 # c72
vrrp_skip_check_adv_addr
# vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.0.18
}
vrrp_instance VI_1 {
state BACKUP # BACKUP
interface eth0
virtual_router_id 1
priority 80 # 优先级
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
10.0.0.100/24 dev eth0 label eth0:1
}
}
# include conf.d/*.conf抓包观察
tcpdump -i eth0 -nn host 224.0.0.18 # 224.0.0.18 是组播地址双主架构
上面的单主模式只有一个 VIP,如果是多个 VIP,为了提高服务器的利用率,将 master 和 backup 均匀分配到每一台服务器上,这种模式就是双主架构
两台服务器:10.0.0.71、10.0.0.72
两个 VIP:10.0.0.100/24、10.0.0.200/24
# 10.0.0.71,VI_1 master,VI_2,backup
global_defs {
notification_email {
441757636@qq.com
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id c71 # c71
vrrp_skip_check_adv_addr
# vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.0.18
}
vrrp_instance VI_1 {
state MASTER # MASTER
interface eth0
virtual_router_id 1
priority 100 # 优先级
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
10.0.0.100/24 dev eth0 label eth0:1
}
}
vrrp_instance VI_2 {
state BACKUP # BACKUP
interface eth0
virtual_router_id 1
priority 80 # 优先级
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
10.0.0.200/24 dev eth0 label eth0:1
}
}
# include ./conf.d/*.conf# 10.0.0.72,VI_1 backup,VI_2 master,只需要修改5行,省略号表示配置一样的部分
global_defs {
...
router_id c72 # c72
# vrrp_strict
...
}
vrrp_instance VI_1 {
state BACKUP # MASTER
priority 80 # 优先级
...
}
vrrp_instance VI_2 {
state MASTER # MASTER
priority 100 # 优先级
...
}
# include ./conf.d/*.conf抢占模式和非抢占模式
抢占式:preempt,高优先级的主机恢复在线后,会抢占低先级的主机的 master 角色,造成网络抖动
非抢占式:nopreempt,高优级主机恢复后,不会抢占低优先级主机的 master 角色
如果只有一个 VIP,建议设置为非抢占模式 nopreempt
非抢占模式
两台服务器:10.0.0.71、10.0.0.72
一个 VIP:10.0.0.100/24
# 10.0.0.71
vrrp_instance VI_1 {
state BACKUP # BACKUP,两台服务器都是BACKUP
priority 100 # 优先级高
nopreempt # 指定模式:非抢占式
...
}
# 10.0.0.72
vrrp_instance VI_1 {
state BACKUP # BACKUP,两台服务器都是BACKUP
priority 80 # 优先级低
nopreempt # 指定模式:非抢占式
...
}抢占延迟模式
优先级高的主机恢复后,不会立即抢回 VIP,而是延迟一段时间(默认 300s)再抢回 VIP
两台服务器:10.0.0.71、10.0.0.72
一个 VIP:10.0.0.100/24
# 10.0.0.71
vrrp_instance VI_1 {
state BACKUP # BACKUP,两台服务器都是BACKUP
priority 100 # 优先级高
preempt_delay 60 # 抢占延迟模式,默认延迟300s
...
}
# 10.0.0.72
vrrp_instance VI_1 {
state BACKUP # BACKUP,两台服务器都是BACKUP
priority 80 # 优先级低
...
}VIP 单播配置
keepalived 主机之间默认利用多播相互通告消息,会造成网络拥塞,可以替换成单播,减少网络流量
在所有节点 vrrp_instance 语句块中设置对方主机的 IP,建议设置为专用于对应心跳线网络的地址,而非使用业务网络
unicast_src_ip <IPADDR> # 指定发送单播的源IP
unicast_peer {
<IPADDR> # 指定接收单播的对方目标主机IP
......
