ELK
本文最后更新于:2023年12月5日 晚上
配套 B 站教程:https://www.bilibili.com/video/BV1Be4y167n9
Elastic Stack 在企业的常见架构
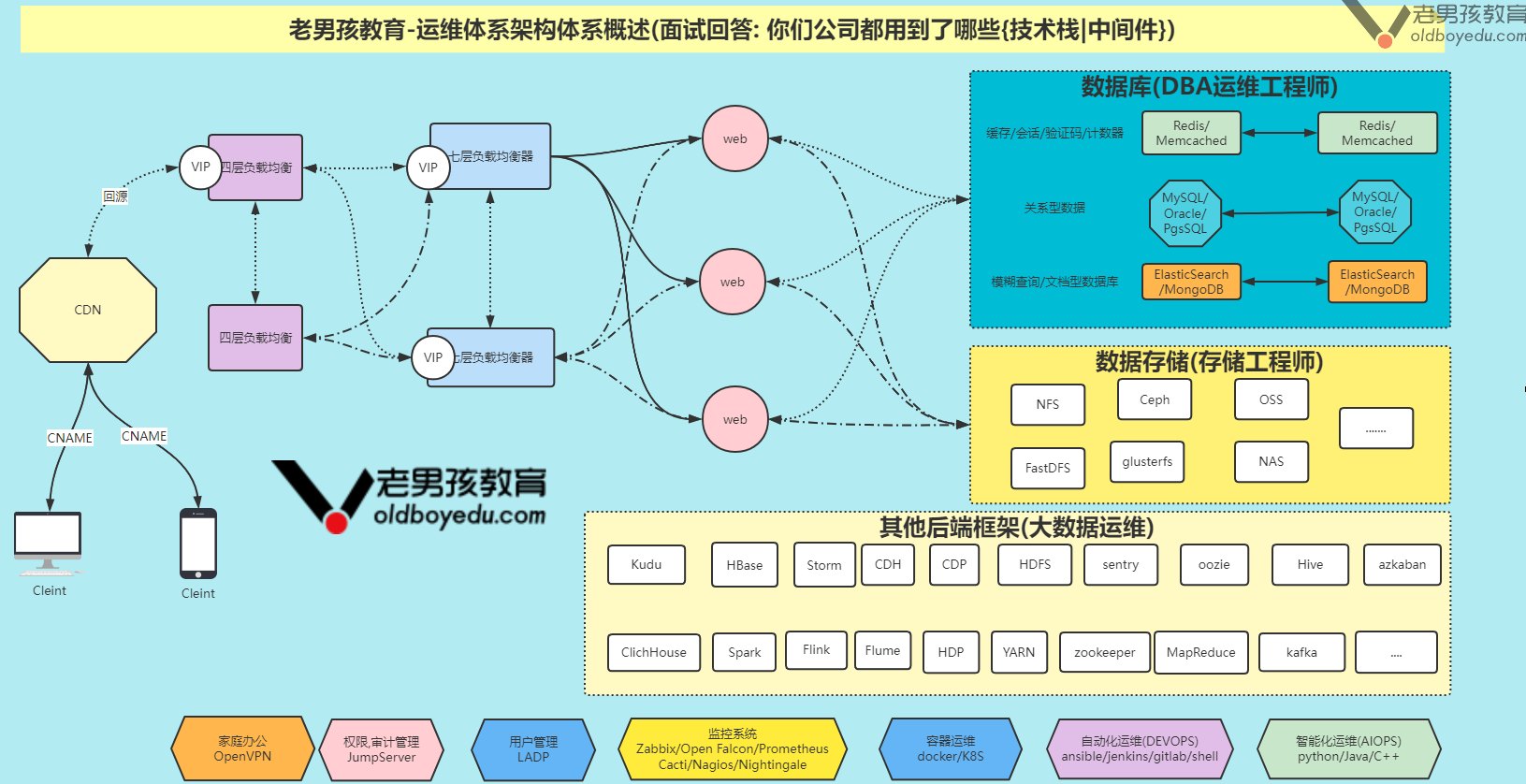
Elastic Stack 分布式⽇志系统概述

集群基础环境初始化
1.准备虚拟机
| IP 地址 | 主机名 | CPU 配置 | 内存配置 | 磁盘配置 | 角色说明 |
|---|---|---|---|---|---|
| 10.0.0.101 | elk101.oldboyedu.com | 2 core | 4G | 20G+ | ES node |
| 10.0.0.102 | elk102.oldboyedu.com | 2 core | 4G | 20G+ | ES node |
| 10.0.0.103 | elk103.oldboyedu.com | 2 core | 4G | 20G+ | ES node |
2.修改软件源
参考链接:https://mirrors.tuna.tsinghua.edu.cn/help/centos/
# 对于 CentOS 7
sudo sed -e 's|^mirrorlist=|#mirrorlist=|g' \
-e 's|^#baseurl=http://mirror.centos.org|baseurl=https://mirrors.tuna.tsinghua.edu.cn|g' \
-i.bak \
/etc/yum.repos.d/CentOS-*.repo
# 对于 CentOS 8
sudo sed -e 's|^mirrorlist=|#mirrorlist=|g' \
-e 's|^#baseurl=http://mirror.centos.org/$contentdir|baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos|g' \
-i.bak \
/etc/yum.repos.d/CentOS-*.repo3.修改终端颜色
cat <<EOF >> ~/.bashrc
PS1='[\[\e[34;1m\]\u@\[\e[0m\]\[\e[32;1m\]\H\[\e[0m\]\[\e[31;1m\] \W\[\e[0m\]]# '
EOF
source ~/.bashrc4.修改 sshd 服务优化
sed -ri 's@^#UseDNS yes@UseDNS no@g' /etc/ssh/sshd_config
sed -ri 's#^GSSAPIAuthentication yes#GSSAPIAuthentication no#g' /etc/ssh/sshd_config
grep ^UseDNS /etc/ssh/sshd_config
grep ^GSSAPIAuthentication /etc/ssh/sshd_config5.关闭防⽕墙
systemctl disable --now firewalld && systemctl is-enabled firewalld
systemctl status firewalld6.禁⽤ selinux
sed -ri 's#(SELINUX=)enforcing#\1disabled#' /etc/selinux/config
grep ^SELINUX= /etc/selinux/config
setenforce 0
getenforce7.配置集群免密登录及同步脚本
# 1.修改主机列表
cat >>/etc/hosts <<EOF
10.0.0.101 elk101.oldboyedu.com
10.0.0.102 elk102.oldboyedu.com
10.0.0.103 elk103.oldboyedu.com
EOF
# 2.elk101节点上⽣成密钥对
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa -q
# 3.elk101配置所有集群节点的免密登录
for ((host_id = 101; host_id <= 103; host_id++)); do
ssh-copy-id
elk${host_id}.oldboyedu.com
done
# 4.链接测试
ssh 'elk101.oldboyedu.com'
ssh 'elk102.oldboyedu.com'
ssh 'elk103.oldboyedu.com'
# 5.所有节点安装rsync数据同步⼯具
yum -y install rsync
# 6.编写同步脚本
vim /usr/local/sbin/data_rsync.sh
# 将下⾯的内容拷⻉到该⽂件即可
#!/bin/bash
# Auther: Jason Yin
if
[ $# -ne 1 ]
then
echo "Usage: $0 /path/to/file(绝对路径)"
exit
fi
# 判断⽂件是否存在
if [ ! -e $1 ]; then
echo "[ $1 ] dir or file not find!"
exit
fi
# 获取⽗路径
fullpath=$(dirname $1)
# 获取⼦路径
basename=$(basename $1)
# 进⼊到⽗路径
cd $fullpath
for ((host_id = 102; host_id <= 103; host_id++)); do
# 使得终端输出变为绿⾊
tput setaf 2
echo ===== rsyncing elk${host_id}.oldboyedu.com: $basename =====
# 使得终端恢复原来的颜⾊
tput setaf 7
# 将数据同步到其他两个节点
rsync -az $basename
$(whoami)@elk${host_id}.oldboyedu.com:$fullpath
if [ $? -eq 0 ]; then
echo "命令执⾏成功!"
fi
done
# 7.给脚本授权
chmod +x /usr/local/sbin/data_rsync.sh8.集群时间同步
# 1.安装常⽤的Linux⼯具,您可以⾃定义哈。
yum -y install vim net-tools
# 2.安装chrony服务
yum -y install ntpdate chrony
# 3.修改chrony服务配置⽂件
vim /etc/chrony.conf
#...
# 注释官⽅的时间服务器,换成国内的时间服务器即可
server ntp.aliyun.com iburst
server ntp1.aliyun.com iburst
server ntp2.aliyun.com iburst
server ntp3.aliyun.com iburst
server ntp4.aliyun.com iburst
server ntp5.aliyun.com iburst
#...
# 4.配置chronyd的开机⾃启动
systemctl enable --now chronyd
systemctl restart chronyd
# 5.查看服务
systemctl status chronydElasticsearch 单点部署
1.下载
https://www.elastic.co/cn/downloads/elasticsearch
2.单点部署 elasticsearch
# 1.安装服务
$ yum -y localinstal elasticsearch-7.17.3-x86_64.rpm
# 2.修改配置⽂件
$ egrep -v "^#|^$" /etc/elasticsearch/elasticsearch.yml
cluster.name: oldboyedu-elk
node.name: oldboyedu-elk103
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 10.0.0.103
discovery.seed_hosts: ["10.0.0.103"]
# 相关参数说明:
# cluster.name: 集群名称,若不指定,则默认是"elasticsearch",⽇志⽂件的前缀也是集群名称。
# node.name: 指定节点的名称,可以⾃定义,推荐使⽤当前的主机名,要求集群唯⼀。
# path.data: 数据路径。
# path.logs: ⽇志路径
# network.host: ES服务监听的IP地址
# discovery.seed_hosts: 服务发现的主机列表,对于单点部署⽽⾔,主机列表和"network.host"字段配置相同即可。
# 3.启动服务
$ systemctl start elasticsearch.serviceElasticsearch 分布式集群部署
1.elk101 修改配置文件
egrep -v "^$|^#" /etc/elasticsearch/elasticsearch.yml
...
cluster.name: oldboyedu-elk
node.name: elk101
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
discovery.seed_hosts: ["elk101","elk102","elk103"]
cluster.initial_master_nodes: ["elk101","elk102","elk103"]
# 温馨提示:
# "node.name"各个节点配置要区分清楚,建议写对应的主机名称。2.同步配置⽂件到集群的其他节点
# 1.elk101同步配置⽂件到集群的其他节点
data_rsync.sh /etc/elasticsearch/elasticsearch.yml
# 2.elk102节点配置
vim /etc/elasticsearch/elasticsearch.yml
...
node.name: elk102
# 3.elk103节点配置
vim /etc/elasticsearch/elasticsearch.yml
...
node.name: elk1033.所有节点删除之前的临时数据
pkill java
rm -rf /var/{lib,log}/elasticsearch/* /tmp/*
ll /var/{lib,log}/elasticsearch/ /tmp/4.所有节点启动服务
# 1.所有节点启动服务
systemctl start elasticsearch
# 2.启动过程中建议查看⽇志
tail -100f /var/log/elasticsearch/oldboyedu-elk.log5.验证集群是否正常
curl elk103:9200/_cat/nodes?v
部署 kibana 服务
1.本地安装 kibana
yum -y localinstall kibana-7.17.3-x86_64.rpm2.修改 kibana 的配置⽂件
vim /etc/kibana/kibana.yml
...
server.host: "10.0.0.101"
server.name: "oldboyedu-kibana-server"
elasticsearch.hosts: ["http://10.0.0.101:9200","http://10.0.0.102:9200","http://10.0.0.103:9200"]
i18n.locale: "zh-CN"3.启动 kibana 服务
systemctl enable --now kibana
systemctl status kibana4.访问 kibana 的 webUI
略。。。
filebeat 部署及基础使用
$ ./filebeat --help
Usage:
filebeat [flags]
filebeat [command]
Available Commands:
export Export current config or index template
generate Generate Filebeat modules, filesets and fields.yml
help Help about any command
keystore Manage secrets keystore
modules Manage configured modules
run Run filebeat
setup Setup index template, dashboards and ML jobs
test Test config
version Show current version info
Flags:
-E, --E setting=value Configuration overwrite
-M, --M setting=value Module configuration overwrite
-N, --N Disable actual publishing for testing
-c, --c string Configuration file, relative to path.config (default "filebeat.yml")
--cpuprofile string Write cpu profile to file
-d, --d string Enable certain debug selectors
-e, --e Log to stderr and disable syslog/file output
--environment environmentVar set environment being ran in (default default)
-h, --help help for filebeat
--httpprof string Start pprof http server
--memprofile string Write memory profile to this file
--modules string List of enabled modules (comma separated)
--once Run filebeat only once until all harvesters reach EOF
--path.config string Configuration path
--path.data string Data path
--path.home string Home path
--path.logs string Logs path
--plugin pluginList Load additional plugins
--strict.perms Strict permission checking on config files (default true)
-v, --v Log at INFO level
Use "filebeat [command] --help" for more information about a command.1.部署 filebeat 环境
yum -y localinstall filebeat-7.17.3-x86_64.rpm
# 温馨提示: elk102节点操作2.简单测试
2.1 编写配置文件
mkdir /etc/filebeat/config
cat > /etc/filebeat/config/01-stdin-to-console.yml <<EOF
filebeat.inputs: # 指定输⼊的类型
- type: stdin # 指定输⼊的类型为"stdin",表示标准输⼊
output.console: # 指定输出的类型
pretty: true # 打印漂亮的格式
EOF2.2 运行 filebeat 实例
$ filebeat -e -c /etc/filebeat/config/01-stdin-to-console.yml
...2.3 测试
...
hello word
{
"@timestamp": "2022-11-04T05:47:24.880Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "8.4.3"
},
"ecs": {
"version": "8.0.0"
},
"host": {
"name": "lujinkai-pc"
},
"log": {
"file": {
"path": ""
},
"offset": 0
},
"message": "hello word",
"input": {
"type": "stdin"
},
"agent": {
"type": "filebeat",
"version": "8.4.3",
"ephemeral_id": "8a43c946-9a6d-43dc-8a79-4fe673f7882d",
"id": "af9266b6-6d99-48d2-abc2-acea45ef1c61",
"name": "lujinkai-pc"
}
}
...3.input 的 log 类型
filebeat.inputs:
- type: log
paths:
- /tmp/test.log
output.console:
pretty: true4.input 的通配符案例
filebeat.inputs:
- type: log
paths:
- /tmp/test.log
- /tmp/*.txt
output.console:
pretty: true5.input 的通用字段案例
filebeat.inputs:
- type: log
# 是否启动当前的输⼊类型,默认值为true
enabled: true
# 指定数据路径
paths:
- /tmp/test.log
- /tmp/*.txt
# 给当前的输⼊类型搭上标签
tags: ["oldboyedu-linux80", "容器运维", "DBA运维", "SRE运维⼯程师"]
# ⾃定义字段
fields:
school: "北京昌平区沙河镇"
class: "linux80"
- type: log
enabled: true
paths:
- /tmp/test/*/*.log
tags: ["oldboyedu-python", "云原⽣开发"]
fields:
name: "oldboy"
hobby: "linux,抖⾳"
