Redis
本文最后更新于:2023年12月5日 晚上
缓存技术
缓存 cache
buffer 和 cache
- buffer:缓冲,写缓冲,先写到缓冲中,再输出到网络或者写入磁盘
- cache:缓存
缓存保存位置及分层结构
互联网领域,缓存为王
- 用户层:浏览器 DNS 缓存,应用程序 DNS 缓存,操作系统 DNS 缓存客户端
- 代理层:CDN,反向代理缓存
- Web 层:解释器 Opcache,Web 服务器缓存
- 应用层:页面静态化
- 数据层:分布式缓存,数据库
- 系统层:操作系统 cache
- 物理层:磁盘 cache, Raid Cache
cache 的特性
自动过期、强制过期、命中率
CDN
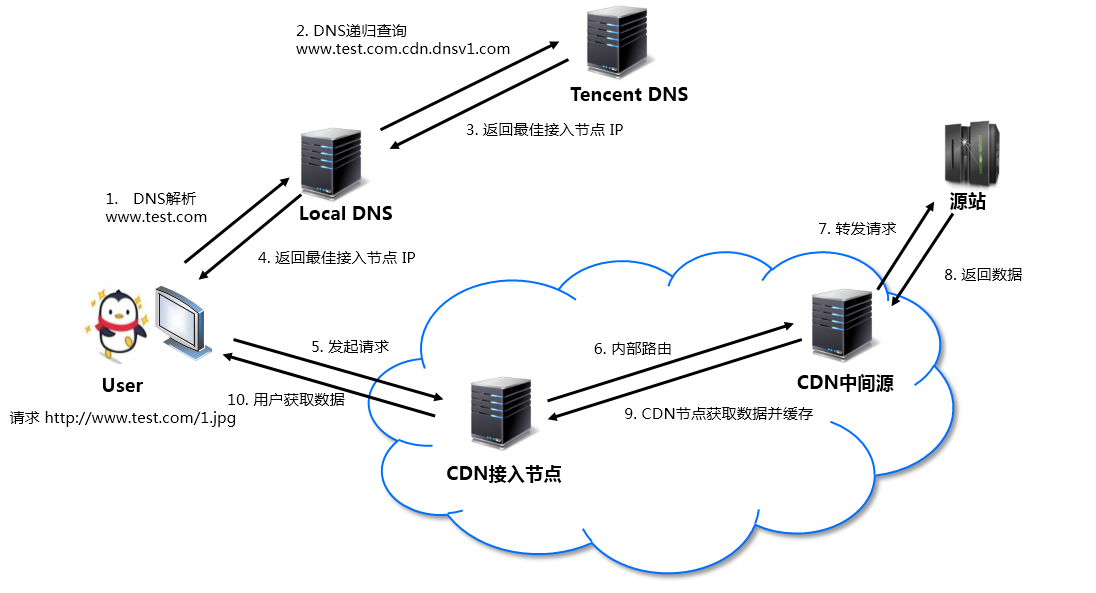
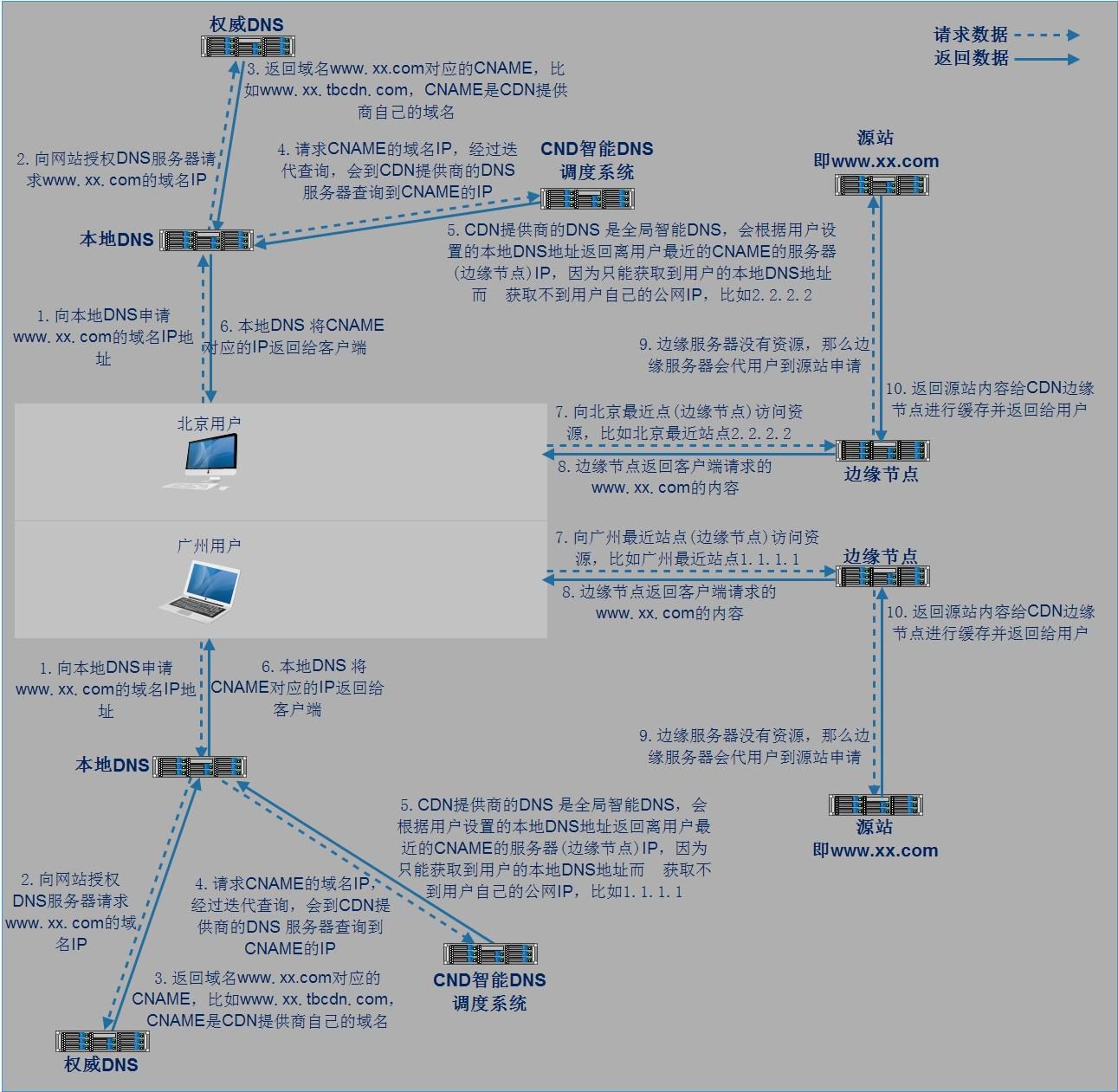
利用 302 实现转发请求重定向至最优服务器集群
中国网络较为复杂,依赖 DNS 就近解析的调度,仍然会存在部分请求调度失效、调度生效慢等问题。腾讯云利用在全国部署的 302 重定向服务器集群,能够为每一个请求实时决策最优的服务器资源,精准解决小运营商的调度问题,提升用户访问质量, 能最快地把用户引导到最优的服务器节点上,避开性能差或者异常的节点。

CDN 分层缓存

Redis 部署和使用
Redis 基础
注意事项:谨慎甚至禁止使用某些命令,例如 keys
redis 对比 memcached
- 支持数据的持久化:可以将内存中的数据保持在磁盘中,重启 redis 服务或者服务器之后可以从备份文件中恢复数据到内存继续使用
- 支持更多的数据类型:支持 string(字符串)、hash(哈希数据)、list(列表)、set(集合)、zset(有序集合)
- 支持数据的备份:可以实现类似于数据的 master-slave 模式的数据备份,另外也支持使用快照+AOF
- 支持更大的 value 数据:memcache 单个 key value 最大只支持 1MB,而 redis 最大支持 512MB(生产不建议超过 2M,性能受影响)
- 在 Redis6 版本前,Redis 是单线程,而 memcached 是多线程,所以单机情况下没有 memcached 并发高,性能更好,但 redis 支持分布式集群以实现更高的并发,单 Redis 实例可以实现数万并发
- 支持集群横向扩展:基于 redis cluster 的横向扩展,可以实现分布式集群,大幅提升性能和数据安全性
- 都是基于 C 语言开发
redis 典型应用场景
- Session 共享:常见于 web 集群中的 Tomcat 或者 PHP 中多 web 服务器 session 共享
- 缓存:数据查询、电商网站商品信息、新闻内容
- 计数器:访问排行榜、商品浏览数等和次数相关的数值统计场景
- 微博/微信社交场合:共同好友,粉丝数,关注,点赞评论等
- 消息队列:ELK 的日志缓存、部分业务的订阅发布系统
- 地理位置: 基于 GEO(地理信息定位),实现摇一摇,附近的人,外卖等功能
Redis 安装及连接
编译安装
见脚本,注意 redis 不建议设置密码
解决启动时的三个警告提示
tcp-backlog
#vim /etc/sysctl.conf net.core.somaxconn = 1024 #sysctl -pvm.overcommit_memory
# 0、表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。 # 1、表示内核允许分配所有的物理内存,而不管当前的内存状态如何 # 2、表示内核允许分配超过所有物理内存和交换空间总和的内存 # 范例: #vim /etc/sysctl.conf vm.overcommit_memory = 1 #sysctl -ptransparent hugepage
# 警告:您在内核中启用了透明大页面(THP,不同于一般内存页的4k为2M)支持。 这将在Redis中造成延迟和内存使用问题。 要解决此问题,请以root 用户身份运行命令“echo never> /sys/kernel/mm/transparent_hugepage/enabled”,并将其添加到您的/etc/rc.local中,以便在重启后保留设置。禁用THP后,必须重新启动Redis。 echo 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' >> /etc/rc.d/rc.local
Redis 配置和优化
主要配置项
# 绑定网卡,监听地址,可以用空格隔开后多个监听IP
bind 0.0.0.0
# redis3.2之后加入的新特性,在没有设置bind IP和密码的时候,redis只允许访问127.0.0.1:6379,可以远程连接,但当访问将提示警告信息并拒绝远程访问
protected-mode yes
# 监听端口,默认6379/tcp
port 6379
# 三次握手的时候server端收到client ack确认号之后的队列值,即全连接队列长度
tcp-backlog 511
# 客户端和Redis服务端的连接超时时间,默认是0,表示永不超时
timeout 0
# tcp 会话保持时间300s
tcp-keepalive 300
# 默认no,即直接运行redis-server程序时,不作为守护进程运行,而是以前台方式运行,如果想在后台运行需改成yes,当redis作为守护进程运行的时候,它会写一个pid 到/var/run/redis.pid 文件
daemonize no
# 和OS相关参数,可设置通过upstart和systemd管理Redis守护进程,centos7后都使用systemd
supervised no
# pid文件路径
pidfile /var/run/redis_6379.pid
# 日志级别
loglevel notice
# 日志路径,示例:logfile "/apps/redis/log/redis_6379.log"
logfile "/path/redis.log"
# 设置数据库数量,默认:0-15,共16个库
databases 16
# 在启动redis时是否显示或在日志中记录记录redis的logo
always-show-logo yes
# 在900秒内有1个key内容发生更改,就执行快照机制
save 900 1
# 在300秒内有10个key内容发生更改,就执行快照机制
save 300 10
# 60秒内如果有10000个key以上的变化,就自动快照备份
save 60 10000
# 默认为yes时,可能会因空间满等原因快照无法保存出错时,会禁止redis写入操作,生产建议为no
# 此项只针对配置文件中的自动save有效
stop-writes-on-bgsave-error yes
# 持久化到RDB文件时,是否压缩,"yes"为压缩,"no"则反之
rdbcompression yes
# 是否对备份文件开启RC64校验,默认是开启
rdbchecksum yes
# 快照文件名
dbfilename dump.rdb
# 快照文件保存路径,示例:dir "/apps/redis/data"
dir ./
#主从复制相关
# replicaof <masterip> <masterport> # 指定复制的master主机地址和端口,5.0版之前的指令为slaveof
# masterauth <master-password> # 指定复制的master主机的密码
# 当从库同主库失去连接或者复制正在进行,从机库有两种运行方式:
# 1、设置为yes(默认设置),从库会继续响应客户端的读请求,此为建议值
# 2、设置为no,除去特定命令外的任何请求都会返回一个错误"SYNC with master in progress"。
replica-serve-stale-data yes