}两台服务器:10.0.0.71、10.0.0.72
一个 VIP:10.0.0.100/24
# 10.0.0.71
vrrp_instance VI_1 {
...
virtual_ipaddress {
10.0.0.10/24 dev eth0 label eth0:1
}
unicast_src_ip 10.0.0.71 # 本机IP
unicast_peer{
10.0.0.72 # 指向对方主机IP
10.0.0.82 # 如果有多个keepalived,再加其它节点的IP
}
}
# 10.0.0.72
vrrp_instance VI_1 {
...
virtual_ipaddress {
10.0.0.10/24 dev eth0 label eth0:1
}
unicast_src_ip 10.0.0.72 # 本机IP
unicast_peer{
10.0.0.71 # 指向对方主机IP
}
}抓包:
tcpdump -i eth0 -nn host 10.0.0.71 and host 10.0.0.72通知脚本配置
当 keepalived 的状态变化时,可以自动触发脚本(sh、py、php 各种脚本)的执行,比如:发邮件、短信、微信通知用户
global_defs {
......
# 指定脚本执行用户的身份,如果不指定,默认用户keepalived_script,如果此用户不存在,则root执行脚本
script_user <USER>
}通知脚本类型
notify_master <STRING>|<QUOTED-STRING> # 当前节点成为主节点时触发的脚本
notify_backup <STRING>|<QUOTED-STRING> # 当前节点转为备节点时触发的脚本
notify_fault <STRING>|<QUOTED-STRING> # 当前节点转为“失败”状态时触发的脚本
notify <STRING>|<QUOTED-STRING> # 通用格式的通知触发机制,一个脚本可完成以上三种状态的转换时的通知
notify_stop <STRING>|<QUOTED-STRING> # 当停止VRRP时触发的脚本邮件服务
# 安装邮件服务
yum -y install mailx
# 配置/etc/mail.rc
set from=ljkk3014@foxmail.com
set smtp=smtp.qq.com
set smtp-auth-user=ljkk3014@foxmail.com
set smtp-auth-password=jwxxxxxxxxg
# 发送测试邮件
echo -e "Hello, I am `whoami`,The system version is here,please help me to check it ,thanks! \n`cat /etc/os-release`" | mail -s hello 441757636@qq.com
实战案例:实现 Keepalived 状态切换的通知脚本
在所有 keepalived 节点配置如下:
[root@c72 ~]$cat /etc/keepalived/notify.sh
#!/bin/bash
contact='441757636@qq.com'
notify() {
mailsubject="$(hostname) to be $1, vip floating"
mailbody="$(date +'%F %T'): vrrp transition, $(hostname) changed to be $1"
echo "$mailbody" | mail -s "$mailsubject" $contact
}
case $1 in
master)
notify master
;;
backup)
notify backup
;;
fault)
notify fault
;;
*)
echo "Usage: $(basename $0) {master|backup|fault}"
exit 1
;;
esac
[root@c72 ~]$cat /etc/keepalived/keepalived.conf
...
vrrp_instance VI_1 {
...
virtual_ipaddress {
10.0.0.100/24 dev eth0 label eth0:1
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}
# include conf.d/*.conf
# 将master下线
[root@c72 ~]$systemctl stop keepalived.service查看邮箱:
实现 IPVS 的高可用性
keepalived 也提供了管理 IPVS 规则的功能,在实现 VIP 高可用的同时,还能实现 IPVS 的高可用。
所以 ipvsadm 就没什么用了
VS 配置
virtual_server IP port # 定义虚拟主机IP地址及其端口
virtual_server fwmark int # ipvs的防火墙打标,实现基于防火墙的负载均衡集群
virtual_server group string # 使用虚拟服务器组
virtual_server IP port {
...
real_server {
...
}
real_server {
...
}
...