# 将⾃定义字段的key-value放到顶级字段.
# 默认值为false,会将数据放在⼀个叫"fields"字段的下⾯.
fields_under_root: true
output.console:
pretty: true6.日志过滤案例
filebeat.inputs:
- type: log
enabled: true
paths:
- /tmp/test/*.log
# 注意,⿊⽩名单均⽀持通配符,⽣产环节中不建议同时使⽤,
# 指定⽩名单,包含指定的内容才会采集,且区分⼤⼩写!
include_lines: ["^ERR", "^WARN", "oldboyedu"]
# 指定⿊名单,排除指定的内容
exclude_lines: ["^DBG", "linux", "oldboyedu"]
output.console:
pretty: true7.将数据写入 es 案例
filebeat.inputs:
- type: log
enabled: true
paths:
- /tmp/test.log
- /tmp/*.txt
tags: ["oldboyedu-linux80", "容器运维", "DBA运维", "SRE运维⼯程师"]
fields:
school: "北京昌平区沙河镇"
class: "linux80"
- type: log
enabled: true
paths:
- /tmp/test/*/*.log
tags: ["oldboyedu-python", "云原⽣开发"]
fields:
name: "oldboy"
hobby: "linux,抖⾳"
fields_under_root: true
output.elasticsearch:
hosts: ["http://10.0.0.101:9200", "http://10.0.0.102:9200", "http://10.0.0.103:9200"]8.自定义 es 索引名称
filebeat.inputs:
- type: log
enabled: true
paths:
- /tmp/test.log
- /tmp/*.txt
tags: ["oldboyedu-linux80", "容器运维", "DBA运维", "SRE运维⼯程师"]
fields:
school: "北京昌平区沙河镇"
class: "linux80"
- type: log
enabled: true
paths:
- /tmp/test/*/*.log
tags: ["oldboyedu-python", "云原⽣开发"]
fields:
name: "oldboy"
hobby: "linux,抖⾳"
fields_under_root: true
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200", "http://10.0.0.102:9200", "http://10.0.0.103:9200"]
index: "oldboyedu-linux-elk-%{+yyyy.MM.dd}"
setup.ilm.enabled: false # 禁⽤索引⽣命周期管理
setup.template.name: "oldboyedu-linux" # 设置索引模板的名称
setup.template.pattern: "oldboyedu-linux*" # 设置索引模板的匹配模式9.多个索引写入案例
filebeat.inputs:
- type: log
enabled: true
paths:
- /tmp/test.log
- /tmp/*.txt
tags: ["oldboyedu-linux80", "容器运维", "DBA运维", "SRE运维⼯程师"]
fields:
school: "北京昌平区沙河镇"
class: "linux80"
- type: log
enabled: true
paths:
- /tmp/test/*/*.log
tags: ["oldboyedu-python", "云原⽣开发"]
fields:
name: "oldboy"
hobby: "linux,抖⾳"
fields_under_root: true
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200", "http://10.0.0.102:9200", "http://10.0.0.103:9200"]
# index: "oldboyedu-linux-elk-%{+yyyy.MM.dd}"
indices:
- index: "oldboyedu-linux-elk-%{+yyyy.MM.dd}"
# 匹配指定字段包含的内容
when.contains:
tags: "oldboyedu-linux80"
- index: "oldboyedu-linux-python-%{+yyyy.MM.dd}"
when.contains:
tags: "oldboyedu-python"
setup.ilm.enabled: false # 禁⽤索引⽣命周期管理
setup.template.name: "oldboyedu-linux" # 设置索引模板的名称
setup.template.pattern: "oldboyedu-linux*" # 设置索引模板的匹配模式10.自定义分片和副本案例
filebeat.inputs:
- type: log
enabled: true
paths:
- /tmp/test.log
- /tmp/*.txt
tags: ["oldboyedu-linux80", "容器运维", "DBA运维", "SRE运维⼯程师"]
fields:
school: "北京昌平区沙河镇"
class: "linux80"
- type: log
enabled: true
paths:
- /tmp/test/*/*.log
tags: ["oldboyedu-python", "云原⽣开发"]
fields:
name: "oldboy"
hobby: "linux,抖⾳"
fields_under_root: true
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200", "http://10.0.0.102:9200", "http://10.0.0.103:9200"]
# index: "oldboyedu-linux-elk-%{+yyyy.MM.dd}"
indices:
- index: "oldboyedu-linux-elk-%{+yyyy.MM.dd}"
# 匹配指定字段包含的内容
when.contains:
tags: "oldboyedu-linux80"
- index: "oldboyedu-linux-python-%{+yyyy.MM.dd}"
when.contains:
tags: "oldboyedu-python"
setup.ilm.enabled: false # 禁⽤索引⽣命周期管理
setup.template.name: "oldboyedu-linux" # 设置索引模板的名称
setup.template.pattern: "oldboyedu-linux*" # 设置索引模板的匹配模式
setup.template.overwrite: false # 覆盖已有的索引模板
setup.template.settings: # 配置索引模板
index.number_of_shards: 3 # 设置分⽚数量
index.number_of_replicas: 2 # 设置副本数量,要求⼩于集群的数量11.filebeat 实现日志聚合到本地
filebeat.inputs:
- type: tcp
host: "0.0.0.0:9000"
output.file:
path: "/tmp/filebeat"
filename: oldboyedu-linux80
rotate_every_kb: 102400 # 指定⽂件的滚动⼤⼩,默认值为20MB
number_of_files: 300 # 指定保存的⽂件个数,默认是7个,有效值为2-1024个
permissions: 0600 # 指定⽂件的权限,默认权限是060012.filebeat 实现日志聚合到 ES 集群
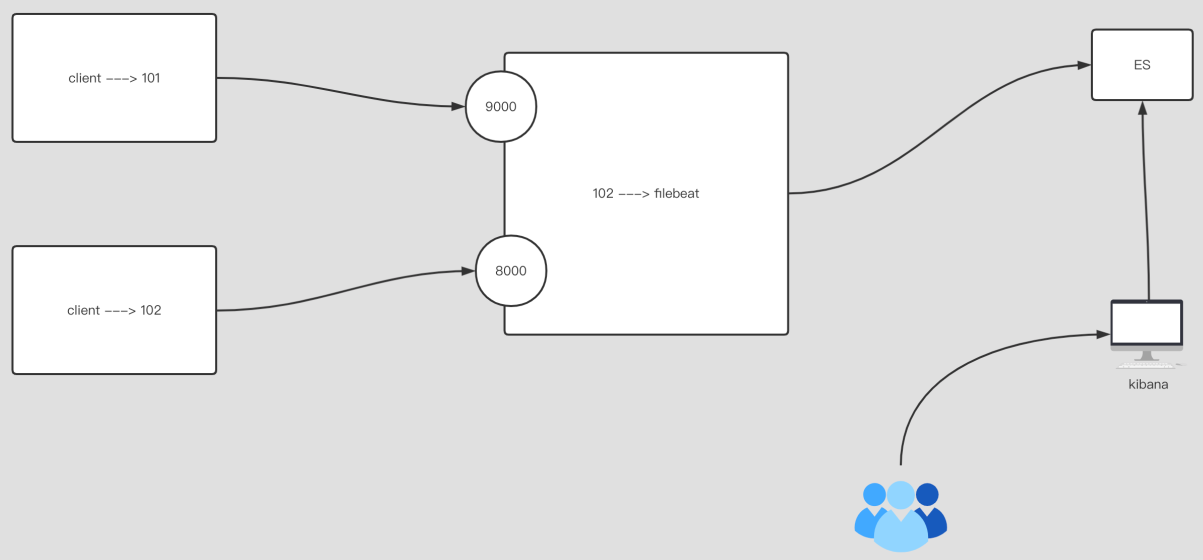
filebeat.inputs:
- type: tcp
host: "0.0.0.0:9000"
tags: ["aaa"]
- type: tcp
host: "0.0.0.0:8000"
tags: ["bbb"]
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200", "http://10.0.0.102:9200", "http://10.0.0.103:9200"]
indices:
- index: "oldboyedu-linux80-elk-aaa-%{+yyyy.MM.dd}"
when.contains:
tags: "aaa"
- index: "oldboyedu-linux80-elk-bbb-%{+yyyy.MM.dd}"
when.contains:
tags: "bbb"
setup.ilm.enabled: false
setup.template.name: "oldboyedu-linux80-elk"
setup.template.pattern: "oldboyedu-linux80-elk*"
setup.template.overwrite: true
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 0EFK 架构企业级实战案例
1.部署 nginx 服务
# 1.配置nginx的软件源
cat >/etc/yum.repos.d/nginx.repo <<EOF
[nginx-stable]
name=nginx stable repo
baseurl=http://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=1
enabled=1
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
[nginx-mainline]
name=nginx mainline repo
baseurl=http://nginx.org/packages/mainline/centos/$releasever/$basearch/
gpgcheck=1
enabled=0
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
EOF
# 2.安装nginx服务
yum -y install nginx
# 3.启动nginx服务
systemctl start nginx2.基于 log 类型收集 nginx 原生日志
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log*
tags: ["access"]
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200", "http://10.0.0.102:9200", "http://10.0.0.103:9200"]
index: "oldboyedu-linux-nginx-%{+yyyy.MM.dd}"
setup.ilm.enabled: false # 禁⽤索引⽣命周期管理
setup.template.name: "oldboyedu-linux" # 设置索引模板的名称
setup.template.pattern: "oldboyedu-linux*" # 设置索引模板的匹配模式
setup.template.overwrite: true # 覆盖已有的索引模板,如果为true,则会直接覆盖现有的索引模板,如果为false则不覆盖!
setup.template.settings: # 配置索引模板
index.number_of_shards: 3 # 设置分⽚数量
index.number_of_replicas: 0 # 设置副本数量,要求⼩于集群的数量3.基于 log 类型收集 nginx 的 json 日志
# 1. 修改nginx的源⽇志格式
vim /etc/nginx/nginx.conf
...
log_format oldboyedu_nginx_json '{"@timestamp":"$time_iso8601",'
'"host":"$server_addr",'
'"clientip":"$remote_addr",'
'"SendBytes":$body_bytes_sent,'
'"responsetime":$request_time,'
'"upstreamtime":"$upstream_response_time",'
'"upstreamhost":"$upstream_addr",'
'"http_host":"$host",'
'"uri":"$uri",'
'"domain":"$host",'
'"xff":"$http_x_forwarded_for",'
'"referer":"$http_referer",'
'"tcp_xff":"$proxy_protocol_addr",'
'"http_user_agent":"$http_user_agent",'
'"status":"$status"}';
access_log /var/log/nginx/access.log oldboyedu_nginx_json;
# 2.检查nginx的配置⽂件语法并重启nginx服务
nginx -t
systemctl restart nginx
# 3.定义配置⽂件
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log*
tags: ["access"]
json.keys_under_root: true # 以JSON格式解析message字段的内容
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200","http://10.0.0.102:9200","http://10.0.0.103:9200"]
index: "oldboyedu-linux-nginx-access-%{+yyyy.MM.dd}"
setup.ilm.enabled: false # 禁⽤索引⽣命周期管理
setup.template.name: "oldboyedu-linux" # 设置索引模板的名称
setup.template.pattern: "oldboyedu-linux*" # 设置索引模板的匹配模式
setup.template.overwrite: true # 覆盖已有的索引模板,如果为true,则会直接覆盖现有的索引模板,如果为false则不覆盖!
setup.template.settings: # 配置索引模板
index.number_of_shards: 3 # 设置分⽚数量
index.number_of_replicas: 0 # 设置副本数量,要求⼩于集群的数量4.基于 modules 采集 nginx 日志文件
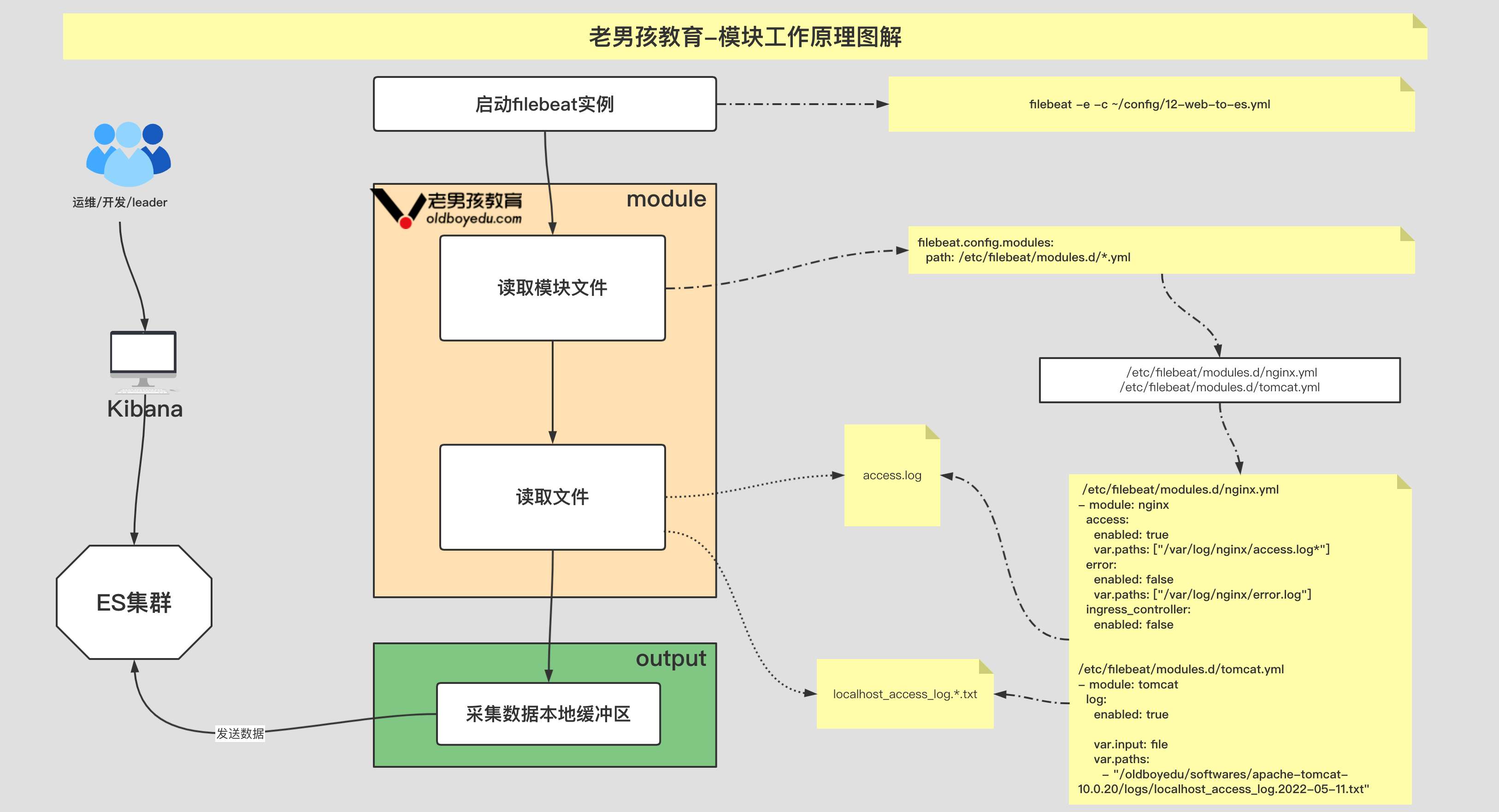
模块的基本使用
# 查看模块
$ filebeat modules list
# 启动模块
$ filebeat modules enable nginx tomcat
# 禁⽤模块
$ filebeat modules disable nginx tomcatfilebeat 配置⽂件(需要启⽤ nginx 模块)
filebeat.config.modules:
# 指定模块的配置⽂件路径,如果是yum⽅式安装,在7.17.3版本中不能使⽤如下的默认值。
# path: ${path.config}/modules.d/*.yml
# 经过实际测试,推荐⼤家使⽤如下的配置,此处写绝对路径即可!⽽对于⼆进制部署⽆需做此操作.
path: /etc/filebeat/modules.d/*.yml
# 开启热加载功能
reload.enabled: true
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200", "http://10.0.0.102:9200", "http://10.0.0.103:9200"]
index: "oldboyedu-linux-nginx-access-%{+yyyy.MM.dd}"/etc/filebeat/modules.d/nginx.yml ⽂件内容:
- module: nginx
access:
enabled: true
var.paths: ["/var/log/nginx/access.log*"]
error:
enabled: false
var.paths: ["/var/log/nginx/error.log"]
ingress_controller:
enabled: false5.基于 modules 采集 tomcat 日志文件
# 1.部署tomcat服务
# 1.1.解压tomcat软件包
tar xf apache-tomcat-10.0.20.tar.gz -C /oldboyedu/softwares/
# 1.2.创建符号链接
cd /oldboyedu/softwares/ && ln -sv apache-tomcat-10.0.20 tomcat
# 1.3.配置环境变量
vim /etc/profile.d/elk.sh
...
export JAVA_HOME=/usr/share/elasticsearch/jdk
export TOMCAT_HOME=/oldboyedu/softwares/tomcat
export PATH=$PATH:$TOMCAT_HOME/bin:$JAVA_HOME/bin
# 1.4.使得环境变量⽣效
source /etc/profile.d/elk.sh
# 1.5.启动服务
catalina.sh start
# 2.启⽤tomcat的模块管理
filebeat -c ~/config/11-nginx-to-es.yml modules disable nginx
filebeat -c ~/config/11-nginx-to-es.yml modules enable tomcat
filebeat -c ~/config/11-nginx-to-es.yml modules list
# 3.filebeat配置⽂件
filebeat.config.modules:
# 指定模块的配置⽂件路径,如果是yum⽅式安装,在7.17.3版本中不能使⽤如下的默认值。
# path: ${path.config}/modules.d/*.yml
# 经过实际测试,推荐⼤家使⽤如下的配置,此处写绝对路径即可!⽽对于⼆进制部署⽆需做此操作.
path: /etc/filebeat/modules.d/*.yml
# 开启热加载功能
reload.enabled: true
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200","http://10.0.0.102:9200","http://10.0.0.103:9200"]
index: "oldboyedu-linux-tomcat-access-%{+yyyy.MM.dd}"
setup.ilm.enabled: false # 禁⽤索引⽣命周期管理
setup.template.name: "oldboyedu-linux" # 设置索引模板的名称
setup.template.pattern: "oldboyedu-linux*" # 设置索引模板的匹配模式
setup.template.overwrite: true # 覆盖已有的索引模板,如果为true,则会直接覆盖现有的索引模板,如果为false则不覆盖!
setup.template.settings: # 配置索引模板
index.number_of_shards: 3 # 设置分⽚数量
index.number_of_replicas: 0 # 设置副本数量,要求⼩于集群的数量
# 4./etc/filebeat/modules.d/tomcat.yml⽂件内容
- module: tomcat
log:
enabled: true
# 指定输⼊的类型是⽂件,默认是监听udp端⼝哟~
var.input: file
var.paths:
- "/oldboyedu/softwares/apache-tomcat-10.0.20/logs/localhost_access_log.2022-05-11.txt"6.基于 log 类型收集 tomcat 的原生日志
filebeat.inputs:
- type: log
enabled: true
paths:
- /oldboyedu/softwares/apache-tomcat-10.0.20/logs/*.txt
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200", "http://10.0.0.102:9200", "http://10.0.0.103:9200"]
index: "oldboyedu-linux-tomcat-access-%{+yyyy.MM.dd}"
setup.ilm.enabled: false # 禁⽤索引⽣命周期管理
setup.template.name: "oldboyedu-linux" # 设置索引模板的名称
setup.template.pattern: "oldboyedu-linux*" # 设置索引模板的匹配模式
setup.template.overwrite: true # 覆盖已有的索引模板,如果为true,则会直接覆盖现有的索引模板,如果为false则不覆盖!