# 是否设置从库只读,建议值为yes,否则主库同步从库时可能会覆盖数据,造成数据丢失
replica-read-only yes
# 是否使用socket方式复制数据(无盘同步),新slave第一次连接master时需要做数据的全量同步,redis server就要从内存dump出新的RDB文件,然后从master传到slave,有两种方式把RDB文件传输给客户端:
# 1、基于硬盘(disk-backed):为no时,master创建一个新进程dump生成RDB磁盘文件,RDB完成之后由父进程(即主进程)将RDB文件发送给slaves,此为默认值
# 2、基于socket(diskless):master创建一个新进程直接dump RDB至slave的网络socket,不经过主进程和硬盘
# 推荐使用基于硬盘(为no),是因为RDB文件创建后,可以同时传输给更多的slave,但是基于socket(为yes),新slave连接到master之后得逐个同步数据。只有当磁盘I/O较慢且网络较快时,可用diskless(yes),否则一般建议使用磁盘(no)
repl-diskless-sync no
# diskless时复制的服务器等待的延迟时间,设置0为关闭,在延迟时间内到达的客户端,会一起通过diskless方式同步数据,但是一旦复制开始,master节点不会再接收新slave的复制请求,直到下一次同步开始才再接收新请求。即无法为延迟时间后到达的新副本提供服务,新副本将排队等待下一次RDB传输,因此服务器会等待一段时间才能让更多副本到达。推荐值:30-60
repl-diskless-sync-delay 5
# slave根据master指定的时间进行周期性的PING master,用于监测master状态,默认10s
repl-ping-replica-period 10
# 复制连接的超时时间,需要大于repl-ping-slave-period,否则会经常报超时
repl-timeout 60
# 是否在slave套接字发送SYNC之后禁用TCP_NODELAY,如果选择"yes",Redis将合并多个报文为一个大的报文,从而使用更少数量的包向slaves发送数据,但是将使数据传输到slave上有延迟,Linux内核的默认配置会达到40毫秒,如果 "no" ,数据传输到slave的延迟将会减少,但要使用更多的带宽
repl-disable-tcp-nodelay no
# 复制缓冲区内存大小,当slave断开连接一段时间后,该缓冲区会累积复制副本数据,因此当slave重新连接时,通常不需要完全重新同步,只需传递在副本中的断开连接后没有同步的部分数据即可。只有在至少有一个slave连接之后才分配此内存空间,建议建立主从时此值要调大一些或在低峰期配置,否则会导致同步到slave失败
repl-backlog-size 512mb
# 多长时间内master没有slave连接,就清空backlog缓冲区
repl-backlog-ttl 3600
# 当master不可用,哨兵Sentinel会根据slave的优先级选举一个master,此值最低的slave会优先当选master,而配置成0,永远不会被选举,一般多个slave都设为一样的值,让其自动选择
replica-priority 100
# 至少有3个可连接的slave,mater才接受写操作
min-replicas-to-write 3
# 和上面至少3个slave的ping延迟不能超过10秒,否则master也将停止写操作
min-replicas-max-lag 10
# 设置redis连接密码,之后需要AUTH pass,如果有特殊符号,用" "引起来,生产建议设置
requirepass foobared
# 重命名一些高危命令,示例:rename-command FLUSHALL "" 禁用命令
# rename-command del magedu
rename-command CONFIG ""
# Redis最大连接客户端
maxclients 10000
# redis使用的最大内存,单位为bytes字节,0为不限制,建议设为物理内存一半,8G内存的计算方式8(G)*1024(MB)1024(KB)*1024(Kbyte),需要注意的是缓冲区是不计算在maxmemory内,生产中如果不设置此项,可能会导致OOM
maxmemory <bytes>
# 是否开启AOF日志记录,默认redis使用的是rdb方式持久化,这种方式在许多应用中已经足够用了,但是redis如果中途宕机,会导致可能有几分钟的数据丢失(取决于dump数据的间隔时间),根据save来策略进行持久化,Append Only File是另一种持久化方式,可以提供更好的持久化特性,Redis会把每次写入的数据在接收后都写入 appendonly.aof 文件,每次启动时Redis都会先把这个文件的数据读入内存里,先忽略RDB文件。默认不启用此功能
appendonly no
# 文本文件AOF的文件名,存放在dir指令指定的目录中
appendfilename "appendonly.aof"
# aof持久化策略的配置
# no表示由操作系统保证数据同步到磁盘,Linux的默认fsync策略是30秒,最多会丢失30s的数据
# always表示每次写入都执行fsync,以保证数据同步到磁盘,安全性高,性能较差
# everysec表示每秒执行一次fsync,可能会导致丢失这1s数据,此为默认值,也生产建议值
appendfsync everysec
# 同时在执行bgrewriteaof操作和主进程写aof文件的操作,两者都会操作磁盘,而bgrewriteaof往往会涉及大量磁盘操作,这样就会造成主进程在写aof文件的时候出现阻塞的情形,以下参数实现控制
# 在aof rewrite期间,是否对aof新记录的append暂缓使用文件同步策略,主要考虑磁盘IO开支和请求阻塞时间。
# no:默认设置,表示"不暂缓",新aof记录仍然被立即同步到磁盘,是最安全的方式,不丢失数据,但要忍受阻塞的问题
# yes:相当于将appendfsync设置为no,这说明并没有执行磁盘操作,只是写入了缓冲区,因此这样并不会造成阻塞(因为没有竞争磁盘),但是如果这个时候redis挂掉,就会丢失数据。丢失多少数据呢?Linux的默认fsync策略是30秒,最多会丢失30s的数据,但由于yes性能较好而且会避免出现阻塞,因此比较推荐
# rewrite 即对aof文件进行整理,将空闲空间回收,从而可以减少恢复数据时间
no-appendfsync-on-rewrite no
# 当Aof log增长超过指定百分比例时,重写AOF文件,设置为0表示不自动重写Aof日志,重写是为了使aof体积保持最小,但是还可以确保保存最完整的数据
auto-aof-rewrite-percentage 100
# 触发aof rewrite的最小文件大小
auto-aof-rewrite-min-size 64mb
# 是否加载由于某些原因导致的末尾异常的AOF文件(主进程被kill/断电等),建议yes
aof-load-truncated yes
# redis4.0新增RDB-AOF混合持久化格式,在开启了这个功能之后,AOF重写产生的文件将同时包含RDB格式的内容和AOF格式的内容,其中RDB格式的内容用于记录已有的数据,而AOF格式的内容则用于记录最近发生了变化的数据,这样Redis就可以同时兼有RDB持久化和AOF持久化的优点(既能够快速地生成重写文件,也能够在出现问题时,快速地载入数据),默认为no,即不启用此功能
aof-use-rdb-preamble no