}virtual_server IP port { # VIP和PORT
delay_loop <INT> # 检查后端服务器的时间间隔
lb_algo rr|wrr|lc|wlc|lblc|sh|dh # 定义调度方法
lb_kind NAT|DR|TUN # 集群的类型,注意要大写
persistence_timeout <INT> # 持久连接时长
protocol TCP|UDP|SCTP # 指定服务协议,一般为TCP
sorry_server <IPADDR> <PORT> # 所有RS故障时,备用服务器地址
real_server <IPADDR> <PORT> { # RS的IP和PORT
weight <INT> # RS权重
notify_up <STRING>|<QUOTED-STRING> # RS上线通知脚本
notify_down <STRING>|<QUOTED-STRING> # RS下线通知脚本
HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK { ... } #定义当前主机健康状态检测方法
}
}VS 组
将多个 VS 定义成一个组,统一对外服务,如:http 和 https 定义成一个虚拟服务器组
示例文件:/usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.virtual_server_group
应用层检测
应用层检测:http:HTTP_GET;https:SSL_GET
示例文件:/usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.HTTP_GET.port/usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.SSL_GET
HTTP_GET|SSL_GET {
url {
path <URL_PATH> # 定义要监控的URL
status_code <INT> # 判断上述检测机制为健康状态的响应码,一般为 200
}
connect_timeout <INTEGER> # 客户端请求的超时时长, 相当于haproxy的timeout server
nb_get_retry <INT> # 重试次数
delay_before_retry <INT> # 重试之前的延迟时长
connect_ip <IP ADDRESS> # 向当前RS哪个IP地址发起健康状态检测请求
connect_port <PORT> # 向当前RS的哪个PORT发起健康状态检测请求
bindto <IP ADDRESS> # 向当前RS发出健康状态检测请求时使用的源地址
bind_port <PORT> # 向当前RS发出健康状态检测请求时使用的源端口
}范例:
virtual_server 10.0.0.10 80 {
delay_loop 3
lb_algo rr
lb_kind DR
protocol TCP
sorry_server 127.0.0.1 80
real_server 10.0.0.7 80 {
weight 1
HTTP_GET {
url {
path /monitor.html
status_code 200
}
connect_timeout 1
nb_get_retry 3
delay_before_retry 1
}
}
real_server 10.0.0.17 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 1
nb_get_retry 3
delay_before_retry 1
}
}
}TCP 检测
传输层检测:TCP_CHECK
TCP_CHECK {
connect_ip <IP ADDRESS> # 向当前RS的哪个IP地址发起健康状态检测请求
connect_port <PORT> # 向当前RS的哪个PORT发起健康状态检测请求
bindto <IP ADDRESS> # 发出健康状态检测请求时使用的源地址
bind_port <PORT> # 发出健康状态检测请求时使用的源端口
connect_timeout <INTEGER> # 客户端请求的超时时长, 等于haproxy的timeout server
}范例:
virtual_server 10.0.0.10 80 {
delay_loop 6
lb_algo wrr
lb_kind DR
#persistence_timeout 120 #会话保持时间
protocol TCP
sorry_server 127.0.0.1 80
real_server 10.0.0.7 80 {
weight 1
TCP_CHECK {
connect_timeout 5
nb_get_retry 3
delay_before_retry 3
connect_port 80
}
}
real_server 10.0.0.17 80 {
weight 1
TCP_CHECK {
connect_timeout 5
nb_get_retry 3
delay_before_retry 3
connect_port 80
}
}
}案例
实现单主的 LVS-DR 模式
实现双主的 LVS-DR 模式
实现单主的 LVS-DR,实现单主的 LVS-DR 模式,利用 FWM 绑定成多个服务为一个集群服务
实现其他应用的高可用性 VRRP Script
示例文件:/usr/share/doc/keepalived-1.3.5/samples/keepalived.conf.vrrp.localcheck
调用外部的辅助性脚本进行资源监控,并根据监控的结果实现优先动态调整,从而实现其他应用的高可用性功能
vrrp_script
自定义资源监控脚本,一般放在 gloal_defs 设置块之后
vrrp_script <SCRIPT_NAME> {
script <STRING>|<QUOTED-STRING> # shell命令或脚本路径,返回值为0即检测成功
interval <INTEGER> # 间隔时间,单位为秒,默认1秒
timeout <INTEGER> # 超时时间
weight <INTEGER:-254..254> # 权重,配合vrrp_instance的priority调整vrrp实例的优先级:当设置为负数,如果标记KO,vrrp_instance的优先级=priority+weight,优先级降低;当设置为正数,如果标记KO,vrrp_instance的优先级=priority+weight,优先级提高;默认为0,通常使用负值。
fall <INTEGER> # 脚本几次失败就标记KO,建议设为2以上
rise <INTEGER> # 脚本连续监测成功几次,就标记OK
user USERNAME [GROUPNAME] # 执行监测脚本的用户或组
init_fail # 设置默认标记为失败状态,监测成功之后再转换为成功状态
}track_script
调用脚本,调用 vrrp_script 定义的脚本去监控资源,定义在 vrrp 实例内
vrrp_instance VI_1 {
...