setup.template.settings: # 配置索引模板
index.number_of_shards: 3 # 设置分⽚数量
index.number_of_replicas: 0 # 设置副本数量,要求⼩于集群的数量7.基于 log 类型收集 tomcat 的 json 日志
# 1.⾃定义tomcat的⽇志格式
cp /oldboyedu/softwares/apache-tomcat-10.0.20/conf/{server.xml,server.xml-`date +%F`}
# ...(切换到⾏尾修改,⼤概是在133-149之间)
<Host name="tomcat.oldboyedu.com" appBase="webapps"
unpackWARs="true" autoDeploy="true">
<Valve className="org.apache.catalina.valves.AccessLogValve"
directory="logs"
prefix="tomcat.oldboyedu.com_access_log" suffix=".txt"
pattern="{"clientip":"%h","ClientUser":"%l","authenticated":"%u","AccessTime":"%t","request":"%r","status":"%s","SendBytes":"%b","Query?string":"%q","partner":"%{Referer}i","http_user_agent":"%{User-Agent}i"}"/>
</Host>
# 2.修改filebeat的配置⽂件
filebeat.inputs:
- type: log
enabled: true
paths:
- /oldboyedu/softwares/apache-tomcat-10.0.20/logs/*.txt
# 解析message字段的json格式,并放在顶级字段中
json.keys_under_root: true
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200", "http://10.0.0.102:9200", "http://10.0.0.103:9200"]
index: "oldboyedu-linux-tomcat-access-%{+yyyy.MM.dd}"
setup.ilm.enabled: false # 禁⽤索引⽣命周期管理
setup.template.name: "oldboyedu-linux" # 设置索引模板的名称
setup.template.pattern: "oldboyedu-linux*" # 设置索引模板的匹配模式
setup.template.overwrite: true # 覆盖已有的索引模板,如果为true,则会直接覆盖现有的索引模板,如果为false则不覆盖!
setup.template.settings: # 配置索引模板
index.number_of_shards: 3 # 设置分⽚数量
index.number_of_replicas: 0 # 设置副本数量,要求⼩于集群的数量8.多⾏匹配-收集 tomcat 的错误日志
https://www.elastic.co/guide/en/beats/filebeat/current/multiline-examples.html
multiline.match
Specifies how Filebeat combines matching lines into an event. The settings are after or before. The behavior of these settings depends on what you specify for negate:
Setting for negate |
Setting for match |
Result | Example pattern: ^b |
|---|---|---|---|
false |
after |
Consecutive lines that match the pattern are appended to the previous line that doesn’t match. | 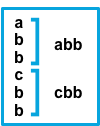 |
false |
before |
Consecutive lines that match the pattern are prepended to the next line that doesn’t match. | 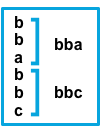 |
true |
after |
Consecutive lines that don’t match the pattern are appended to the previous line that does match. | 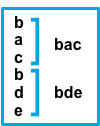 |
true |
before |
Consecutive lines that don’t match the pattern are prepended to the next line that does match. | 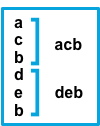 |
The
aftersetting is equivalent topreviousin Logstash, andbeforeis equivalent tonext.
filebeat.inputs:
- type: log
enabled: true
paths:
- /oldboyedu/softwares/apache-tomcat-10.0.20/logs/*.out
# 指定多⾏匹配的类型,可选值为"pattern","count"
multiline.type: pattern
# 指定匹配模式
multiline.pattern: '^\d{2}'
# 下⾯2个参数参考官⽅架构图即可,如上图所示。
multiline.negate: true
multiline.match: after
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200", "http://10.0.0.102:9200", "http://10.0.0.103:9200"]
index: "oldboyedu-linux-tomcat-error-%{+yyyy.MM.dd}"
setup.ilm.enabled: false # 禁⽤索引⽣命周期管理
setup.template.name: "oldboyedu-linux" # 设置索引模板的名称
setup.template.pattern: "oldboyedu-linux*" # 设置索引模板的匹配模式
setup.template.overwrite: true # 覆盖已有的索引模板,如果为true,则会直接覆盖现有的索引模板,如果为false则不覆盖!
setup.template.settings: # 配置索引模板
index.number_of_shards: 3 # 设置分⽚数量
index.number_of_replicas: 0 # 设置副本数量,要求⼩于集群的数量9.多⾏匹配-收集 elasticsearch 的错误日志
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/elasticsearch/oldboyedu-elk-2022.log*
# 指定多⾏匹配的类型,可选值为"pattern","count"
multiline.type: pattern
# 指定匹配模式
multiline.pattern: '^\['
# 下⾯2个参数参考官⽅架构图即可
multiline.negate: true
multiline.match: after
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200", "http://10.0.0.102:9200", "http://10.0.0.103:9200"]
index: "oldboyedu-linux-es-error-%{+yyyy.MM.dd}"
setup.ilm.enabled: false # 禁⽤索引⽣命周期管理
setup.template.name: "oldboyedu-linux" # 设置索引模板的名称
setup.template.pattern: "oldboyedu-linux*" # 设置索引模板的匹配模式
setup.template.overwrite: true # 覆盖已有的索引模板,如果为true,则会直接覆盖现有的索引模板,如果为false则不覆盖!
setup.template.settings: # 配置索引模板
index.number_of_shards: 3 # 设置分⽚数量
index.number_of_replicas: 0 # 设置副本数量,要求⼩于集群的数量10.nginx 错误日志过滤
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log*
tags: ["access"]
# 解析message字段的json格式,并放在顶级字段中
json.keys_under_root: true
- type: log
enabled: true
paths:
- /var/log/nginx/error.log*
tags: ["error"]
include_lines: ['\[error\]']
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200", "http://10.0.0.102:9200", "http://10.0.0.103:9200"]
# index: "oldboyedu-linux-elk-%{+yyyy.MM.dd}"
indices:
- index: "oldboyedu-linux-web-nginx-access-%{+yyyy.MM.dd}"
# 匹配指定字段包含的内容
when.contains:
tags: "access"
- index: "oldboyedu-linux-web-nginx-error-%{+yyyy.MM.dd}"
when.contains:
tags: "error"
setup.ilm.enabled: false # 禁⽤索引⽣命周期管理
setup.template.name: "oldboyedu-linux" # 设置索引模板的名称
setup.template.pattern: "oldboyedu-linux*" # 设置索引模板的匹配模式
setup.template.overwrite: true # 覆盖已有的索引模板
setup.template.settings: # 配置索引模板
index.number_of_shards: 3 # 设置分⽚数量
index.number_of_replicas: 0 # 设置副本数量,要求⼩于集群的数量11.nginx 和 tomcat 同时采集案例
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log*
tags: ["nginx-access"]
json.keys_under_root: true
- type: log
enabled: true
paths:
- /var/log/nginx/error.log*
tags: ["nginx-error"]
include_lines: ['\[error\]']
- type: log
enabled: true
paths:
- /oldboyedu/softwares/apache-tomcat-10.0.20/logs/*.txt
json.keys_under_root: true
tags: ["tomcat-access"]
- type: log
enabled: true
paths:
- /oldboyedu/softwares/apache-tomcat-10.0.20/logs/*.out
multiline.type: pattern
multiline.pattern: '^\d{2}'
multiline.negate: true
multiline.match: after
tags: ["tomcat-error"]
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200", "http://10.0.0.102:9200", "http://10.0.0.103:9200"]
indices:
- index: "oldboyedu-linux-web-nginx-access-%{+yyyy.MM.dd}"
when.contains:
tags: "nginx-access"
- index: "oldboyedu-linux-web-nginx-error-%{+yyyy.MM.dd}"
when.contains:
tags: "nginx-error"
- index: "oldboyedu-linux-web-tomcat-access-%{+yyyy.MM.dd}"
when.contains:
tags: "tomcat-access"
- index: "oldboyedu-linux-web-tomcat-error-%{+yyyy.MM.dd}"
when.contains:
tags: "tomcat-error"
setup.ilm.enabled: false # 禁⽤索引⽣命周期管理
setup.template.name: "oldboyedu-linux" # 设置索引模板的名称
setup.template.pattern: "oldboyedu-linux*" # 设置索引模板的匹配模式
setup.template.overwrite: true # 覆盖已有的索引模板
setup.template.settings: # 配置索引模板
index.number_of_shards: 3 # 设置分⽚数量
index.number_of_replicas: 0 # 设置副本数量,要求⼩于集群的数量12.log 类型切换 filestream 类型注意事项
12.1.filestream 类型 json 解析配置
filebeat.inputs:
- type: filestream
enabled: true
paths:
- /var/log/nginx/access.log*
tags: ["access"]
# 对于filestream类型⽽⾔,不能直接配置json解析,⽽是需要借助解析器实现
# json.keys_under_root: true
# 综上所述,我们就需要使⽤以下的写法实现.
parsers:
# 使 Filebeat能够解码结构化为JSON消息的⽇志。
# Filebeat逐⾏处理⽇志,因此JSON解码仅在每条消息有⼀个JSON对象时才有效。
- ndjson:
# 对message字段进⾏JSON格式解析,并将key放在顶级字段。
keys_under_root: true
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200", "http://10.0.0.102:9200", "http://10.0.0.103:9200"]
index: "oldboyedu-linux-nginx-%{+yyyy.MM.dd}"
setup.ilm.enabled: false
setup.template.name: "oldboyedu-linux"
setup.template.pattern: "oldboyedu-linux*"
setup.template.overwrite: true
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 012.2.filestream 类型多行匹配
filebeat.inputs:
- type: filestream
enabled: true
paths:
- /oldboyedu/softwares/apache-tomcat-10.0.20/logs/*.txt
tags: ["access"]
parsers:
- ndjson:
keys_under_root: true
- type: filestream
enabled: true
paths:
- /oldboyedu/softwares/apache-tomcat-10.0.20/logs/*.out
tags: ["error"]
parsers:
- multiline:
type: pattern
pattern: '^\d{2}'
negate: true
match: after
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200", "http://10.0.0.102:9200", "http://10.0.0.103:9200"]
indices:
- index: "oldboyedu-linux-web-tomcat-access-%{+yyyy.MM.dd}"
when.contains:
tags: "access"
- index: "oldboyedu-linux-web-tomcat-error-%{+yyyy.MM.dd}"
when.contains:
tags: "error"
setup.ilm.enabled: false
setup.template.name: "oldboyedu-linux"
setup.template.pattern: "oldboyedu-linux*"
setup.template.overwrite: true
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 013.收集日志到 redis 服务
13.1.部署 redis
yum -y install epel-release
yum -y install redis13.2.修改配置⽂件
vim /etc/redis.conf
...
bind 0.0.0.0
requirepass oldboyedu13.3.启动 redis 服务
systemctl start redis13.4.其他节点连接测试 redis 环境
redis-cli -a oldboyedu -h 10.0.0.101 -p 6379 --raw -n 513.5.将 filebeat 数据写入到 redis 环境
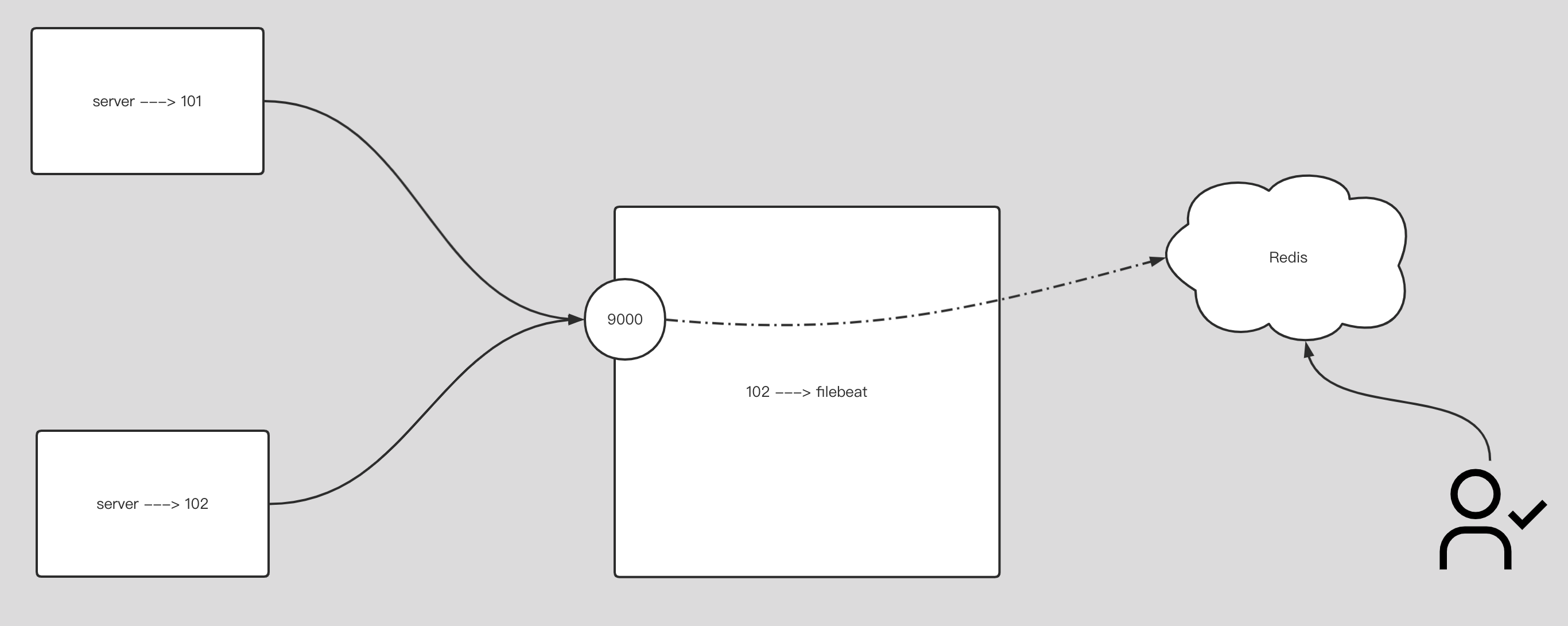
filebeat.inputs:
- type: tcp
host: "0.0.0.0:9000"
output.redis:
hosts: ["10.0.0.101:6379"] # 写⼊redis的主机地址
password: "oldboyedu" # 指定redis的认证⼝令
db: 5 # 指定连接数据库的编号
key: "oldboyedu-linux80-filebeat" # 指定的key值
timeout: 3 # 规定超时时间.13.6.测试写入数据
# 写⼊数据:
echo 33333333333333333333| nc 10.0.0.102 9000
# 查看数据:
[root@elk103.oldboyedu.com ~]# redis-cli -a oldboyedu -h 10.0.0.101 -p
6379 --raw -n 5
.....
10.0.0.101:6379[5]> LRANGE oldboyedu-linux80-filebeat 0 -114.今日作业
# 1. 完成课堂的所有练习;
# 2. 使⽤filebeat收集以下系统⽇志:
/var/log/secure
/var/log/maillog
/var/log/yum.log
/var/log/firewalld
/var/log/cron
/var/log/messages
# 要求如下:
# 1.在同⼀个filebeat配置⽂件中书写;
# 2.将上述6类⽇志分别写⼊不同的索引,索引前缀名称为"oldboyedu-elk-system-log-{xxx}-%{+yyyy.MM.dd}";
# 3.要求副本数量为0,分⽚数量为10;
# 7.17.3版本可能遇到的问题:
# 1.input源配置⼀旦超过4个,写⼊ES时,就可能会复现出部分数据⽆法写⼊的问题;
# 有两种解决⽅案:
# ⽅案⼀: 拆成多个filebeat实例。运⾏多个filebeat实例时需要指定数据路径"--path.data"。
filebeat -e -c ~/config/23-systemLog-to-es.yml --path.data /tmp/filebeat
# ⽅案⼆: ⽇志聚合思路解决问题。
# 1)部署服务
yum -y install rsyslog
# 2)修改配置⽂件
vim /etc/rsyslog.conf
...
$ModLoad imtcp
$InputTCPServerRun 514
...