# lua脚本的最大执行时间,单位为毫秒
lua-time-limit 5000
# 是否开启集群模式,默认不开启,即单机模式
cluster-enabled yes
# 由node节点自动生成的集群配置文件名称
cluster-config-file nodes-6379.conf
# 集群中node节点连接超时时间,单位ms,超过此时间,会踢出集群
cluster-node-timeout 15000
# 单位为次,在执行故障转移的时候可能有些节点和master断开一段时间导致数据比较旧,这些节点就不适用于选举为master,超过这个时间的就不会被进行故障转移,不能当选master,计算公式:(node-timeout * replica-validity-factor) + repl-ping-replica-period
cluster-replica-validity-factor 10
# 集群迁移屏障,一个主节点至少拥有1个正常工作的从节点,即如果主节点的slave节点故障后会将多余的从节点分配到当前主节点成为其新的从节点
cluster-migration-barrier 1
# 集群请求槽位全部覆盖,如果一个主库宕机且没有备库就会出现集群槽位不全,那么yes时redis集群槽位验证不全,就不再对外提供服务(对key赋值时,会出现CLUSTERDOWN The cluster is down的提示,cluster_state:fail,但ping 仍PONG),而no则可以继续使用,但是会出现查询数据查不到的情况(因为有数据丢失)。生产建议为no
cluster-require-full-coverage yes
# 如果为yes,此选项阻止在主服务器发生故障时尝试对其主服务器进行故障转移。 但是,主服务器仍然可以执行手动强制故障转移,一般为no
cluster-replica-no-failover no
# Slow log 是 Redis 用来记录超过指定执行时间的日志系统,执行时间不包括与客户端交谈,发送回复等I/O操作,而是实际执行命令所需的时间(在该阶段线程被阻塞并且不能同时为其它请求提供服务),由于slow log 保存在内存里面,读写速度非常快,因此可放心地使用,不必担心因为开启 slow log 而影响Redis 的速度
# 以微秒为单位的慢日志记录,为负数会禁用慢日志,为0会记录每个命令操作。默认值为10ms,一般一条命令执行都在微秒级,生产建议设为1ms-10ms之间
slowlog-log-slower-than 10000
# 最多记录多少条慢日志的保存队列长度,达到此长度后,记录新命令会将最旧的命令从命令队列中删除,以此滚动删除,即,先进先出,队列固定长度,默认128,值偏小,生产建议设为1000以上
slowlog-max-len 128动态修改配置
config 命令用于查看当前 redis 配置、以及不重启 redis 服务实现动态更改 redis 配置等
注意:不是所有配置都可以动态修改,且此方式无法持久保存
获取当前配置
# 奇数行为键,偶数行为值 127.0.0.1:6379> config get * 1) "dbfilename" 2) "dump.rdb" 3) "requirepass" 4) "" 5) "masterauth" 6) "" 7) "cluster-announce-ip" 8) "" 9) "unixsocket" 10) "" 11) "logfile" 12) "/var/log/redis/redis.log" 13) "pidfile" 14) "/var/run/redis_6379.pid" 15) "slave-announce-ip" 16) "" 17) "replica-announce-ip" 18) "" 19) "maxmemory" 20) "0" ...... # 查看bind 127.0.0.1:6379> config get bind 1) "bind" 2) "0.0.0.0" # 有些设置无法修改 127.0.0.1:6379> CONFIG SET bind 127.0.0.1 (error) ERR Unsupported CONFIG parameter: bind设置连接密码
# 设置连接密码 127.0.0.1:6379> CONFIG SET requirepass 123456 OK # 查看连接密码 127.0.0.1:6379> CONFIG GET requirepass 1) "requirepass" 2) "123456"更改最大内存
127.0.0.1:6379> CONFIG SET maxmemory 8589934592 OK 127.0.0.1:6379> CONFIG GET maxmemory 1) "maxmemory" 2) "8589934592"
慢查询

slowlog-log-slower-than 10000
slowlog-max-len 1024127.0.0.1:6379> SLOWLOG LEN # 查看慢日志的记录条数
127.0.0.1:6379> SLOWLOG GET [n] # 查看慢日志的n条记录
127.0.0.1:6379> SLOWLOG RESET # 清空慢日志持久化
目前 redis 支持两种不同方式的数据持久化保存机制,分别是 RDB 和 AOF
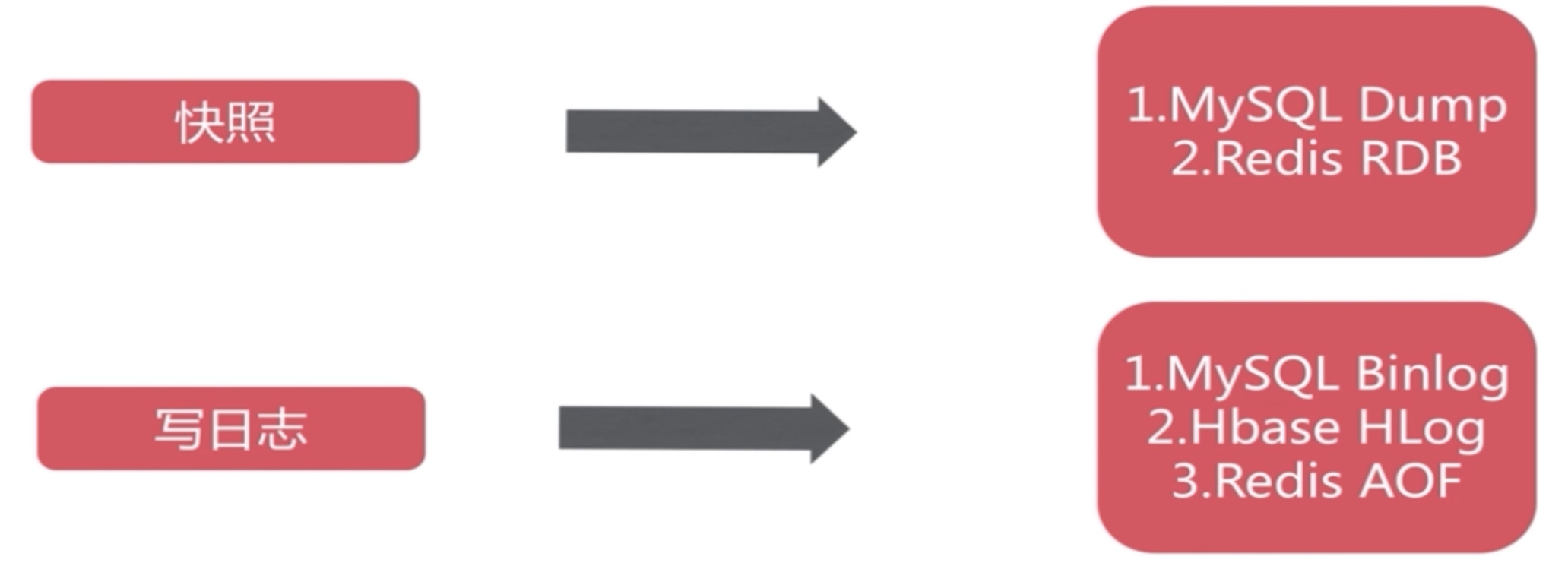
RDB 模式
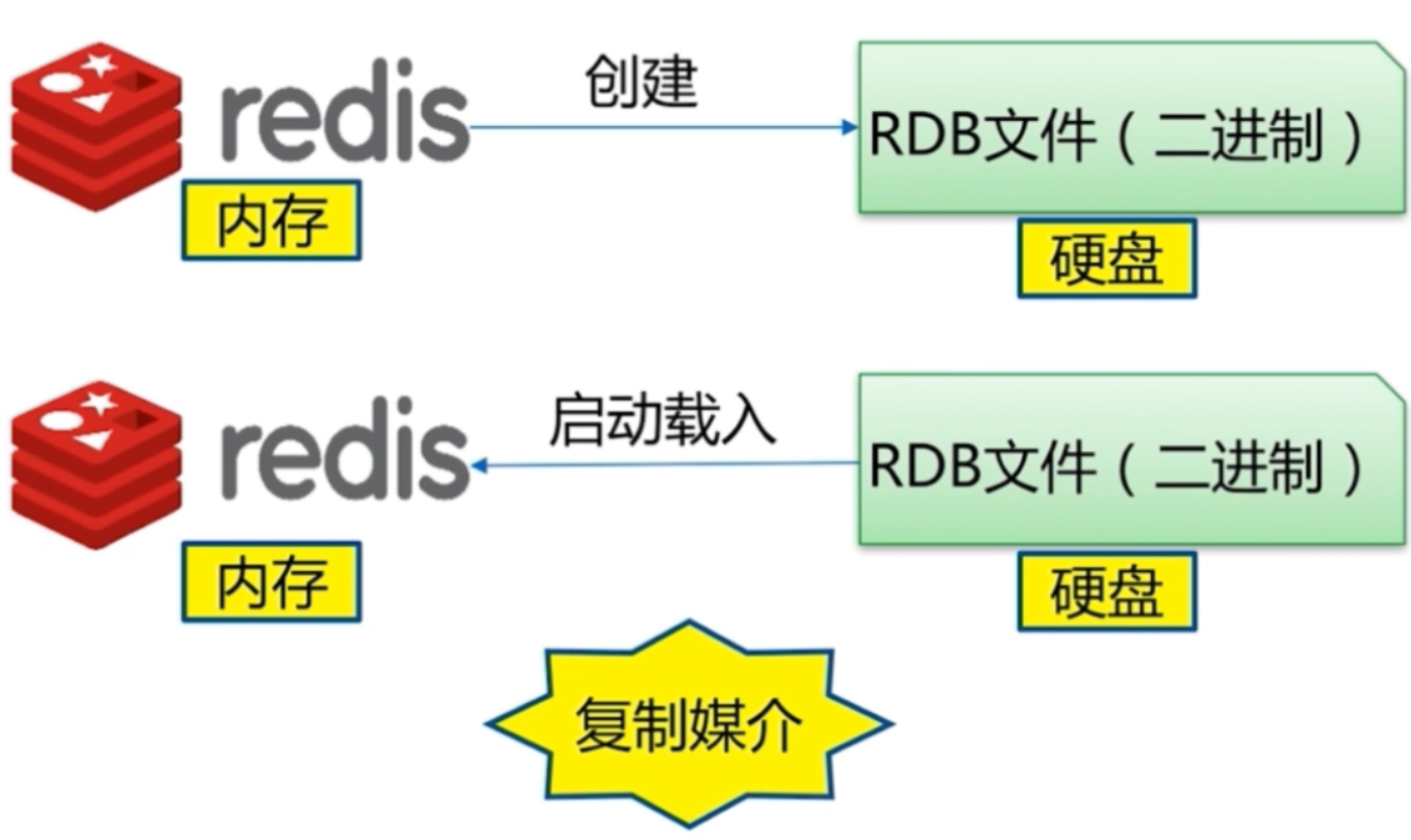
基于时间的快照,其默认只保留当前最新的一次快照,特点是执行速度比较快,缺点是可能会丢失从上次快照到当前时间点之间未做快照的数据
- save: 同步,会阻赛其它命令,不推荐使用
- bgsave: 异步后台执行,不影响其它命令的执行
- 自动: 制定规则,自动执行
bgsave 过程:Redis 从 master 主进程先 fork 出一个子进程,使用写时复制(copy-on-write)机制,子进程将内存的数据保存为一个临时文件,比如:tmp-.rdb,当数据保存完成之后再将上一次保存的 RDB 文件替换掉,然后关闭子进程,这样可以保证每一次做 RDB 快照保存的数据都是完整的
因为直接替换 RDB 文件的时候,可能会出现突然断电等问题,而导致 RDB 文件还没有保存完整就因为突然关机停止保存,而导致数据丢失的情况.后续可以手动将每次生成的 RDB 文件进行备份,这样可以最大化保存历史数据
save 900 1
save 300 10
save 60 10000
dbfilename dump.rdb
dir ./
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yesRDB 模式的优缺点
优点:
- RDB 快照保存了某个时间点的数据,可以通过脚本执行 redis 指令 bgsave(非阻塞,后台执行)或者 save(会阻塞写操作,不推荐)命令自定义时间点备份,可以保留多个备份,当出现问题可以恢复到不同时间点的版本,很适合备份,并且此文件格式也支持有不少第三方工具可以进行后续的数据分析
比如: 可以在最近的 24 小时内,每小时备份一次 RDB 文件,并且在每个月的每一天,也备份一个 ROB 文件。这样的话,即使遇上问题,也可以随时将数据集还原到不同的版本。 - RDB 可以最大化 Redis 的性能,父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后