track_script {
SCRIPT_NAME
}
}示例:利用脚本实现主从角色切换
两台服务器:10.0.0.71、10.0.0.72
一个 VIP:10.0.0.100/24
# 10.0.0.71
global_defs {
notification_email {
441757636@qq.com
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id c71 # 10.0.0.72设置为c72
vrrp_skip_check_adv_addr
# vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.0.18
}
vrrp_script check_down {
script "[ ! -f /etc/keepalived/down ]" # /etc/keepalived/down存在时返回非0,触发权重-30
interval 1 # 每秒执行一次script
weight -30
fall 3 # 当script执行三次失败,priority = 100 - 30
rise 2
timeout 2
}
vrrp_instance VI_1 {
state MASTER # 10.0.0.72设置为BACKUP
interface eth0
virtual_router_id 1
priority 100 # 10.0.0.72设置为80
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
10.0.0.100/24 dev eth0 label eth0:1
}
track_interface {
eth0
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
track_script {
check_down # 调用前面定义的脚本
}
}示例:实现单主模式的 Nginx 反向代理的高可用
示例:实现双主模式 Nginx 反向代理的高可用
实现 HAProxy 高可用
示例:实现 MySQL 双主模式的高可用
同步组
LVS NAT 模型 VIP 和 DIP 需要同步,需要同步组
vrrp_sync_group VG_1 {
group {
VI_1 # name of vrrp_instance (below)
VI_2 # One for each moveable IP
}
}
vrrp_instance VI_1 {
eth0
vip
}
vrrp_instance VI_2 {
eth1
dip
}综合实战案例
Keepalived + LVS
- 编译安装 keepalived
- 实现 keepalived(20 个以上的 VIP) + Nginx 双主高可用
- 实现 keepalived(60 个以上的 VIP) + HAProxy 三服务器高可用
- 实现 keepalived(100 个以上的 VIP) + LVS 高可用、Real Server 状态监测及规则管理
Keepalived + HAProxy

- 编译安装 HAProxy 较新 LTS 版本,选择编译安装 keepalived
- 开启 HAProxy 多进程,进程数与 CPU 核心数保持一致并实现 HAProxy 进程绑定
- 因业务较多避免配置文件误操作,需要按每业务一个配置文件并统一保存至/etc/haproxy/conf 目录中
- 实现 keepalived include 导入配置文件功能,使用 LVS-DR 模型代理后端 Nginx web 服务器
- 基于 ACL 实现单 IP 多域名负载功能(适用于企业较少公网 IP 多域名场景)
- 实现 MySQL 主从复制,并通过 HAProxy 对 MySQL 进行反向代理
- 最终完成 HAProxy+Nginx+Tomcat+ Redis,并实现 session 会话保持统一保存到 Redis
HAProxy 的 frontend 的 bind 绑定 Keepalived 的 VIP
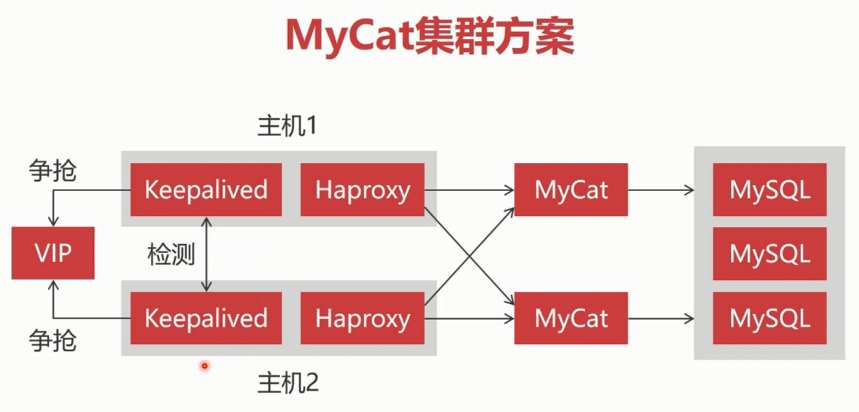
MyCAT 集群方案