*.* /var/log/oldboyedu.log
# 3)重启服务并测试
systemctl restart rsyslog
logger "1111"⽅案⼀:filebeat 多实例
filebeat 实例⼀:
filebeat.inputs:
- type: filestream
enabled: true
paths:
- /var/log/firewalld
tags: ["firewalld"]
- type: filestream
enabled: true
paths:
- /var/log/cron
tags: ["cron"]
- type: filestream
enabled: true
paths:
- /var/log/messages
tags: ["message"]
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200", "http://10.0.0.102:9200", "http://10.0.0.103:9200"]
indices:
- index: "oldboyedu-elk-system-log-firewalld-%{+yyyy.MM.dd}"
when.contains:
tags: "firewalld"
- index: "oldboyedu-elk-system-log-cron-%{+yyyy.MM.dd}"
when.contains:
tags: "cron"
- index: "oldboyedu-elk-system-log-message-%{+yyyy.MM.dd}"
when.contains:
tags: "message"
setup.ilm.enabled: false
setup.template.name: "oldboyedu-elk-system-log"
setup.template.pattern: "oldboyedu-elk-system-log*"
setup.template.overwrite: true
setup.template.settings:
index.number_of_shards: 10
index.number_of_replicas: 0filebeat 实例二:
filebeat.inputs:
- type: filestream
enabled: true
paths:
- /var/log/secure
tags: ["secure"]
- type: filestream
enabled: true
paths:
- /var/log/maillog
tags: ["maillog"]
- type: filestream
enabled: true
paths:
- /var/log/yum.log
tags: ["yum"]
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200", "http://10.0.0.102:9200", "http://10.0.0.103:9200"]
indices:
- index: "oldboyedu-elk-system-log-secure-%{+yyyy.MM.dd}"
when.contains:
tags: "secure"
- index: "oldboyedu-elk-system-log-maillog-%{+yyyy.MM.dd}"
when.contains:
tags: "maillog"
- index: "oldboyedu-elk-system-log-yum-%{+yyyy.MM.dd}"
when.contains:
tags: "yum"
setup.ilm.enabled: false
setup.template.name: "oldboyedu-elk-system-log"
setup.template.pattern: "oldboyedu-elk-system-log*"
setup.template.overwrite: true
setup.template.settings:
index.number_of_shards: 10
index.number_of_replicas: 0方案二:基于 rsyslog 案例
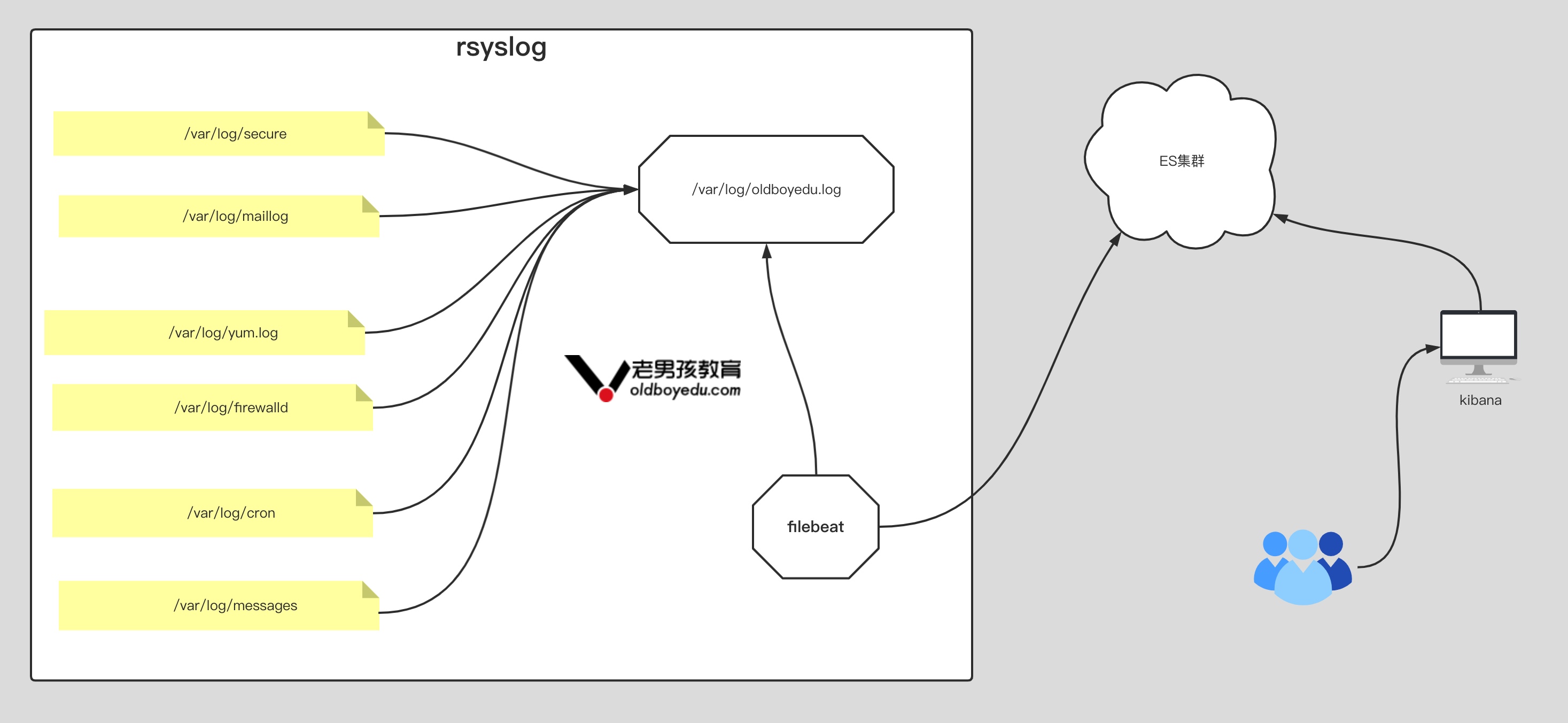
filebeat.inputs:
- type: filestream
enabled: true
paths:
- /var/log/oldboyedu.log
tags: ["rsyslog"]
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200", "http://10.0.0.102:9200", "http://10.0.0.103:9200"]
indices:
- index: "oldboyedu-elk-system-rsyslog--%{+yyyy.MM.dd}"
when.contains:
tags: "rsyslog"
setup.ilm.enabled: false
setup.template.name: "oldboyedu-elk-system-log"
setup.template.pattern: "oldboyedu-elk-system-log*"
setup.template.overwrite: true
setup.template.settings:
index.number_of_shards: 10
index.number_of_replicas: 0部署 logstash 环境及基础使用
1.部署 logstash 环境
yum -y localinstall logstash-7.17.3-x86_64.rpm
ln -sv /usr/share/logstash/bin/logstash /usr/local/bin/
# 下载地址: https://www.elastic.co/downloads/past-releases#logstash2.修改 logstash 的配置⽂件
# (1)编写配置⽂件
cat > conf.d/01-stdin-to-stdout.conf <<EOF
input {
stdin {}
}
output {
stdout {}
}
EOF
# (2)检查配置⽂件语法
logstash -tf conf.d/01-stdin-to-stdout.conf
# (3)启动logstash实例
logstash -f conf.d/01-stdin-to-stdout.conf3.input 插件基于 file 案例
input {
file {
# 指定收集的路径
path => ["/tmp/test/*.txt"]
# 指定⽂件的读取位置,仅在".sincedb*"⽂件中没有记录的情况下⽣效!
start_position => "beginning"
# start_position => "end"
}
}
output {
stdout {}
}4.input 插件基于 tcp 案例
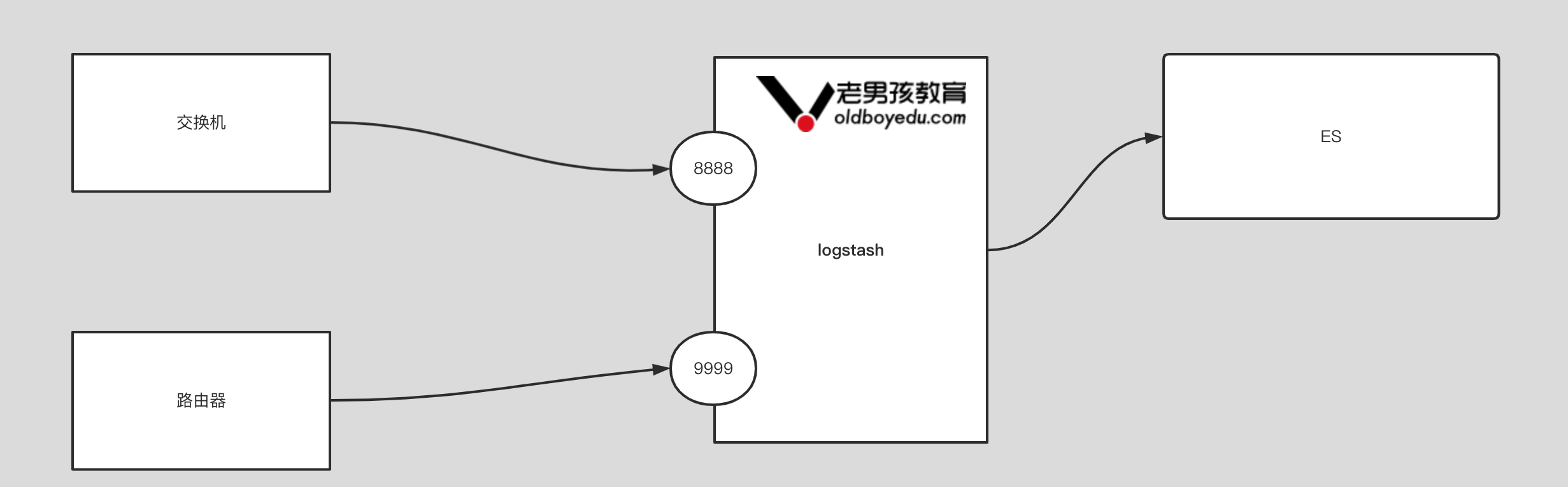
input {
tcp {
port => 8888
}
tcp {
port => 9999
}
}
output {
stdout {}
}5.input 插件基于 http 案例
input {
http {
port => 8888
}
http {
port => 9999
}
}
output {
stdout {}
}6.input 插件基于 redis 案例
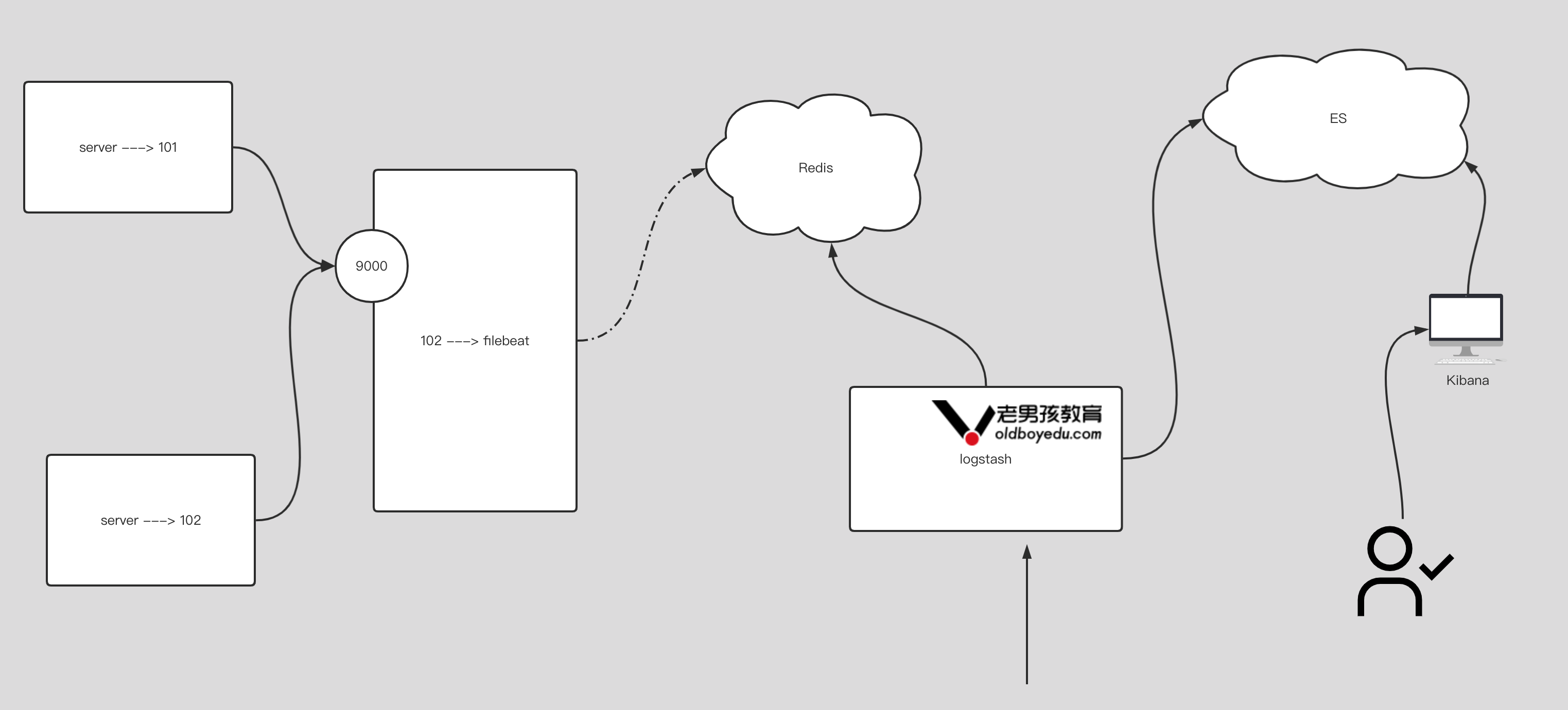
# filebeat的配置:(仅供参考)
filebeat.inputs:
- type: tcp
host: "0.0.0.0:9000"
output.redis:
hosts: ["10.0.0.101:6379"] # 写⼊redis的主机地址
password: "oldboyedu" # 指定redis的认证⼝令
db: 5 # 指定连接数据库的编号
key: "oldboyedu-linux80-filebeat" # 指定的key值
timeout: 3 # 规定超时时间.
# logstash的配置:
input {
redis {
data_type => "list" # 指定的是REDIS的键(key)的类型
db => 5 # 指定数据库的编号,默认值是0号数据库
host => "10.0.0.101" # 指定数据库的ip地址,默认值是localhost
port => 6379 # 指定数据库的端⼝号,默认值为6379
password => "oldboyedu" # 指定redis的认证密码
key => "oldboyedu-linux80-filebeat" # 指定从redis的哪个key取数据
}
}
output {
stdout {}
}7.input 插件基于 beats 案例
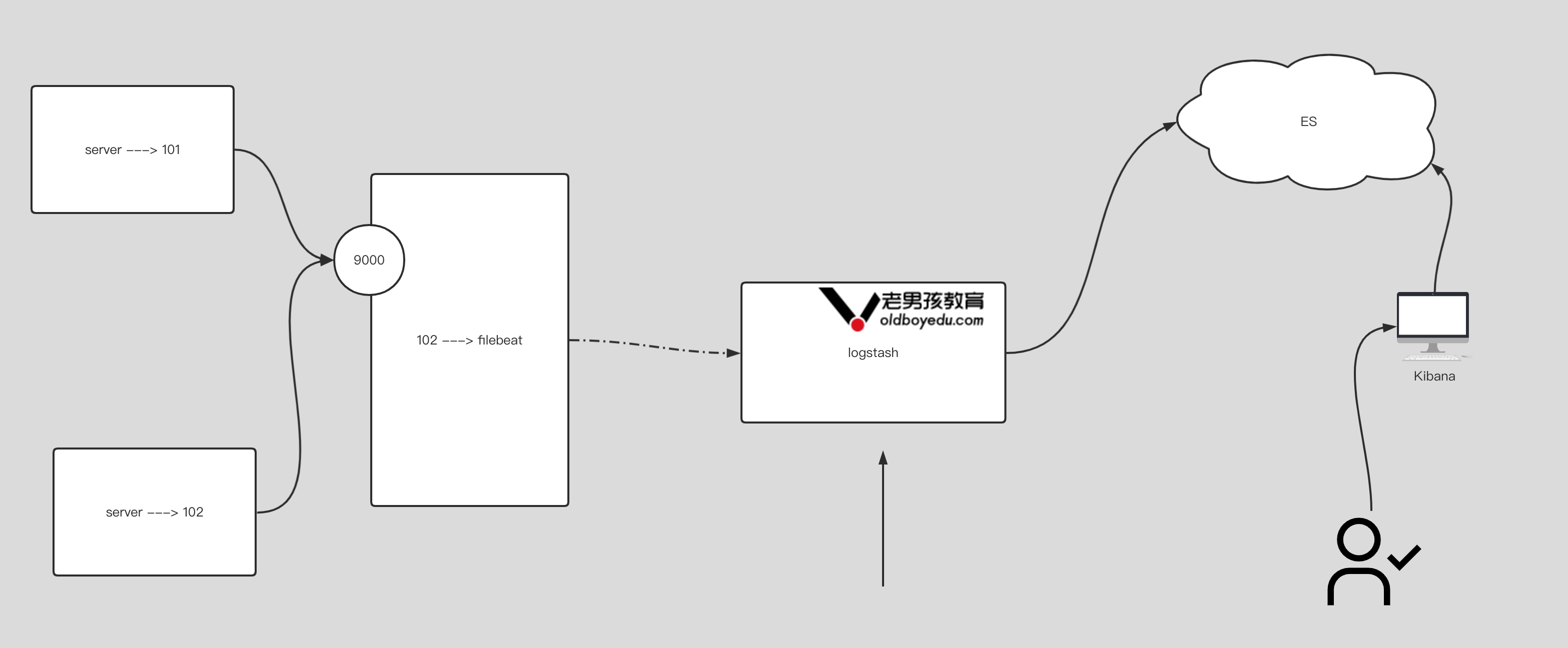
# filbeat配置:
filebeat.inputs:
- type: tcp
host: "0.0.0.0:9000"
output.logstash:
hosts: ["10.0.0.101:5044"]
# logstsh配置:
input {
beats {
port => 5044
}
}
output {
stdout {}
}8.output 插件基于 redis 案例

input {
tcp {
port => 9999
}
}
output {
stdout {}
redis {
host => "10.0.0.101" # 指定redis的主机地址
port => "6379" # 指定redis的端⼝号
db => 10 # 指定redis数据库编号
password => "oldboyedu" # 指定redis的密码
data_type => "list" # 指定写⼊数据的key类型
key => "oldboyedu-linux80-logstash" # 指定的写⼊的key名称
}
}9.output 插件基于 file 案例
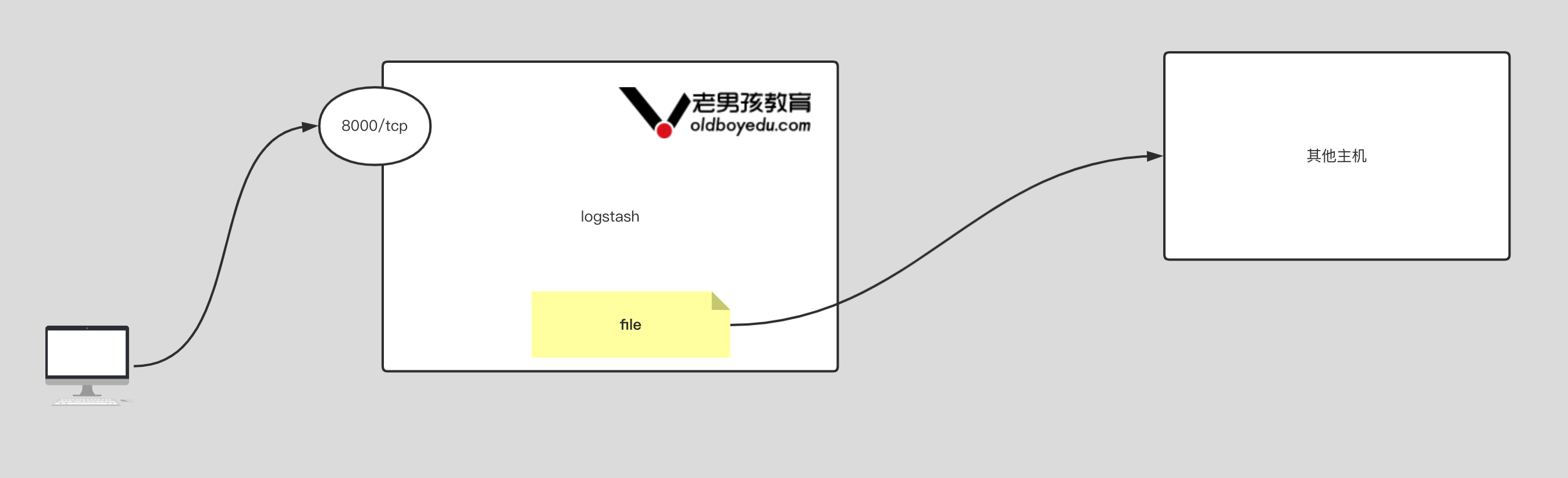
input {
tcp {
port => 9999
}
}
output {
stdout {}
file {
# 指定磁盘的落地位置
path => "/tmp/oldboyedu-linux80-logstash.log"
}
}10.logstash 综合案例
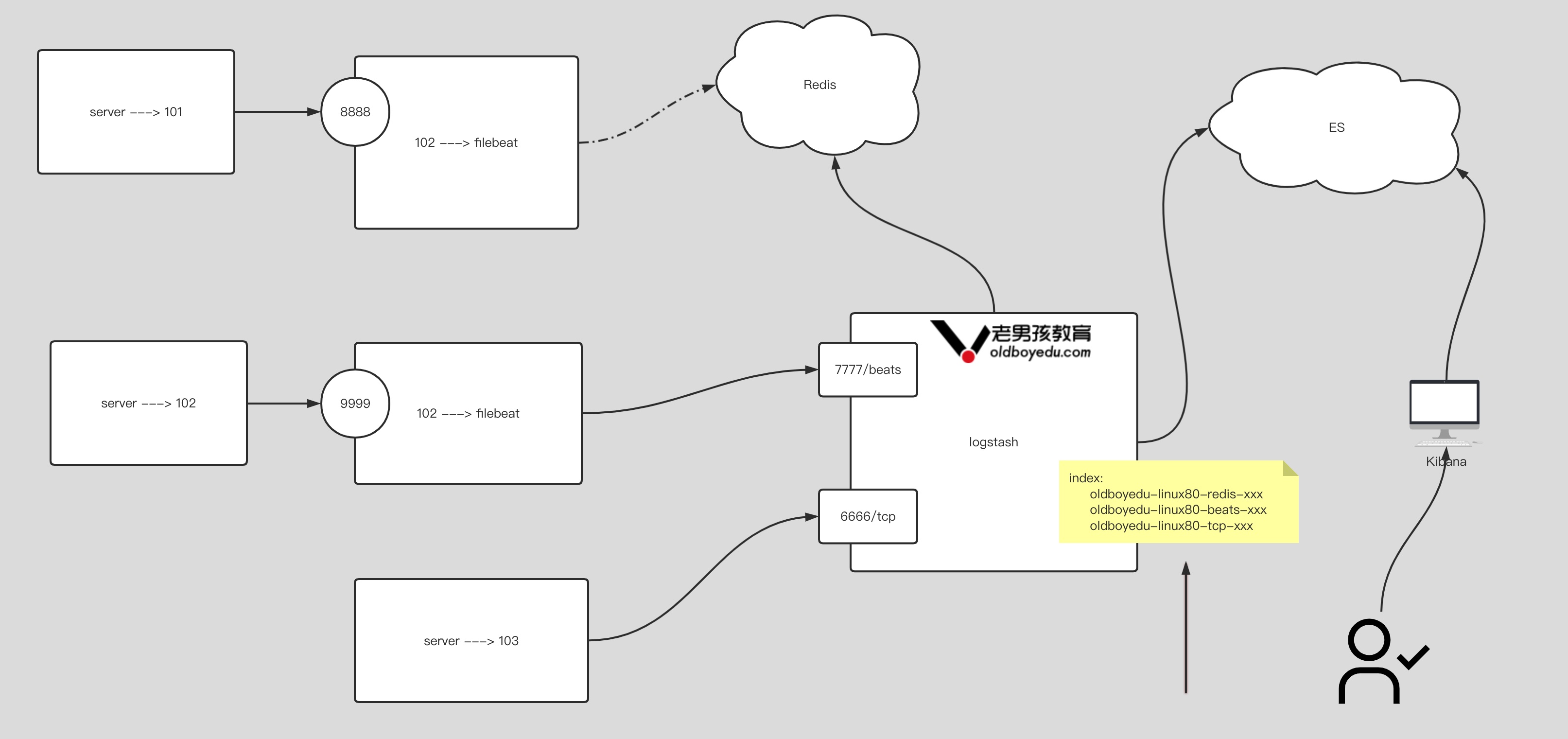
1.filebeat-to-redis 参考笔记
filebeat.inputs:
- type: tcp
host: "0.0.0.0:8888"
output.redis:
hosts: ["10.0.0.101:6379"] # 写⼊redis的主机地址
password: "oldboyedu" # 指定redis的认证⼝令
key: "oldboyedu-linux80-filebeat" # 指定的key值
timeout: 3 # 规定超时时间.2.filebeat-to-logstash 参考笔记
filebeat.inputs:
- type: tcp
host: "0.0.0.0:9999"
output.logstash:
hosts: ["10.0.0.101:7777"]3.logstash 配置⽂件
input {
tcp {
type => "oldboyedu-tcp"
port => 6666
}
beats {
type => "oldboyedu-beat"
port => 7777
}
redis {
type => "oldboyedu-redis"
data_type => "list"
db => 5
host => "10.0.0.101"