这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘工/0 操作。 - RDB 在大量数据,比如几个 G 的数据,恢复的速度比 AOF 的快
缺点:
- 不能实时保存数据,可能会丢失自上一次执行 RDB 备份到当前的内存数据
如果你需要尽量避免在服务器故障时丢失数据,那么 RDB 不适合你。虽然 Redis 允许你设置不同的保存点(save point)来控制保存 RDB 文件的频率,但是,因为 ROB 文件需要保存整个数据集的状态,所以它并不是一个轻松的操作。因此你可能会至少 5 分钟才保存一次 RDB 文件。在这种情况下,一旦发生故障停机,你就可能会丢失好几分钟的数据 - 当数据量非常大的时候,从父进程 fork 子进程进行保存至 RDB 文件时需要一点时间,可能是毫秒或者秒,取决于磁盘 IO 性能
在数据集比较庞大时,fork()可能会非常耗时,造成服务器在一定时间内停止处理客户端﹔如果数据集非常巨大,并且 CPU 时间非常紧张的话,那么这种停止时间甚至可能会长达整整一秒或更久。虽然 AOF 重写也需要进行 fork(),但无论 AOF 重写的执行间隔有多长,数据的持久性都不会有任何损失
范例: 手动备份 RDB 文件的脚本
# 配置项
[root@centos7 ~]#vim /apps/redis/etc/redis.conf
save ""
dbfilename dump_6379.rdb
dir "/data/redis"
appendonly no
# 备份脚本
[root@centos8 ~]#cat redis_backup_rdb.sh
#!/bin/bash
. /etc/init.d/functions
BACKUP=/backup/redis-rdb
DIR=/data/redis
FILE=dump_6379.rdb
PASS=123456
redis-cli -h 127.0.0.1 -a $PASS --no-auth-warning bgsave
result=$(redis-cli -a 123456 --no-auth-warning info Persistence | grep rdb_bgsave_in_progress | sed -rn 's/.*:([0-9]+).*/\1/p')
until [ $result -eq 0 ]; do
sleep 1
result=$(redis-cli -a 123456 --no-auth-warning info Persistence | grep rdb_bgsave_in_progress | sed -rn 's/.*:([0-9]+).*/\1/p')
done
DATE=$(date +%F_%H-%M-%S)
[ -e $BACKUP ] || {
mkdir -p $BACKUP
chown -R redis.redis $BACKUP
}
mv $DIR/$FILE $BACKUP/dump_6379-${DATE}.rdb
action "Backup redis RDB"
# 执行
[root@centos8 ~]#bash redis_backup_rdb.sh
Background saving started
Backup redis RDB [ OK ]
[root@centos8 ~]#ll /backup/redis-rdb/ -h
total 143M
-rw-r--r-- 1 redis redis 143M Oct 21 11:08 dump_6379-2020-10-21_11-08-47.rdbAOF 模式

按照操作顺序依次将操作追加到指定的日志文件末尾
AOF 和 RDB 一样使用了写时复制机制,AOF 默认为每秒钟 fsync 一次,即将执行的命令保存到 AOF 文件当中,这样即使 redis 服务器发生故障的话最多只丢失 1 秒钟之内的数据,也可以设置不同的 fsync 策略 always,即设置每次执行命令的时候执行 fsync,fsync 会在后台执行线程,所以主线程可以继续处理用户的正常请求而不受到写入 AOF 文件的 I/O 影响
同时启用 RDB 和 AOF,进行恢复时,默认 AOF 文件优先级高于 RDB 文件,即会使用 AOF 文件进行恢复
注意:AOF 模式默认是关闭的,第一次开启 AOF 后,并重启服务,因为 AOF 的优先级高于 RDB,而 AOF 默认没有文件存在,从而导致所有数据丢失
AOF rewrite 重写
将一些重复的,可以合并的,过期的数据重新写入一个新的 AOF 文件,从而节约 AOF 备份占用的硬盘空间,也能加速恢复过程,可以手动执行 bgrewriteaof 触发 AOF 或定义自动 rewrite 策略
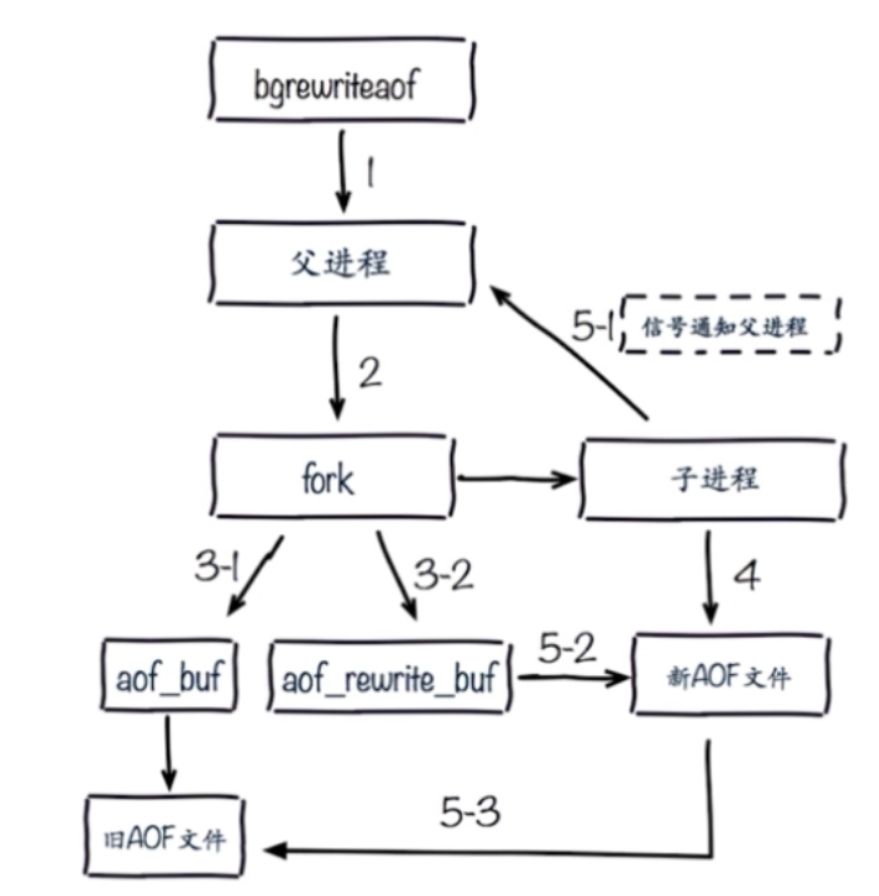
AOF 文件重写由 Redis 自行触发,我们可以使用 bgrewriteaof 命令手动触发
# 开启aof
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
dir ./
no-appendfsync-on-rewrite yes
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yesAOF 模式的优缺点
优点:
- 数据安全性相对较高,根据所使用的 fsync 策略(fsync 是同步内存中 redis 所有已经修改的文件到存储设备),默认是 appendfsync everysec,即每秒执行一次 fsync,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据(fsync 会在后台线程执行,所以主线程可以继续努力地处理命令请求)
- 由于该机制对日志文件的写入操作采用的是 append 模式,因此在写入过程中不需要 seek,即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在 Redis 下一次启动之前,可以通过 redis-check-aof 工具来解决数据一致性的问题
- AOF 文件体积变得过大时,可以自动在后台对 AOF 进行重写,重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,append 模式不断的将修改数据追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作
- AOF 包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,也可以通过该文件完成数据的重建
AOF 文件有序地保存了对数据库执行的所有写入操作,这些写入操作以 Redis 协议的格式保存,因此 AOF 文件的内容非常容易被人读懂,对文件进行分析(parse)也很轻松。导出(export)AOF 文件也非常简单,举个例子:如果你不小心执行了 FLUSHALL 命令,但只要 AOF 文件未被重写,那么只要停止服务器,移除 AOF 文件末尾的 FLUSHAL 命令,并重启 Redis,就可以将数据集恢复到 FLUSHALL 执行之前的状态
缺点:
- 即使有些操作是重复的也会全部记录,AOF 的文件大小要大于 RDB 格式的文件
- AOF 在恢复大数据集时的速度比 RDB 的恢复速度要慢
- 根据 fsync 策略不同,AOF 速度可能会慢于 RDB
- bug 出现的可能性更多
RDB 和 AOF 的选择
如果主要充当缓存功能,或者可以承受数分钟数据的丢失, 通常生产环境一般只需启用 RDB 即可,此也是默认值
