文本处理相关命令
本文最后更新于:2023年12月5日 晚上
cat
如果没有指定文件,或者指定文件为 “-”,则从标准输入读取
-n # 对输出内容标行号
-b # 对输出内容非空行标行号
-E # 显示行结束符$
-A # 显示所有控制符
-s # 压缩连续的空行成一行nl
相当于 cat -b
tac
cat 倒着写 tac,功能也是恰如其名:逆向显示文本内容
tr
translate,转换、删除、去重标准输入中的字符,将结果写入到标准输出
tr [OPTION]... SET1 [SET2]
-d # 删除
-c # 取补集
-s # 对set1进行去重操作
-t # 将第一个字符集对应字符转化为第二字符集对应的字符
-c # 取字符集的补集tr 类似于 sed 命令,但是比 sed 简单,所有 tr 能实现的功能,sed 都能实现
示例:
# 将a换成b
$tr a b
# 生成8位随机数
$ cat /dev/urandom | tr -dc A-Za-z0-9 | head -c8
1imvyPoH
# 将a.log中大写输出为小写
$ cat a.log
HELLO WORD
$ tr A-z a-z <a.log
hello word-
重定向有时会使用 - 符号,重定向到标准输出
rev
将每行的内容逆向显示
head
-c #指定前几个字符
-n #指定前几行,当n是负数(-#),表示舍弃最后#行tail
-f #将文件尾部内容显示在终端,并不断刷新,常用于观察实时日志
-c #指定后几个字符
-n #指定后几行,当n是显示整数(+#),表示从第#行开始到结束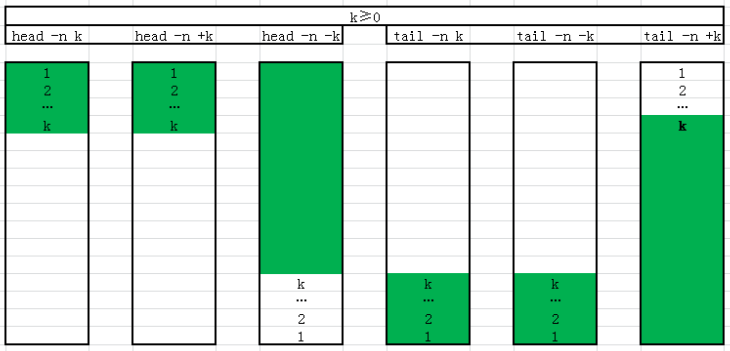
less 和 more
分页查看文件内容
一般搭配管道符使用,less 和 more 差不多,区别在于 more 只能向下翻页
hexdump、od、xxd
查看非文本内容
最常的是 hexdump,常用选项 -C
cut
提取文本文件或 STDIN 数据的指定列
cut [OPTION]... [FILE]...
-d delimiter #指明分隔符
-f fileds
n #第n个字段, 例如: 3
n,n[,n] #离散的多个字段, 例如: 1,3,6
n-n #连续的多个字段, 例如: 1-6
混合使用: 1-3,7
-c #按字符切割
--output-delimiter #指定输出分隔符[19:22:09 root@centos7 data]#cut -d : -f1-3 --output-delimiter=. passwd
root.x.0
bin.x.1
daemon.x.2
adm.x.3
lp.x.4
sync.x.5
shutdown.x.6
halt.x.7
mail.x.8
operator.x.11
games.x.12
ftp.x.14
nobody.x.99
systemd-network.x.192
dbus.x.81
polkitd.x.999
sshd.x.74
postfix.x.89
lujinkai.x.1000
test.x.1001
test2.x.1002
gentoo.x.1003
tomcat.x.1004
mysql.x.1005
[14:49:02 root@centos7 data]#cut -c1-3 passwd
roo
bin
dae
adm
lp:
syn
shu
hal
mai
ope
gam
ftp
nob
sys
dbu
pol
ssh
pos
luj
tes
tes
gen
tom
myspaste
合并多个文件,合并多个文件同行号的列到一行
paste [OPTION]... [FILE]...
-d #分隔符, 指定分隔符, 默认分隔符TAB
-s #所有行合成一行显示wc
文本统计,用于统计文件或 STDIN 的行总数、单词总数、字节总数和字符总数
-l #统计行数
-w #统计单词数 (规则是有空格或者换行分隔才是单词)
-m #打印字符数 (空格和换行和tab都是字符)
-L #统计文件中最长行的长度sort
字典排序, 从小到大
-r #反方向
-R #随机排序
-n #自然排序
-h #人类可读排序, 如: 2k 1G
-f #忽略大小写
-u #合并重复项, 即去重
-t #指定字段界定符
-k #配合-t使用, 指定使用第几个字符来排序示例:按照 UID 进行排序
[21:18:38 root@centos7 data]#cat /etc/passwd | sort -n -t: -k 3
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
lujinkai:x:1000:1000:lujinkai:/home/lujinkai:/bin/bash
test:x:1001:1001::/home/test:/bin/bash
test2:x:1002:1002::/home/test2:/bin/bash
gentoo:x:1003:1003:Gentoo Distribution:/home/gentoo:/bin/csh
tomcat:x:1004:1006::/home/tomcat:/sbin/nologin
mysql:x:1005:1009::/home/mysql:/bin/bashuniq
去重,从输入中删除前后相接的重复的行
uniq [OPTION]... [FILE]...
-c # 显示每行重复出现的次数, 重复的行必须相邻, 否则会单独统计
-d # 仅显示重复的行
-u # 仅显示不重复的行uniq 常和 sort 命令一起配合使用
sort userlist.txt | uniq -cdiff 和 path
比较文本
diff
diff 命令比较两个文件之间的区别
常用选项 -u
patch
复制在其他文件中进行的改变 (要谨慎使用)
diff -u foo.conf foo2.conf > foo.patch
patch -b foo.conf foo.patchcmp
比较二进制文件,查看二进制文件的不同
练习
1、找出 ifconfig “网卡名” 命令结果中本机的 IPv4 地址
[root@47105171233 wwwlogs]# cut -d' ' -f1 lujinkai.cn_nginx.log | sort -t' ' -k1 | uniq -c | sort -nr | head -n10
276 112.64.64.36
186 183.136.190.62
184 112.64.64.47
184 112.64.64.40
184 112.64.64.33
121 176.9.32.203
94 47.92.207.41
92 112.64.64.43
92 112.64.64.39
92 112.64.64.352、查出分区空间使用率的最大百分比值
3、查出用户 UID 最大值的用户名、UID 及 shell 类型
4、查出/tmp 的权限,以数字方式显示
5、统计当前连接本机的每个远程主机 IP 的连接数,并按从大到小排序
文本处理相关命令
http://blog.lujinkai.cn/运维/基础/文本处理/文本处理相关命令/