port => 6379
password => "oldboyedu"
key => "oldboyedu-linux80-filebeat"
}
}
output {
stdout {}
if [type] == "oldboyedu-tcp" {
elasticsearch {
hosts => ["10.0.0.101:9200","10.0.0.102:9200","10.0.0.103:9200"]
index => "oldboyedu-linux80-tcp-%{+YYYY.MM.dd}"
}
} else if [type] == "oldboyedu-beat" {
elasticsearch {
hosts => ["10.0.0.101:9200","10.0.0.102:9200","10.0.0.103:9200"]
index => "oldboyedu-linux80-beat-%{+YYYY.MM.dd}"
}
} else if [type] == "oldboyedu-redis" {
elasticsearch {
hosts => ["10.0.0.101:9200","10.0.0.102:9200","10.0.0.103:9200"]
index => "oldboyedu-linux80-redis-%{+YYYY.MM.dd}"
}
} else {
elasticsearch {
hosts => ["10.0.0.101:9200","10.0.0.102:9200","10.0.0.103:9200"]
index => "oldboyedu-linux80-other-%{+YYYY.MM.dd}"
}
}
}11.今日作业
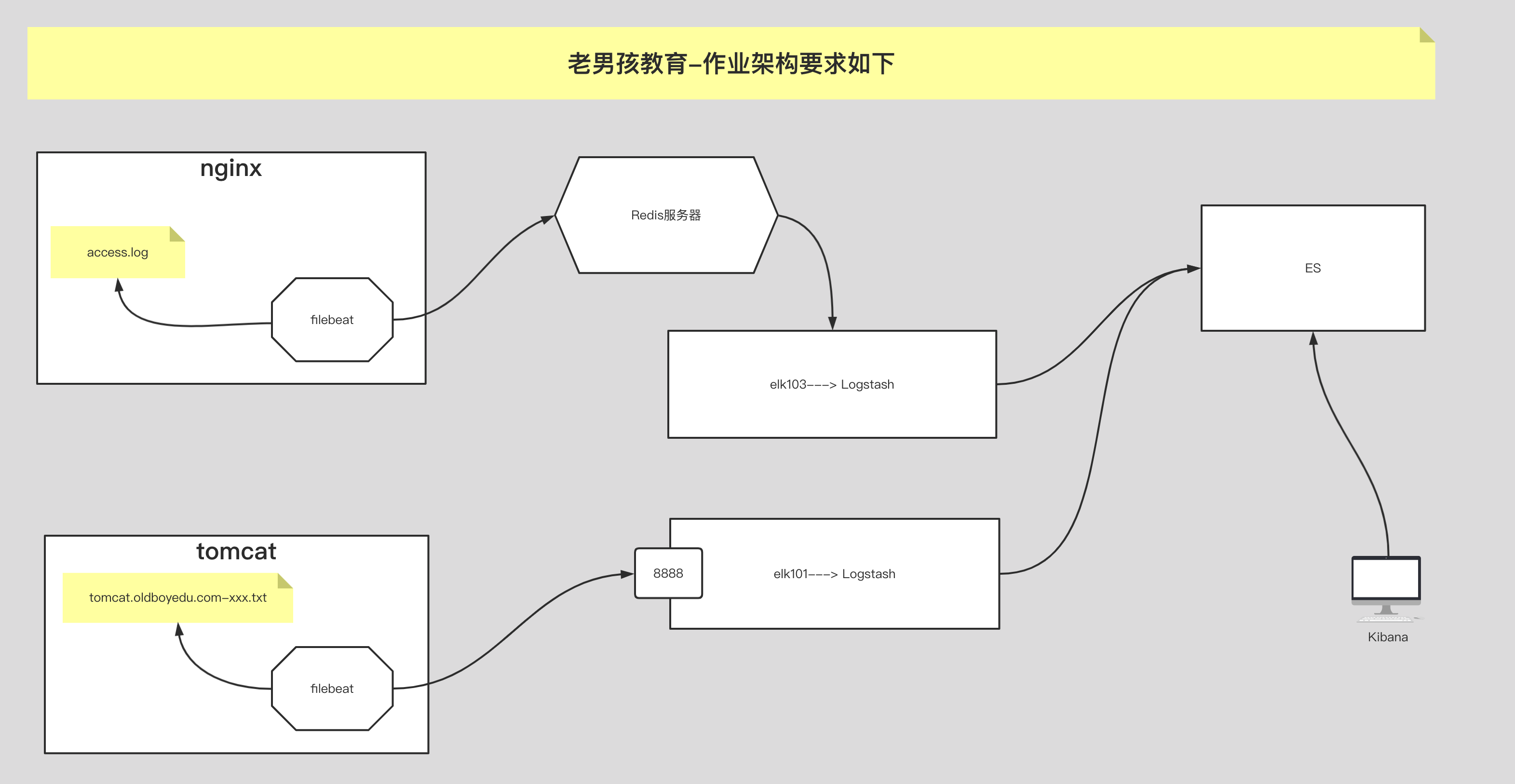
(1)完成课堂的所有练习,要求能够⼿绘架构图;
(2)如上图所示,按照上述要求完成作业;11.1 运行一个 logsash 版本
[root@elk101.oldboyedu.com ~]$ cat config-logstash/11-many-to-es.conf
input {
beats {
port => 8888
}
redis {
data_type => "list"
db => 8
host => "10.0.0.101"
port => 6379
password => "oldboyedu"
key => "oldboyedu-linux80-filebeat"
}
}
output {
stdout {}
elasticsearch {
hosts => ["10.0.0.101:9200","10.0.0.102:9200","10.0.0.103:9200"]
index => "oldboyedu-linux80-logstash-%{+YYYY.MM.dd}"
}
}
[root@elk101.oldboyedu.com ~]$
[root@elk101.oldboyedu.com ~]$ logstash -f config-logstash/11-many-to-es.conf11.2.运行两个 logstash 版本
# logstash接受redis示例:
[root@elk101.oldboyedu.com ~]$ cat config-logstash/13-redis-to-es.conf
input {
redis {
data_type => "list"
db => 8
host => "10.0.0.101"
port => 6379
password => "oldboyedu"
key => "oldboyedu-linux80-filebeat"
}
}
output {
stdout {}
elasticsearch {
hosts => ["10.0.0.101:9200","10.0.0.102:9200","10.0.0.103:9200"]
index => "oldboyedu-linux80-logstash-%{+YYYY.MM.dd}"
}
}
[root@elk101.oldboyedu.com ~]$
[root@elk101.oldboyedu.com ~]$ logstash -f config-logstash/13-redis-to-es.conf
#logstash接受beats示例:
[root@elk101.oldboyedu.com ~]$ cat config-logstash/12-beat-to-es.conf
input {
beats {
port => 8888
}
}
output {
stdout {}
elasticsearch {
hosts => ["10.0.0.101:9200","10.0.0.102:9200","10.0.0.103:9200"]
index => "oldboyedu-linux80-logstash-%{+YYYY.MM.dd}"
}
}
[root@elk101.oldboyedu.com ~]$
[root@elk101.oldboyedu.com ~]$ logstash -f config-logstash/12-beat-to-es.conf --path.data /tmp/logstashlogstash 企业级插件案例(ELFK 架构)
1.gork 插件概述
Grok 是将⾮结构化⽇志数据解析为结构化和可查询的好⽅法。底层原理是基于正则匹配任意⽂本格式。
该⼯具⾮常适合 syslog ⽇志、apache 和其他⽹络服务器⽇志、mysql ⽇志,以及通常为⼈类⽽⾮计算机消耗⽽编写的任何⽇志格式。
内置 120 种匹配模式,当然也可以⾃定义匹配模式:
https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
2.使⽤ grok 内置的正则案例 1
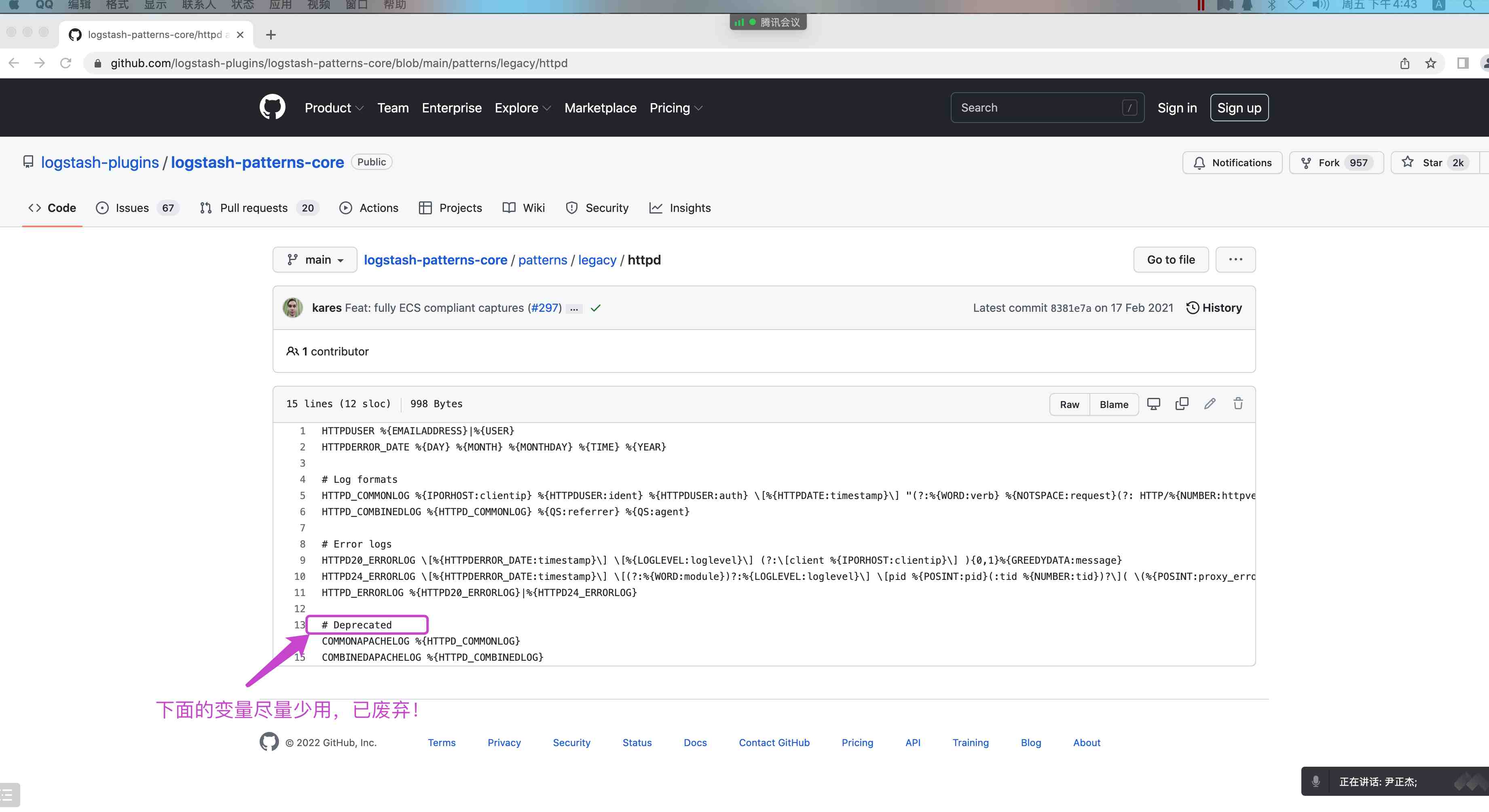
[root@elk101.oldboyedu.com ~]$ cat config-logstash/14-beat-grok-es.conf
input {
beats {
port => 8888
}
}
filter {
grok {
match => {
# "message" => "%{COMBINEDAPACHELOG}"
# 上⾯的""变量官⽅github上已经废弃,建议使⽤下⾯的匹配模式
# https://github.com/logstash-plugins/logstash-patterns-core/blob/main/patterns/legacy/httpd
"message" => "%{HTTPD_COMMONLOG}"
}
}
}
output {
stdout {}
elasticsearch {
hosts => ["10.0.0.101:9200","10.0.0.102:9200","10.0.0.103:9200"]
index => "oldboyedu-linux80-logstash-%{+YYYY.MM.dd}"
}
}
[root@elk101.oldboyedu.com ~]$
[root@elk101.oldboyedu.com ~]$ logstash -rf config-logstash/14-beat-grok-es.conf3.使用 grok 内置的正则案例 2
[root@elk101.oldboyedu.com ~]$ cat config-logstash/15-stdin-grok-stdout.conf
input {
stdin {}
}
filter {
grok {
match => {
"message" => "%{IP:oldboyedu-client} %{WORD:oldboyedu-method} %{URIPATHPARAM:oldboyedu-request} %{NUMBER:oldboyedu-bytes} %{NUMBER:oldboyedu-duration}"
}
}
}
output {
stdout {}
}
[root@elk101.oldboyedu.com ~]$
[root@elk101.oldboyedu.com ~]$ logstash -f config-logstash/15-stdin-grok-stdout.conf
# 温馨提示:(如下图所示,按照要求输⼊数据)
55.3.244.1 GET /index.html 15824 0.043
10.0.0.103 POST /oldboyedu.html 888888 5.20
# 参考地址:
https://github.com/logstash-plugins/logstash-patterns-core/tree/main/patterns/legacy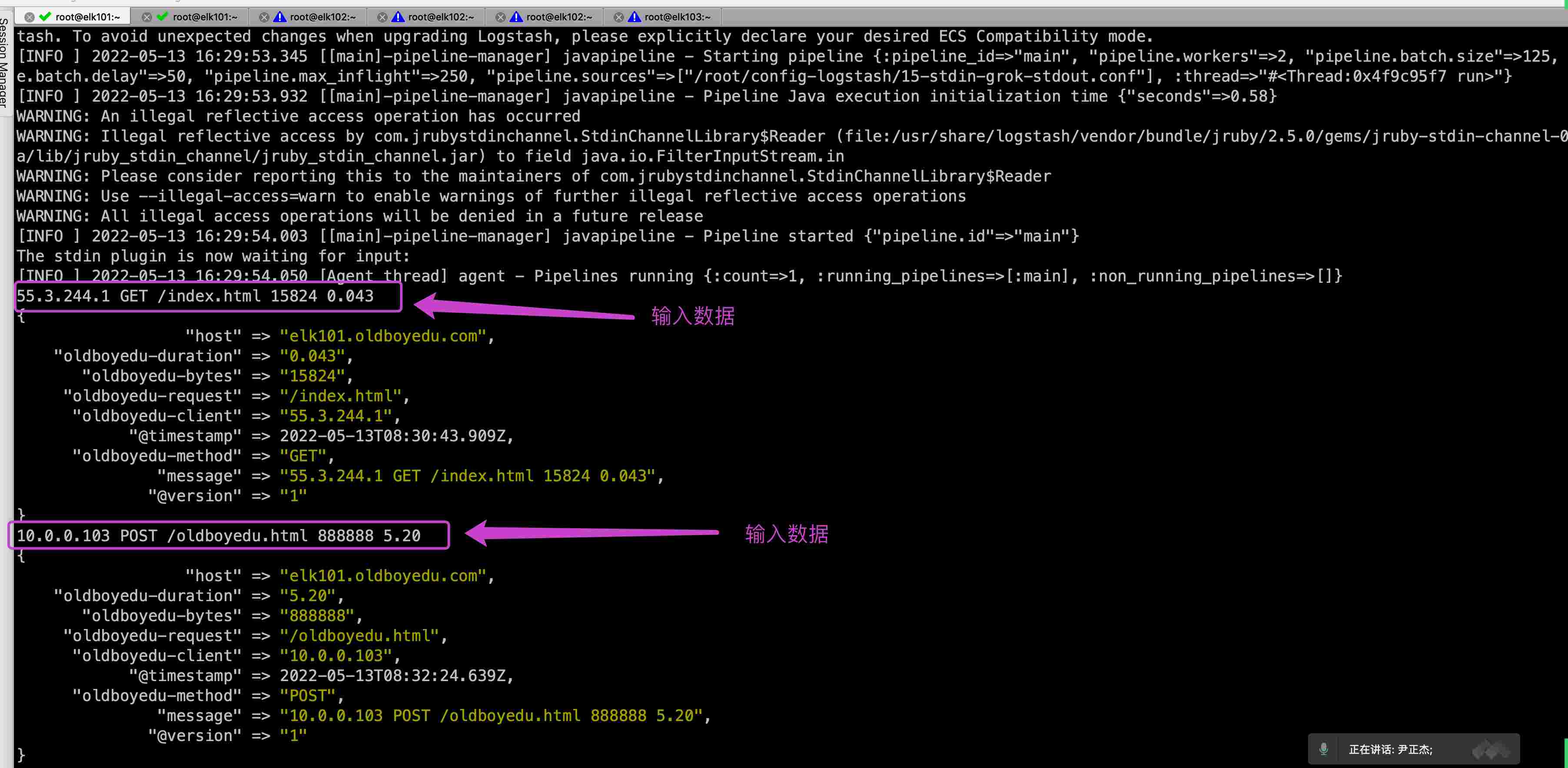
4.使用 grop 自定义的正则案例
[root@elk101.oldboyedu.com ~]$ cat config-logstash/16-stdin-grok_custom_patterns-stdout.conf
input {
stdin {}
}
filter {
grok {
# 指定匹配模式的⽬录,可以使⽤绝对路径哟~
# 在./patterns⽬录下随便创建⼀个⽂件,并写⼊以下匹配模式
# POSTFIX_QUEUEID [0-9A-F]{10,11}
# OLDBOYEDU_LINUX80 [\d]{3}
patterns_dir => ["./patterns"]
# 匹配模式
# 测试数据为: Jan 1 06:25:43 mailserver14 postfix/cleanup[21403]:BEF25A72965: message-id=<20130101142543.5828399CCAF@mailserver14.example.com>
# match => { "message" => "%{SYSLOGBASE} %{POSTFIX_QUEUEID:queue_id}: %{GREEDYDATA:syslog_message}" }
# 测试数据为: ABCDE12345678910 ---> 333FGHIJK
match => { "message" => "%{POSTFIX_QUEUEID:oldboyedu_queue_id} ---> %{OLDBOYEDU_LINUX80:oldboyedu_linux80_elk}" }
}
}
output {
stdout {}
}
[root@elk101.oldboyedu.com ~]$
[root@elk101.oldboyedu.com ~]$ logstash -f config-logstash/16-stdin-grok_custom_patterns-stdout.conf5.filter 插件通用字段案例
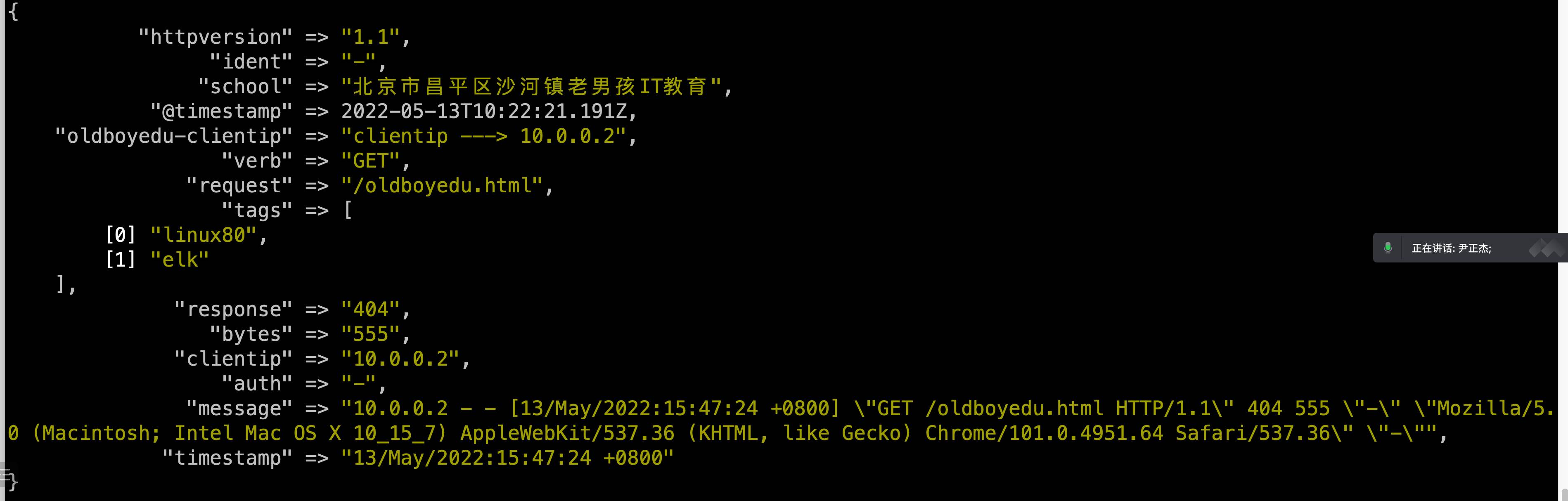
[root@elk101.oldboyedu.com ~]$ cat config-logstash/17-beat-grok-es.conf
input {
beats {
port => 8888
}
}
filter {
grok {
match => {
# "message" => "%{COMBINEDAPACHELOG}"
# 上⾯的""变量官⽅github上已经废弃,建议使⽤下⾯的匹配模式
# https://github.com/logstash-plugins/logstash-patterns-core/blob/main/patterns/legacy/httpd
"message" => "%{HTTPD_COMMONLOG}"
}
# 移除指定的字段
remove_field => [ "host", "@version", "ecs","tags","agent","input", "log" ]
# 添加指定的字段
add_field => {