如果数据需要持久保存,一点不能丢失,可以选择同时开启 RDB 和 AOF,一般不建议只开启 AOF
Redis 常用命令
- info:显示当前节点 redis 运行状态信息
- select:切换数据库,相当于在 MySQL 的 USE DBNAME 指令
- keys:查看当前库下的所有 key,慎用!可以考虑禁用
- bgsave:手动在后台执行 RDB 持久化操作
- dbsize:返回当前库下的所有 key 数量
- flushdb:强制清空当前库中的所有 key,慎用!可以考虑禁用
- flushall:强制清空当前 redis 服务器所有数据库中的所有 key,即删除所有数据,慎用!可以考虑禁用
- shutdown:安全关闭 redis
- 停止所有客户端
- 如果有至少一个保存点在等待,执行 SAVE 命令
- 如果 AOF 选项被打开,更新 AOF 文件
- 关闭 redis 服务器(server)
Redis 数据类型
- 字符串 string
- 列表 list
- 集合 set
- 有序集合 sorted set
- 哈希 hash
消息队列
消息队列主要分为两种,这两种模式 Redis 都支持
- 生产者/消费者模式
- 发布者/订阅者模式
生产者消费者模式
list
发布者模式
在发布者订阅者模式下,发布者将消息发布到指定的 channel 里面,凡是监听该 channel 的消费者都会收到同样的
- Publisher:发布者
- Subscriber:订阅者
- Channel:频道
127.0.0.1:6379> SUBSCRIBE channel1 # 订阅频道
127.0.0.1:6379> PUBLISH channel1 test1 # 发布消息,然后订阅者都能收到消息
127.0.0.1:6379> unsubscribe channel1 # 取消订阅Redis 高可用和集群
Redis 主从复制
实现
确保主从的配置文件(redis.conf)中 bind 设置为 0.0.0.0
从节点执行:
replicaof <masterip> <masterport>,例如REPLICAOF 10.0.0.72 6379或者直接修改配置文件,如果使用命令配置,建议也修改配置文件,否则重启会失效
INFO replication查看主从复制信息,REPLICAOF no one取消主从复制
如果设置了replica-read-only yes,则从节点只读,不能写
requirepass 和 masterauth:
- requirepass:针对客户端,对登录权限做限制,redis 每个节点的 requirepass 可以是独立的,不同的
- masterauth:master 设置,在 slave 节点数据库同步的时候用到
故障恢复
从节点故障:因为从节点只负责读,当从节点故障,修改代码,连接其他从节点即可
主节点故障:需要提升一个从节点为主节点,然后把其他从节点重新指向新的主节点
提升主节点:
# 10.0.0.18 127.0.0.1:6379> REPLICAOF NO ONE其他从节点重新指向新的主节点
127.0.0.1:6379> SLAVEOF 10.0.0.18 6379
优化
主从复制分为全量同步和增量同步,全量复制一般发生在 Slave 首次初始化阶段,这时 Slave 需要将 Master 上的所有数据都复制一份
# 复制缓冲区大小,建议要设置足够大
repl-backlog-size 1mb
# 当没有slave需要同步的时候,多久可以释放环形队列:
repl-backlog-ttl 3600避免全量复制:
- 第一次全量复制不可避免,后续的全量复制可以利用小主节点(内存小),业务低峰时进行全量
- 节点运行 ID 不匹配:主节点重启会导致 RUNID 变化,可能会触发全量复制,可以利用故障转移,例如哨兵或集群,而从节点重启动,避免导致全量复制
- 复制积压缓冲区不足:当主节点生成的新数据大于缓冲区大小,从节点恢复和主节点连接后,会导致全量复制。解决方法可以将 repl-backlog-size 调大
避免全量复制:
- 当主节点重启,多从节点复制
优化配置:
# 是否使用无盘同步RDB文件,默认为no,no为不使用无盘,需要将RDB文件保存到磁盘后再发送给slave,yes为支持无盘,支持无盘就是RDB文件不需要保存至本地磁盘,而且直接通过socket文件发送给slave
repl-diskless-sync no
# diskless时复制的服务器等待的延迟时间
repl-diskless-sync-delay 5
# slave端向server端发送ping的时间间隔,默认为10秒
repl-ping-slave-period 10
# 设置主从ping连接超时时间,超过此值无法连接,master_link_status显示为down,并记录错误日志
repl-timeout 60
# 是否启用TCP_NODELAY,如设置成yes,则redis会合并小的TCP包从而节省带宽, 但会增加同步延迟(40ms),造成master与slave数据不一致,假如设置成no,则redismaster会立即发送同步数据,没有延迟,yes关注性能,no关注redis服务中的数据一致性
repl-disable-tcp-nodelay no
# master的写入数据缓冲区,用于记录自上一次同步后到下一次同步过程中间的写入命令,计算公式:repl-backlog-size = 允许从节点最大中断时长 * 主实例offset每秒写入量,比如master每秒最大写入64mb,最大允许60秒,那么就要设置为64mb*60秒=3840MB(3.8G),建议此值是设置的足够大
repl-backlog-size 1mb
# 一段时间后slave没有连接到master,则backlog size的内存将会被释放。如果值为0则 表示永远不释放这部份内存
repl-backlog-ttl 3600
# slave端的优先级设置,值是一个整数,数字越小表示优先级越高。当master故障时将会按照优先级来选择slave端进行恢复,如果值设置为0,则表示该slave永远不会被选择
slave-priority 100
# 设置一个master的可用slave不能少于多少个,否则master无法执行写
min-replicas-to-write 1
# 设置至少有上面数量的slave延迟时间都大于多少秒时,master不接收写操作(拒绝写入)
min-slaves-max-lag 20常见故障
- master 密码不对
- Redis 版本不一致
- 没有设置 bind 地址或者 密码,导致无法远程连接
- 配置不一致,例如:
- 主从节点的 maxmemory 不一致,主节点内存大于从节点内存,主从复制可能丢失数据
- rename-command 不一致,如在主节点定义了 flushdb,从节点没定义,结果执行 flushdb,不同步
Redis 哨兵
- sentinel 实际上是一个特殊的 redis 服务器,很多 redis 命令不支持,默认监听在 26379/tcp 端口
- 哨兵可以不与 redis 部署在一起,但是一般都部署在一起
- Sentinel 节点个数应该为大于等于 3 且最好为奇数
- Sentinel 进程监控 redis 集群中 Master 主服务器工作的状态,在 Master 主服务器发生故障时,可以实现 Master 和 Slave 服务器的切换,保证系统的高可用
bind 0.0.0.0
# 如果不设置密码,protected-mode需要设置为no,否则无法远程连接
protected-mode no
port 26379
daemonize no