"school" => "北京市昌平区沙河镇⽼男孩IT教育"
"oldboyedu-clientip" => "clientip ---> %{clientip}"
}
# 添加tag
add_tag => [ "linux80","zookeeper","kafka","elk" ]
# 移除tag
remove_tag => [ "zookeeper", "kafka" ]
# 创建插件的唯⼀ID,如果不创建则系统默认⽣成
id => "nginx"
}
}
output {
stdout {}
# elasticsearch {
# hosts => ["10.0.0.101:9200","10.0.0.102:9200","10.0.0.103:9200"]
# index => "oldboyedu-linux80-logstash-%{+YYYY.MM.dd}"
# }
}
[root@elk101.oldboyedu.com ~]$
[root@elk101.oldboyedu.com ~]$
[root@elk101.oldboyedu.com ~]$ logstash -rf config-logstash/17-beat-grok-es.conf6.date 插件修改写入 ES 的时间
[root@elk101.oldboyedu.com ~]$ cat config-logstash/18-beat-grok_date-es.conf
input {
beats {
port => 8888
}
}
filter {
grok {
match => {
# "message" => "%{COMBINEDAPACHELOG}"
# 上⾯的""变量官⽅github上已经废弃,建议使⽤下⾯的匹配模式
# https://github.com/logstash-plugins/logstash-patterns-core/blob/main/patterns/legacy/httpd
"message" => "%{HTTPD_COMMONLOG}"
}
# 移除指定的字段
remove_field => [ "host", "@version", "ecs","tags","agent","input", "log" ]
# 添加指定的字段
add_field => {
"school" => "北京市昌平区沙河镇⽼男孩IT教育"
}
}
date {
# 匹配时间字段并解析,值得注意的是,logstash的输出时间可能会错8⼩时,但写⼊es但数据是准确的!
# "13/May/2022:15:47:24 +0800", 以下2种match写法均可!
# match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
# 当然,我们也可以不对时区字段进⾏解析,⽽是使⽤"timezone"指定时区哟!
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss +0800"]
# 设置时区字段为UTC时间,写⼊ES的数据时间是不准确的
# timezone => "UTC"
# 建议⼤家设置为"Asia/Shanghai",写⼊ES的数据是准确的!
timezone => "Asia/Shanghai"
# 将匹配到到时间字段解析后存储到⽬标字段,若不指定,则默认字段为"@timestamp"字段
target => "oldboyedu-linux80-nginx-access-time"
}
}
output {
stdout {}
elasticsearch {
hosts => ["10.0.0.101:9200","10.0.0.102:9200","10.0.0.103:9200"]
index => "oldboyedu-linux80-logstash-%{+YYYY.MM.dd}"
}
}
[root@elk101.oldboyedu.com ~]$ logstash -rf config-logstash/18-beat-grok_date-es.conf7.geoip 分析源地址的地址位置
[root@elk101.oldboyedu.com ~]$ cat config-logstash/19-beat-grok_date_geoip-es.conf
input {
beats {
port => 8888
}
}
filter {
grok {
match => {
"message" => "%{HTTPD_COMMONLOG}"
}
remove_field => [ "host", "@version", "ecs","tags","agent","input", "log" ]
add_field => {
"school" => "北京市昌平区沙河镇⽼男孩IT教育"
}
}
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
timezone => "Asia/Shanghai"
target => "oldboyedu-linux80-nginx-access-time"
}
geoip {
# 指定基于哪个字段分析IP地址
source => "clientip"
# 如果期望查看指定的字段,则可以在这⾥配置即可,若不设置,表示显示所有的查询字段.
fields => ["city_name","country_name","ip"]
# 指定geoip的输出字段,如果想要对多个IP地址进⾏分析,则该字段很有⽤哟~
target => "oldboyedu-linux80"
}
}
output {
stdout {}
elasticsearch {
hosts => ["10.0.0.101:9200","10.0.0.102:9200","10.0.0.103:9200"]
index => "oldboyedu-linux80-logstash-%{+YYYY.MM.dd}"
}
}
[root@elk101.oldboyedu.com ~]$
[root@elk101.oldboyedu.com ~]$ logstash -rf config-logstash/19-beat-grok_date_geoip-es.conf8.useragent 分析客户端的设备类型
[root@elk101.oldboyedu.com ~]# cat config-logstash/20-beat-grok_date_geoip_useragent-es.conf
input {
beats {
port => 8888
}
}
filter {
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
timezone => "Asia/Shanghai"
target => "oldboyedu-linux80-nginx-access-time"
}
mutate {
add_field => {
"school" => "北京市昌平区沙河镇⽼男孩IT教育"
}
remove_field => [ "agent", "host", "@version", "ecs","tags","input", "log" ]
}
geoip {
source => "clientip"
fields => ["city_name","country_name","ip"]
target => "oldboyedu-linux80-geoip"
}
useragent {
# 指定客户端的设备相关信息的字段
source => "http_user_agent"
# 将分析的数据存储在⼀个指定的字段中,若不指定,则默认存储在target字段中。
target => "oldboyedu-linux80-useragent"
}
}
output {
stdout {}
elasticsearch {
hosts => ["10.0.0.101:9200","10.0.0.102:9200","10.0.0.103:9200"]
index => "oldboyedu-linux80-logstash-%{+YYYY.MM.dd}"
}
}
[root@elk101.oldboyedu.com ~]$
[root@elk101.oldboyedu.com ~]$ logstash -rf config-logstash/20-beat-grok_date_geoip_useragent-es.conf9.mutate 组件数据准备-python 脚本
cat > generate_log.py <<EOF
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# @author : oldboyedu-linux80
import datetime
import random
import logging
import time
import sys
LOG_FORMAT = "%(levelname)s %(asctime)s [com.oldboyedu.%(module)s] - %(message)s "
DATE_FORMAT = "%Y-%m-%d %H:%M:%S"
# 配置root的logging.Logger实例的基本配置
logging.basicConfig(level=logging.INFO, format=LOG_FORMAT,datefmt=DATE_FORMAT, filename=sys.argv[1], filemode='a',)
actions = ["浏览⻚⾯", "评论商品", "加⼊收藏", "加⼊购物⻋", "提交订单", "使⽤优惠券", "领取优惠券","搜索", "查看订单", "付款", "清空购物⻋"]
while True:
time.sleep(random.randint(1, 5))
user_id = random.randint(1, 10000)
# 对⽣成的浮点数保留2位有效数字.
price = round(random.uniform(15000, 30000),2)
action = random.choice(actions)
svip = random.choice([0,1])
logging.info("DAU|{0}|{1}|{2}|{3}".format(user_id,action,svip,price))
EOF
$ nohup python generate_log.py /tmp/app.log &>/dev/null &9.mutate 组件常⽤字段案例

[root@elk101.oldboyedu.com ~]# cat config-logstash/21-mutate.conf
input {
beats {
port => 8888
}
}
filter {
mutate {
add_field => {
"school" => "北京市昌平区沙河镇⽼男孩IT教育"
}
remove_field => [ "@timestamp", "agent", "host", "@version", "ecs","tags","input", "log" ]
}
mutate {
# 对"message"字段内容使⽤"|"进⾏切分。
split => {
"message" => "|"
}
}
mutate {
# 添加字段,其中引⽤到了变量
add_field => {
"user_id" => "%{[message][1]}"
"action" => "%{[message][2]}"
"svip" => "%{[message][3]}"
"price" => "%{[message][4]}"
}
}
mutate {
strip => ["svip"]
}
mutate {
# 将指定字段转换成相应对数据类型.
convert => {
"user_id" => "integer"
"svip" => "boolean"
"price" => "float"