pidfile /usr/local/redis/run/redis-sentinel.pid
logfile "/usr/local/redis/var/sentinel.log"
# sentinel announce-ip <ip>
# sentinel announce-port <port>
# sentinel announce-ip 1.2.3.4
dir /tmp
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
# 主从复制架构中,执行master的ip、端口,当2个哨兵标记master下线,则判定master客观下线
sentinel monitor mymaster 127.0.0.1 6379 2
# sentinel auth-pass <master-name> <password>
# 指定master的账号密码
# sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# sentinel down-after-milliseconds <master-name> <milliseconds>
# 超时没有返回ping或者直接返回错误,则标记为下线,默认3秒
sentinel down-after-milliseconds mymaster 30000
# sentinel parallel-syncs <master-name> <numreplicas>
# 故障发生后,从节点需要从新的主节点同步数据,此项规定并发同步数,即同时允许几个slave从master同步数据,设置1同步时间最久,对主节点压力最小
sentinel parallel-syncs mymaster 1
# sentinel failover-timeout <master-name> <milliseconds>
# failover(故障转移)的超时时间,用于以下四种情况:
# 1.同一个sentinel对同一个master两次failover之间的间隔时间
# 2.当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时
# 3.当想要取消一个正在进行的failover所需要的时间
# 4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了
sentinel failover-timeout mymaster 180000
# sentinel notification-script <master-name> <script-path>
# sentinel notification-script mymaster /var/redis/notify.sh
# sentinel client-reconfig-script <master-name> <script-path>
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
# sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
# 禁止修改脚本
sentinel deny-scripts-reconfig yes
启动服务后,redis 会对配置文件做一些修改
实现
范例:master:10.0.0.71、slave:10.0.0.72 和 10.0.0.73
修改配置文件
# 从节点修改 redis.conf replicaof 10.0.0.71 6379 # 从节点修改 redis-sentinel.conf sentinel monitor mymaster 10.0.0.71 6379 2启动 redis 和 redis-sentinel 服务
测试
手动下线主节点,让 10.0.0.72 提升为主节点
[root@c72 ~]#vim /etc/redis.conf replica-priority 10 # 指定优先级,值越小sentinel会优先将之选为新的master,默为值为100 [root@c71 ~]#redis-cli -p 26379 127.0.0.1:26379> sentinel failover mymaster # 手动下线主节点,任意一个节点均可执行 OK
应用程序连接
客户端不直接连接 redis,而是连接 sentinel,不过 sentinel 不是代理,以 python 为例:
#!/usr/bin/python3
import redis
from redis.sentinel import Sentinel
#连接哨兵服务器(主机名也可以用域名)
sentinel = Sentinel([
('10.0.0.8', 26379),('10.0.0.18', 26379),('10.0.0.28', 26379)
],socket_timeout=0.5)Redis Cluster
Sentinel 机制可以解决 master 和 slave 角色的自动切换问题,但单个 Master 的性能瓶颈问题无法解决,类似于 MySQL 中的 MHA 功能,redis 3.0 之前版本中,生产环境一般使用哨兵模式
redis 3.0 版本之后推出了无中心架构的 redis cluster 机制,在无中心的 redis 集群当中,其每个节点保存当前节点数据和整个集群状态,每个节点都和其他所有节点连接
Redis Cluster 特点:
- 所有 Redis 节点使用(PING 机制)互联
- 集群中某个节点的是否失效,是由整个集群中超过半数的节点监测都失效,才能算真正的失效
- 客户端不需要代理即可直接连接 redis,应用程序中需要配置有全部的 redis 服务器 IP
- redis cluster 把所有的 redis node 平均映射到 0-16383 个槽位(slot)上,读写需要到指定的 redisnode 上进行操作,因此有多少个 redis node 相当于 redis 并发扩展了多少倍,每个 redis node 承担 16384/N 个槽位
- Redis cluster 预先分配 16384 个(slot)槽位,当需要在 redis 集群中写入一个 key -value 的时候,会使用 CRC16(key) mod 16384 之后的值,决定将 key 写入值哪一个槽位从而决定写入哪一个 Redis 节点上,从而有效解决单机瓶颈
Redis Cluster 架构
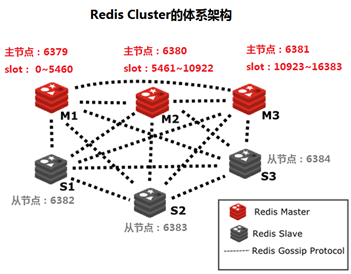
当主节点出现故障,其从节点会自动提升
实现
6 个节点 10.0.0.[71-76],其中 10.0.0.[71-73]是主节点、10.0.0.[74-76]是从节点
修改 redis.conf 相关配置