}
}
mutate {
# 将"price"字段拷⻉到"oldboyedu-linux80-price"字段中.
copy => { "price" => "oldboyedu-linux80-price" }
}
mutate {
# 修改字段到名称
rename => { "svip" => "oldboyedu-ssvip" }
}
mutate {
# 替换字段的内容
replace => { "message" => "%{message}: My new message" }
}
mutate {
# 将指定字段的字⺟全部⼤写
uppercase => [ "message" ]
}
}
output {
stdout {}
elasticsearch {
hosts => ["10.0.0.101:9200","10.0.0.102:9200","10.0.0.103:9200"]
index => "oldboyedu-linux80-logstash-%{+YYYY.MM.dd}"
}
}
[root@elk101.oldboyedu.com ~]$
[root@elk101.oldboyedu.com ~]$ logstash -rf config-logstash/21-mutate.conf10.logstash 的多 if 分支案例
[root@elk101.oldboyedu.com ~]# cat config-logstash/22-beats_tcp-filter-es.conf
input {
beats {
type => "oldboyedu-beats"
port => 8888
}
tcp {
type => "oldboyedu-tcp"
port => 9999
}
tcp {
type => "oldboyedu-tcp-new"
port => 7777
}
http {
type => "oldboyedu-http"
port => 6666
}
file {
type => "oldboyedu-file"
path => "/tmp/apps.log"
}
}
filter {
mutate {
add_field => {
"school" => "北京市昌平区沙河镇⽼男孩IT教育"
}
}
if [type] == ["oldboyedu-beats","oldboyedu-tcp-new","oldboyedu-http"]{
mutate {
remove_field => [ "agent", "host", "@version", "ecs","tags","input", "log" ]
}
geoip {
source => "clientip"
target => "oldboyedu-linux80-geoip"
}
useragent {
source => "http_user_agent"
target => "oldboyedu-linux80-useragent"
}
} else if [type] == "oldboyedu-file" {
mutate {
add_field => {
"class" => "oldboyedu-linux80"
"address" => "北京昌平区沙河镇⽼男孩IT教育"
"hobby" => ["LOL","王者荣耀"]
}
remove_field => ["host","@version","school"]
}
} else {
mutate {
remove_field => ["port","@version","host"]
}
mutate {
split => {
"message" => "|"
}
add_field => {
"user_id" => "%{[message][1]}"
"action" => "%{[message][2]}"
"svip" => "%{[message][3]}"
"price" => "%{[message][4]}"
}
# 利⽤完message字段后,在删除是可以等!注意代码等执⾏顺序!
remove_field => ["message"]
strip => ["svip"]
}
mutate {
convert => {
"user_id" => "integer"
"svip" => "boolean"
"price" => "float"
}
}
}
}
output {
stdout {}
if [type] == "oldboyedu-beats" {
elasticsearch {
hosts => ["10.0.0.101:9200","10.0.0.102:9200","10.0.0.103:9200"]
index => "oldboyedu-linux80-logstash-beats"
}
} else {
elasticsearch {
hosts => ["10.0.0.101:9200","10.0.0.102:9200","10.0.0.103:9200"]
index => "oldboyedu-linux80-logstash-tcp"
}
}
}
[root@elk101.oldboyedu.com ~]$
[root@elk101.oldboyedu.com ~]$ logstash -rf config-logstash/22-beats_tcp-filter-es.conf11.今日作业
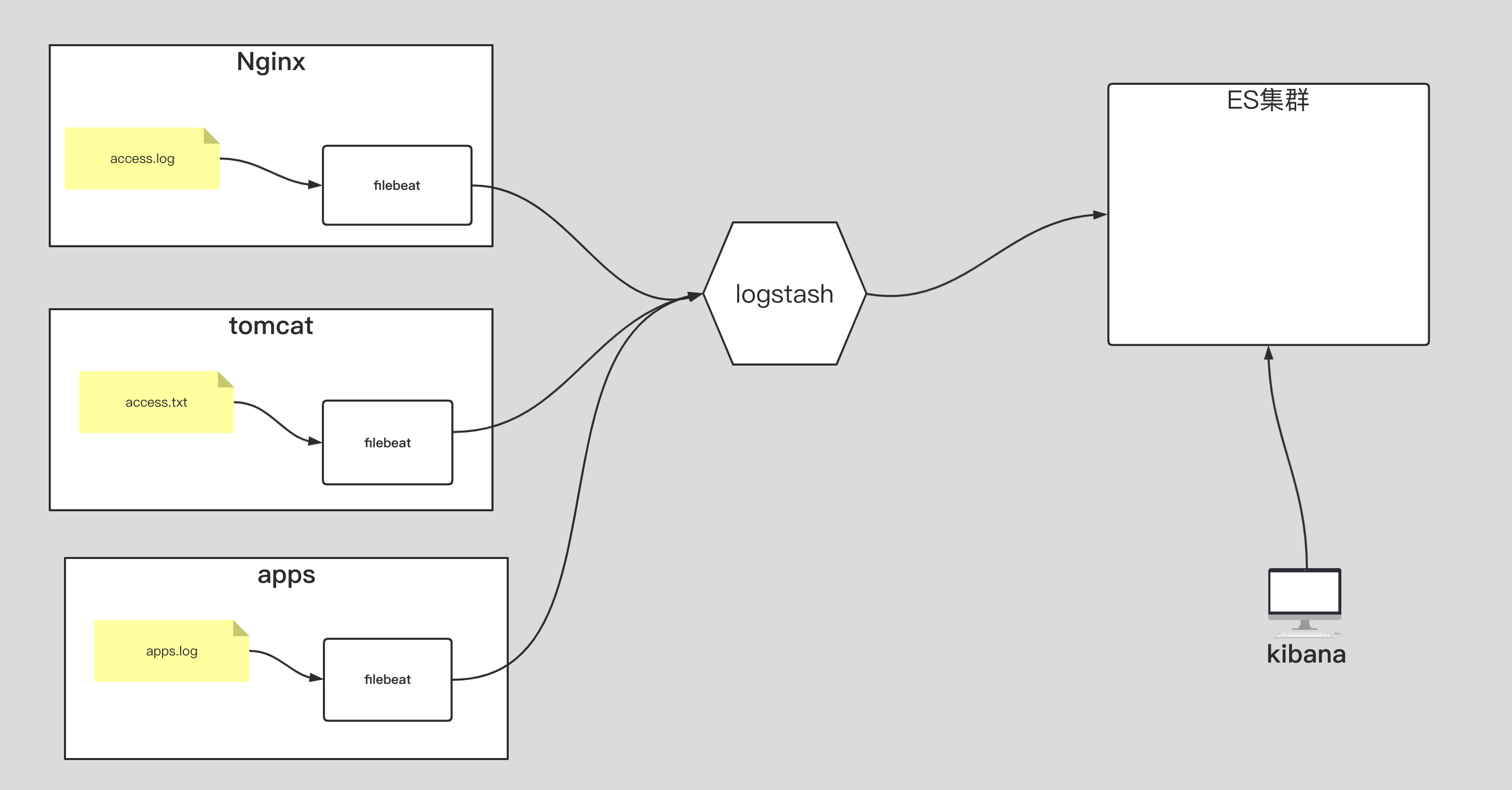
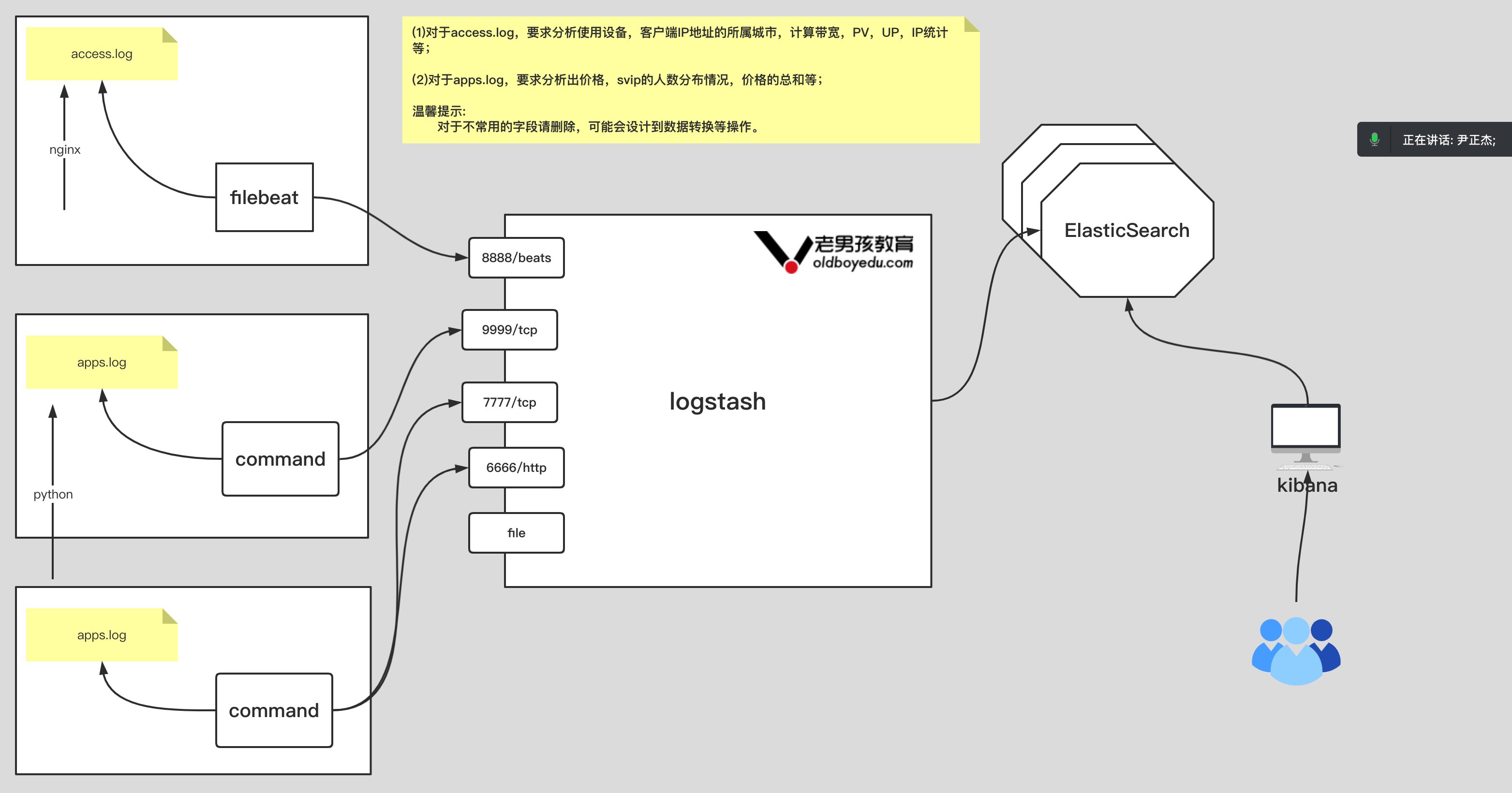
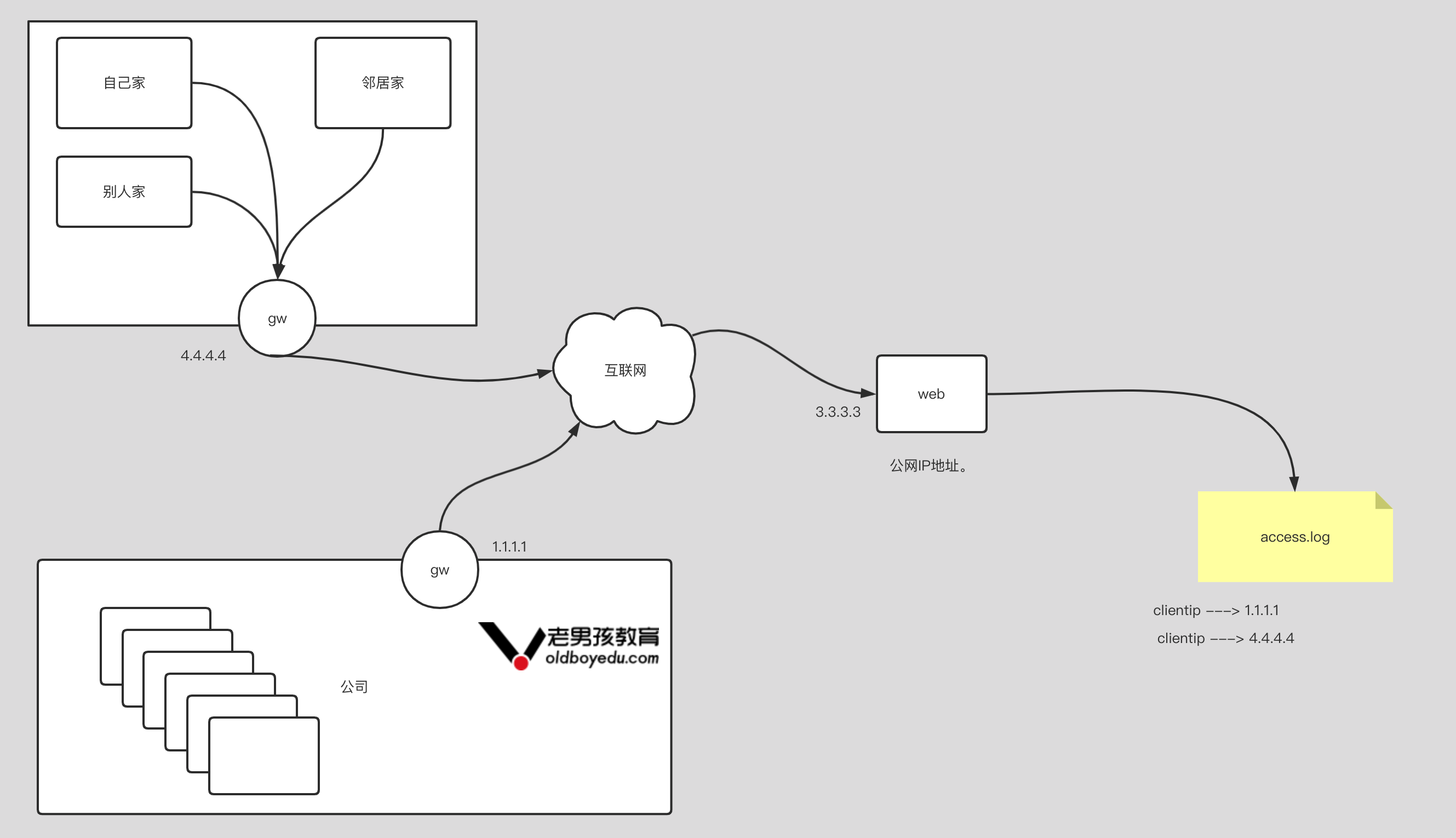
如上图所示,要求完成以下内容:
(1)收集nginx⽇志,写⼊ES集群,分⽚数量为3,副本数量为0,索引名称为"oldboyedu-linux80-nginx";
(2)收集tomcat⽇志,写⼊ES集群,分⽚数量为5,副本数量为0,索引名称为"oldboyedu-linux80-tomcat";
(3)收集app⽇志,写⼊ES集群,分⽚数量为10,副本数量为0,索引名称为"oldboyedu-linux80-app";
进阶作业:
(1)分析出nginx,tomcat的客户端ip所属城市,访问时使⽤的设备类型等。
(2)请调研使⽤logstash的pipline来替代logstash的多实例⽅案;filebeat 手机 tomcat 日志
[root@elk102.oldboyedu.com ~]# cat ~/config/38-tomcat-to-logstash.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /oldboyedu/softwares/apache-tomcat-10.0.20/logs/*.txt
json.keys_under_root: true
output.logstash:
hosts: ["10.0.0.101:7777"]
[root@elk102.oldboyedu.com ~]$
[root@elk102.oldboyedu.com ~]$ filebeat -e -c ~/config/38-tomcat-to-logstash.ymlfilebeat 收集 nginx 日志
[root@elk102.oldboyedu.com ~]# cat ~/config/37-nginx-to-logstash.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log*
json.keys_under_root: true
output.logstash:
hosts: ["10.0.0.101:8888"]
[root@elk102.oldboyedu.com ~]$
[root@elk102.oldboyedu.com ~]$ filebeat -e -c ~/config/37-nginx-to-logstash.yml --path.data /tmp/filebeat-nginxfilebeat 收集 apps 日志