# 开启集群 cluster-enabled yes # 集群状态文件,记录主从关系及slot范围信息,由redis cluster集群自动创建和维护 cluster-config-file nodes-6379.conf # 默认yes,一个节点下线整个集群不可用;设置为no,则其他正常节点还可以继续提供对外访问 cluster-require-full-coverage no启动 redis 服务
# 启动之前确保集群中的每个节点是干净的,需要清除dump.rdb、nodes-6379.conf等文件 rm -rf /usr/local/redis/data/* systemctl start redis.service创建集群
# --cluster-replicas 1 表示每个master对应一个slave节点 [root@c71 data]$redis-cli --cluster create 10.0.0.71:6379 10.0.0.72:6379 10.0.0.73:6379 10.0.0.74:6379 10.0.0.75:6379 10.0.0.76:6379 --cluster-replicas 1 >>> Performing hash slots allocation on 6 nodes... Master[0] -> Slots 0 - 5460 Master[1] -> Slots 5461 - 10922 Master[2] -> Slots 10923 - 16383 Adding replica 10.0.0.75:6379 to 10.0.0.71:6379 Adding replica 10.0.0.76:6379 to 10.0.0.72:6379 Adding replica 10.0.0.74:6379 to 10.0.0.73:6379 M: 52c617ce1f5e67ee2da39beb8ae99240914f6f6d 10.0.0.71:6379 # M:master slots:[0-5460] (5461 slots) master M: 4fd60cab86be22d0a9edac1a8b7ac07b293e497d 10.0.0.72:6379 slots:[5461-10922] (5462 slots) master M: 8406e58b4d132960300074f431b0b4b9900c94a5 10.0.0.73:6379 slots:[10923-16383] (5461 slots) master S: 6c7f8028a16d1f07e7be7a33fa23528e7e9d69c6 10.0.0.74:6379 # S:slave replicates 8406e58b4d132960300074f431b0b4b9900c94a5 S: 01849d7567cee594e6ebe2b6f09d19008a1e625b 10.0.0.75:6379 replicates 52c617ce1f5e67ee2da39beb8ae99240914f6f6d S: 461a59fd85df1839d77877e66aaa4a08ffff068f 10.0.0.76:6379 replicates 4fd60cab86be22d0a9edac1a8b7ac07b293e497d Can I set the above configuration? (type 'yes' to accept): yes # 输入yes自动创建集群 >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join .... >>> Performing Cluster Check (using node 10.0.0.71:6379) M: 52c617ce1f5e67ee2da39beb8ae99240914f6f6d 10.0.0.71:6379 slots:[0-5460] (5461 slots) master # 分配的槽位 1 additional replica(s) # 添加一个从节点 S: 6c7f8028a16d1f07e7be7a33fa23528e7e9d69c6 10.0.0.74:6379 slots: (0 slots) slave # 从节点没有分配槽位 replicates 8406e58b4d132960300074f431b0b4b9900c94a5 M: 8406e58b4d132960300074f431b0b4b9900c94a5 10.0.0.73:6379 slots:[10923-16383] (5461 slots) master 1 additional replica(s) S: 461a59fd85df1839d77877e66aaa4a08ffff068f 10.0.0.76:6379 slots: (0 slots) slave replicates 4fd60cab86be22d0a9edac1a8b7ac07b293e497d M: 4fd60cab86be22d0a9edac1a8b7ac07b293e497d 10.0.0.72:6379 slots:[5461-10922] (5462 slots) master 1 additional replica(s) S: 01849d7567cee594e6ebe2b6f09d19008a1e625b 10.0.0.75:6379 slots: (0 slots) slave replicates 52c617ce1f5e67ee2da39beb8ae99240914f6f6d [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. #观察以上结果,可以看到3组master/slave master:10.0.0.71---slave:10.0.0.74 master:10.0.0.72---slave:10.0.0.75 master:10.0.0.73---slave:10.0.0.76在每个节点执行
info replication可以查看此节点的主从信息在任意节点执行
cluster nodes可以查看所有节点的 ID 及连接信息在任意节点执行
cluster info可以查看整个集群的状态信息在任意节点执行
redis-cli --cluster info 10.0.0.71:6379可以查看所有主节点的信息在任意节点执行
redis-cli --cluster check 10.0.0.71:6379可以查看所有节点的信息
管理
动态扩容
目前集群中有 6 个节点 10.0.0.[71-76],三主三从,现在要将 10.0.0.77 添加到集群中
添加节点:在任意一个节点上执行
redis-cli --cluster add-node 10.0.0.77:6379 <当前任意集群节点>:6379新节点是 master,且没有分配槽位
给新 master 节点分配槽位
redis-cli --cluster reshard <当前任意集群节点>:6379 # 需要移动多少槽位? 16384/master个数,这里16384/4=4096 How many slots do you want to move (from 1 to 16384)?4096 # 哪个节点接收移动的槽位?当然是新添加的master节点了,输入10.0.0.77的node ID What is the receiving node ID?defa5ca3d7aaecea240a79ad2c9b572ebf32464a # 哪些节点提供槽位,all表示当前所有master节点,或者输入一个或多个node ID,最后输入done表示结束 Please enter all the source node IDs. Type 'all' to use all the nodes as source nodes for the hash slots. Type 'done' once you entered all the source nodes IDs. Source node #1:all # 确认分配 Do you want to proceed with the proposed reshard plan (yes/no)? yes这样,新的 master 节点就分配了 4096 个槽位,由于这些槽位是其他三个 master 节点平均分配给新 master 节点的,所以避免不了槽位碎片化的问题
重新分配槽位后,之前节点的角色不变,但属关系可能发生改变,例如本来 10.0.0.71 的从节点是 10.0.0.74,扩容后它的从节点成了 10.0.0.75,而 10.0.0.74 成了 10.0.0.3 的从节点
这种扩容方法是在线的,不需要备份数据,如果数据量比较大的话,建议先备份
为新的 master 添加新的 slave 节点
新的 master 节点没有 slave 节点,需要添加一个(10.0.0.78)以保证高可用,任意节点执行以下命令:
redis-cli --cluster add-node 10.0.0.78:6379 <任意集群节点>:6379 --cluster-slave --cluster-master-id defa5ca3d7aaecea240a79ad2c9b572ebf32464a或者先将新节点加入集群,再修改为 slave:
redis-cli --cluster add-node 10.0.0.78:6379 <任意集群节点>:6379 [root@c78 ~]$redis-cli # 查看当前集群节点,找到目标master 的ID 127.0.0.1:6379> CLUSTER NODES # 将其设置slave,命令格式为cluster replicate MASTERID 127.0.0.1:6379> CLUSTER REPLICATE 8defa5ca3d7aaecea240a79ad2c9b572ebf32464a
动态缩容
从节点:在任意节点上执行
redis-cli --cluster del-node host:port node_id删除 slave 节点 10.0.0.75:

主节点:需要在删除之前先把槽位移动到其他 master 节点上,可以使用交互式和命式两种方式
删除 master 节点 10.0.0.71:
交互式:在任意节点上执行
redis-cli --cluster reshard <任意集群节点>:6379 ... M: 52c617ce1f5e67ee2da39beb8ae99240914f6f6d 10.0.0.71:6379 slots:[1364-5460] (4096 slots) master ... # 需要移动多少槽位? 10.0.0.71有4096个槽位,需要平均分给其他三个master节点,所以我们分1365、1365、1366三次移动 How many slots do you want to move (from 1 to 16384)?1365 # 哪个节点接收移动的槽位?经过观察10.0.0.77适合接受,依据是尽量不造成槽位的碎片化 What is the receiving node ID?defa5ca3d7aaecea240a79ad2c9b572ebf32464a # 哪些节点提供槽位,当然是要删除的10.0.0.71了 Please enter all the source node IDs. Type 'all' to use all the nodes as source nodes for the hash slots. Type 'done' once you entered all the source nodes IDs. Source node #1:52c617ce1f5e67ee2da39beb8ae99240914f6f6d Source node #2:done # 确认分配 ... Moving slot 2727 from 10.0.0.71:6379 to 10.0.0.77:6379: # 注意观察,不要出错 ... Do you want to proceed with the proposed reshard plan (yes/no)? yes命令式:在任意节点上执行
# 移动1365个槽位到10.0.0.72 redis-cli --cluster reshard <任意集群节点>:6379 --cluster-slots 1365 --cluster-from 52c617ce1f5e67ee2da39beb8ae99240914f6f6d --cluster-to 4fd60cab86be22d0a9edac1a8b7ac07b293e497d --cluster-yes # 移动最后的1366个槽位到10.0.0.73 redis-cli --cluster reshard <任意集群节点>:6379 --cluster-slots 1366 --cluster-from 52c617ce1f5e67ee2da39beb8ae99240914f6f6d --cluster-to 8406e58b4d132960300074f431b0b4b9900c94a5 --cluster-yes10.0.0.71 上的槽位都移走了之后,其 slave 节点(如果有)也会变成了其他 master 节点的 slave 节点
最后执行
redis-cli --cluster del-node host:port node_id即可将 10.0.0.71 节点删除[root@c71 ~]$redis-cli --cluster del-node 10.0.0.71:6379 52c617ce1f5e67ee2da39beb8ae99240914f6f6d >>> Removing node 52c617ce1f5e67ee2da39beb8ae99240914f6f6d from cluster 10.0.0.71:6379 >>> Sending CLUSTER FORGET messages to the cluster... >>> SHUTDOWN the node.

导入现有数据至集群
在任意集群节点上执行:
redis-cli --cluster import <任意集群节点>:6379 --cluster-from <外部Redis>:6379 --cluster-copy --cluster-replace- –cluster-replace:当导入的数据和已有的数据有重复的 key,–cluster-replace 表示替换为导入的数据
集群偏斜
redis cluster 多个节点运行一段时间后,可能会出现倾斜现象,某个节点数据偏多,内存消耗更大,或者接受用户请求访问更多,发生倾斜的原因可能如下:
- 不同槽对应的键值数量差异较大
- 包含 bigkey,建议少用
- 内存相关配置不一致
获取指定槽位中对应 key 值个数
redis-cli cluster countkeysinslot {slot的值}执行自动的槽位重新平衡分布,但会影响客户端的访问,慎用
redis-cli --cluster rebalance <任意集群节点>:6379获取 bigkey,建议在 slave 节点运行
redis-cli --bigkeys解散集群
systemctl stop redis.service关闭所有的 redis 服务,然后删除 nodes-6379.conf 文件,修改 redis.conf:cluster-enabled no
redis cluster 的局限性
- 命令无法跨节点使用,所以 mset、mget、sunion 等操作支持不友好
- 客户端维护更复杂,客户端为了可以直接定位某个具体的 key 所在的节点,它就需要缓存槽位相关信息,这样才可以准确快速地定位到相应的节点。同时因为槽位的信息可能会存在客户端与服务器不一致的情况,还需要纠正机制来实现槽位信息的校验调整
- 不支持多个数据库,集群模式下只有一个 db0
- 主从复制只有一层,不支持级联复制
- 节点因为某些原因发生阻塞(阻塞时间大于 clutser-node-timeout)被判断下线,这种 failover 是没有必要的
以上缺点只有第一点是比较麻烦的