[root@elk102.oldboyedu.com ~]# cat ~/config/39-apps-to-logstash.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /tmp/app.log*
output.logstash:
hosts: ["10.0.0.101:6666"]
[root@elk102.oldboyedu.com ~]$
[root@elk102.oldboyedu.com ~]$ filebeat -e -c ~/config/39-apps-to-logstash.yml --path.data /tmp/filebeat-applogstash 收集 nginx 日志
[root@elk101.oldboyedu.com ~]# cat config-logstash/24-homework-01-to-es.conf
input {
beats {
port => 8888
}
}
filter {
mutate {
remove_field => ["tags","log","agent","@version", "input","ecs"]
}
geoip {
source => "clientip"
target => "oldboyedu-linux80-geoip"
}
useragent {
source => "http_user_agent"
target => "oldboyedu-linux80-useragent"
}
}
output {
stdout {}
elasticsearch {
hosts => ["10.0.0.101:9200","10.0.0.102:9200","10.0.0.103:9200"]
index => "oldboyedu-linux80-nginx"
}
}
[root@elk101.oldboyedu.com ~]# logstash -rf config-logstash/24-homework-01-to-es.conflogstash 收集 tomcat 日志
[root@elk101.oldboyedu.com ~]# cat config-logstash/24-homework-02-to-es.conf
input {
beats {
port => 7777
}
}
filter {
mutate {
remove_field => ["tags","log","agent","@version", "input","ecs"]
}
geoip {
source => "clientip"
target => "oldboyedu-linux80-geoip"
}
useragent {
source => "AgentVersion"
target => "oldboyedu-linux80-useragent"
}
}
output {
stdout {}
elasticsearch {
hosts => ["10.0.0.101:9200","10.0.0.102:9200","10.0.0.103:9200"]
index => "oldboyedu-linux80-tomcat"
}
}
[root@elk101.oldboyedu.com ~]$
[root@elk101.oldboyedu.com ~]$ logstash -rf config-logstash/24-homework-02-to-es.conf --path.data /tmp/homework-logstash-02logstash 收集 apps 日志
[root@elk101.oldboyedu.com ~]# cat config-logstash/24-homework-03-to-es.conf
input {
beats {
port => 6666
}
}
filter {
mutate {
remove_field => ["tags","log","agent","@version", "input","ecs"]
}
mutate {
remove_field => ["port","@version","host"]
}
mutate {
split => {
"message" => "|"
}
add_field => {
"user_id" => "%{[message][1]}"
"action" => "%{[message][2]}"
"svip" => "%{[message][3]}"
"price" => "%{[message][4]}"
}
remove_field => ["message"]
strip => ["svip"]
}
mutate {
convert => {
"user_id" => "integer"
"svip" => "boolean"
"price" => "float"
}
}
}
output {
stdout {}
elasticsearch {
hosts => ["10.0.0.101:9200","10.0.0.102:9200","10.0.0.103:9200"]
index => "oldboyedu-linux80-apps"
}
}
[root@elk101.oldboyedu.com ~]$
[root@elk101.oldboyedu.com ~]$ logstash -rf config-logstash/24-homework-03-to-es.conf --path.data /tmp/homework-logstash-03kibana 自定义 dashboard 实战案例
1.统计 pv(指标)
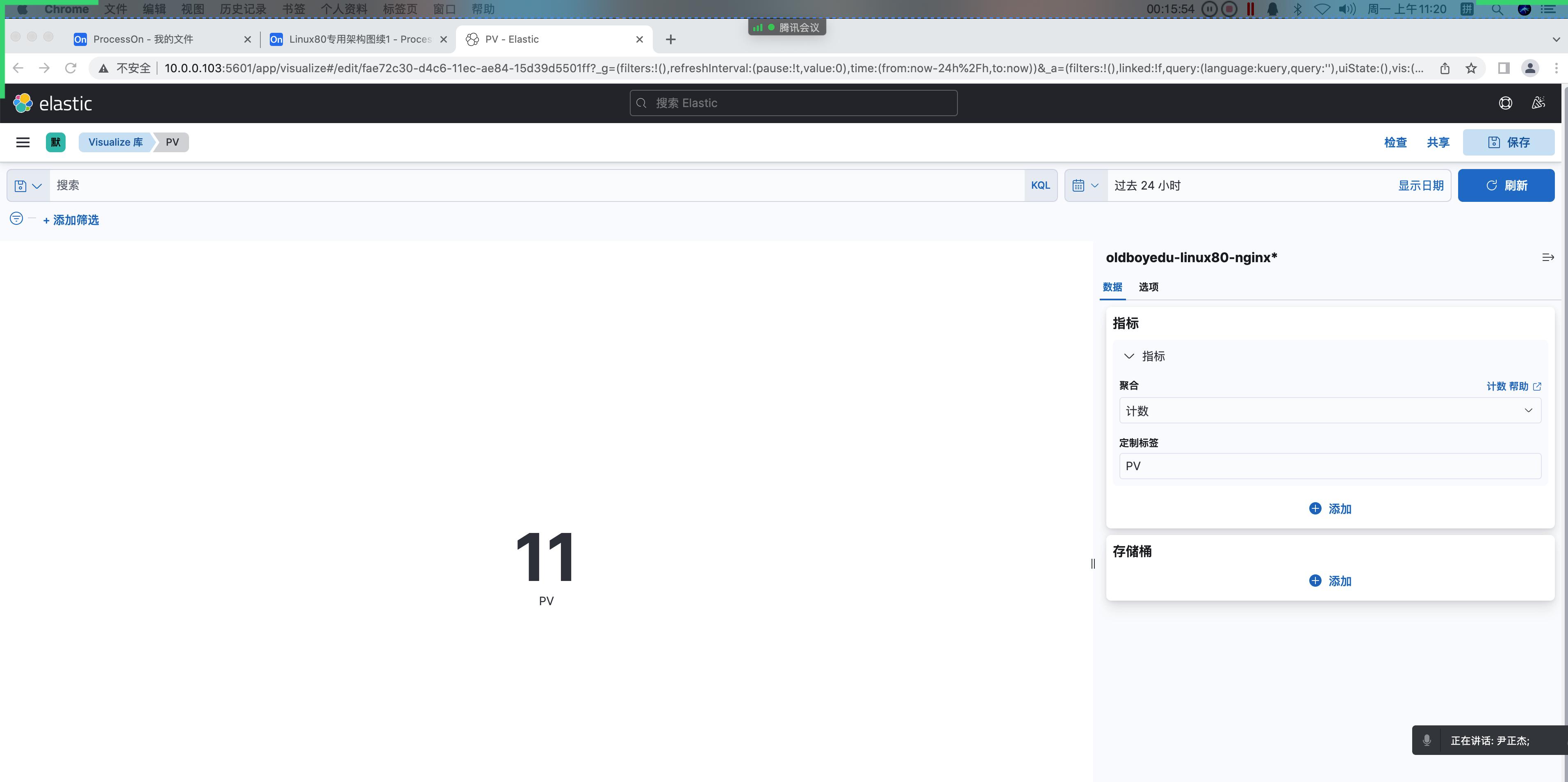
Page View(简称:"PV")
⻚⾯访问或点击量。
kibana界⾯⿏标依次点击如下:
(1)菜单栏;
(2)Visualize Library(可视化库);
(3)新建可视化
(4)基于聚合
(5)指标
(6)选择索引模式(例如"oldboyedu-linux80-nginx*")
(7)指标栏中选择:
聚合: 计数
定制标签: PV2.统计客户端 IP(指标)
客户端IP:
通常指的是访问Web服务器的客户端IP地址,但要注意,客户端IP数量并不难代表UV。
kibana界⾯⿏标依次点击如下:
(1)菜单栏;
(2)Visualize Library(可视化库);
(3)创建可视化
(4)基于聚合
(5)指标
(6)选择索引模式(例如"oldboyedu-linux80-nginx*")
(7)指标栏中选择:
聚合: 唯⼀计数
字段: clientip.keyword
定制标签: IP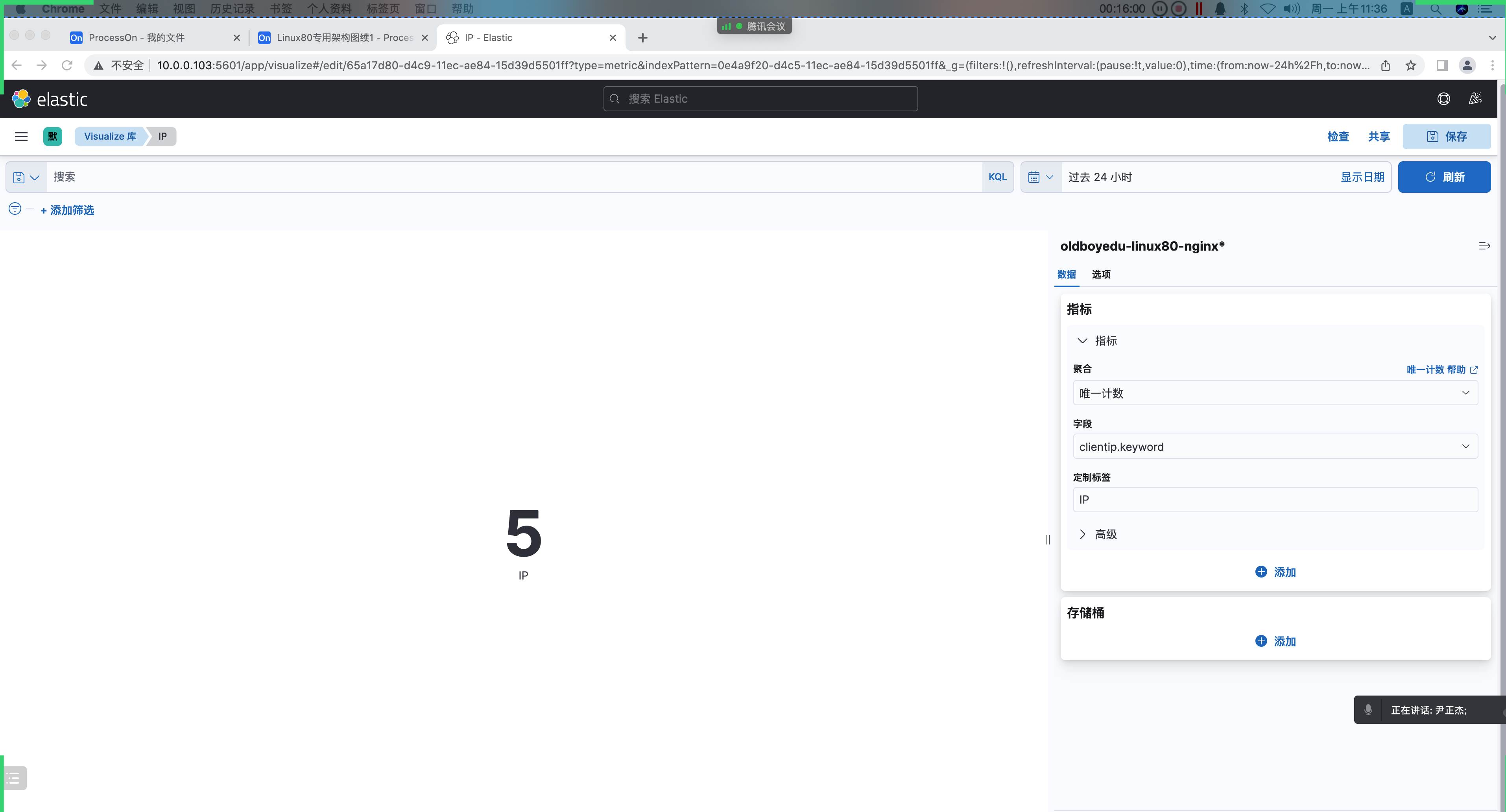
3.统计 web 下载带宽(指标)
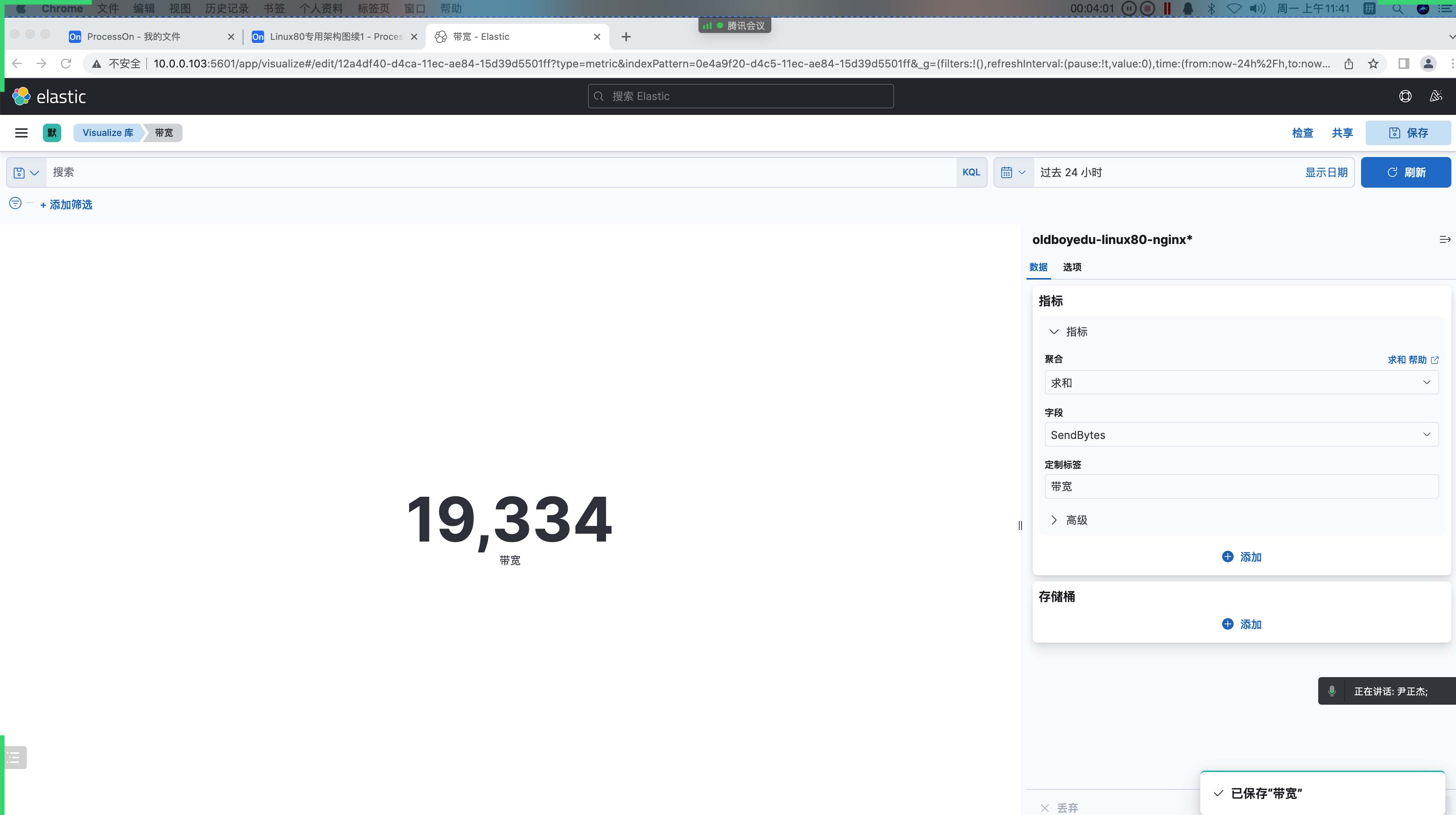
带宽:
统计nginx返回给客户端⽂件⼤⼩的字段进⾏累计求和。
kibana界⾯⿏标依次点击如下:
(1)菜单栏;
(2)Visualize Library(可视化库);
(3)创建可视化
(4)基于聚合
(5)指标
(6)选择索引模式(例如"oldboyedu-linux80-nginx*")
(7)指标栏中选择:
聚合: 求和
字段: SendBytes
定制标签: 带宽4.访问页面统计(水平条形图)
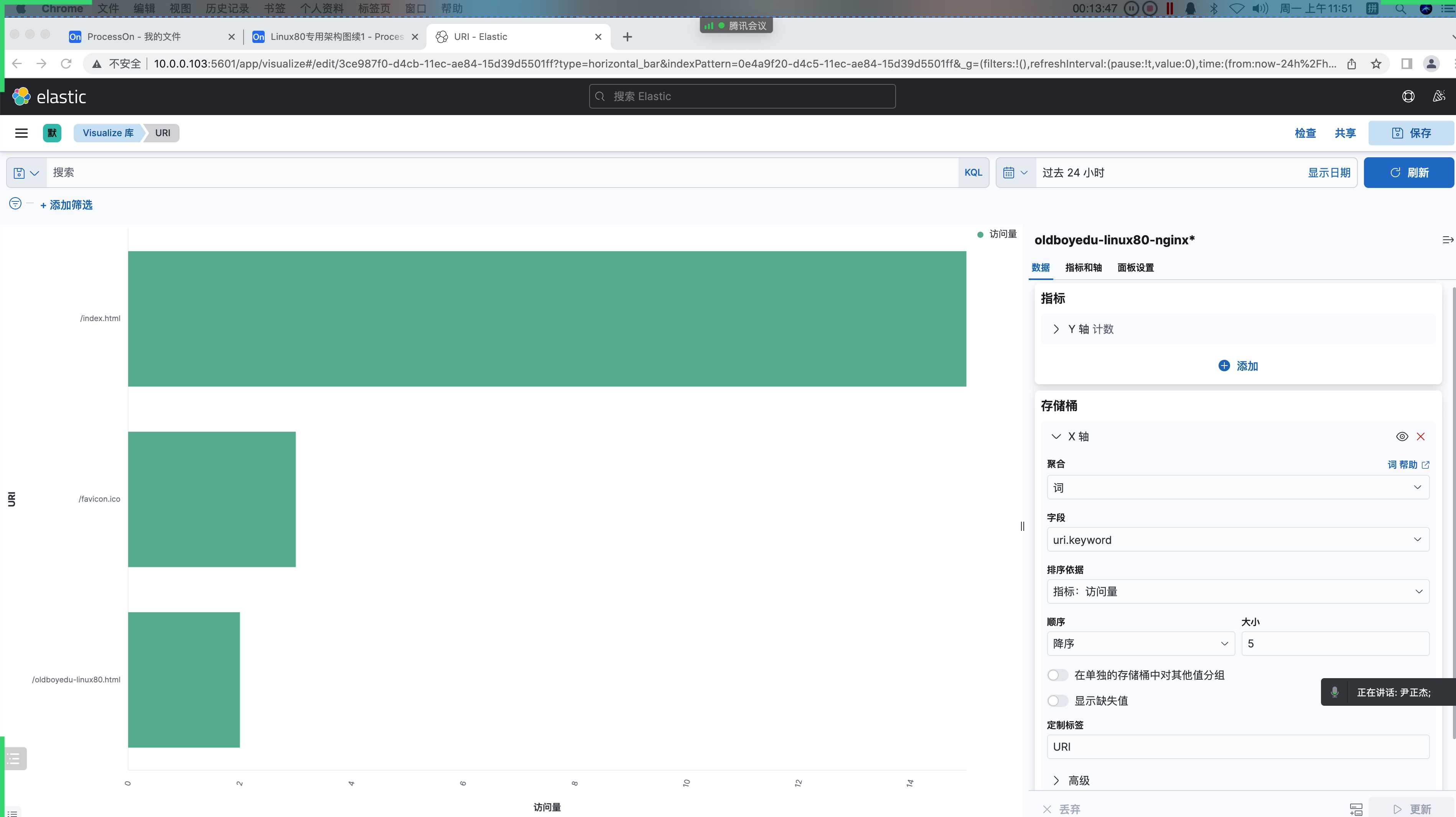
访问资源统计:
对URI的访问次数统计。
kibana界⾯⿏标依次点击如下:
(1)菜单栏;
(2)Visualize Library(可视化库);
(3)创建可视化
(4)基于聚合
(5)⽔平条形图
(6)选择索引模式(例如"oldboyedu-linux80-nginx*")
(7)指标栏中设置(即Y轴)
聚合: 计数
定制标签: 访问量
(8)添加"存储痛",选择"X"轴
聚合: 词
字段: uri.keyword
...
定制标签: URI5.分析客户端的城市分布(垂直条形图)
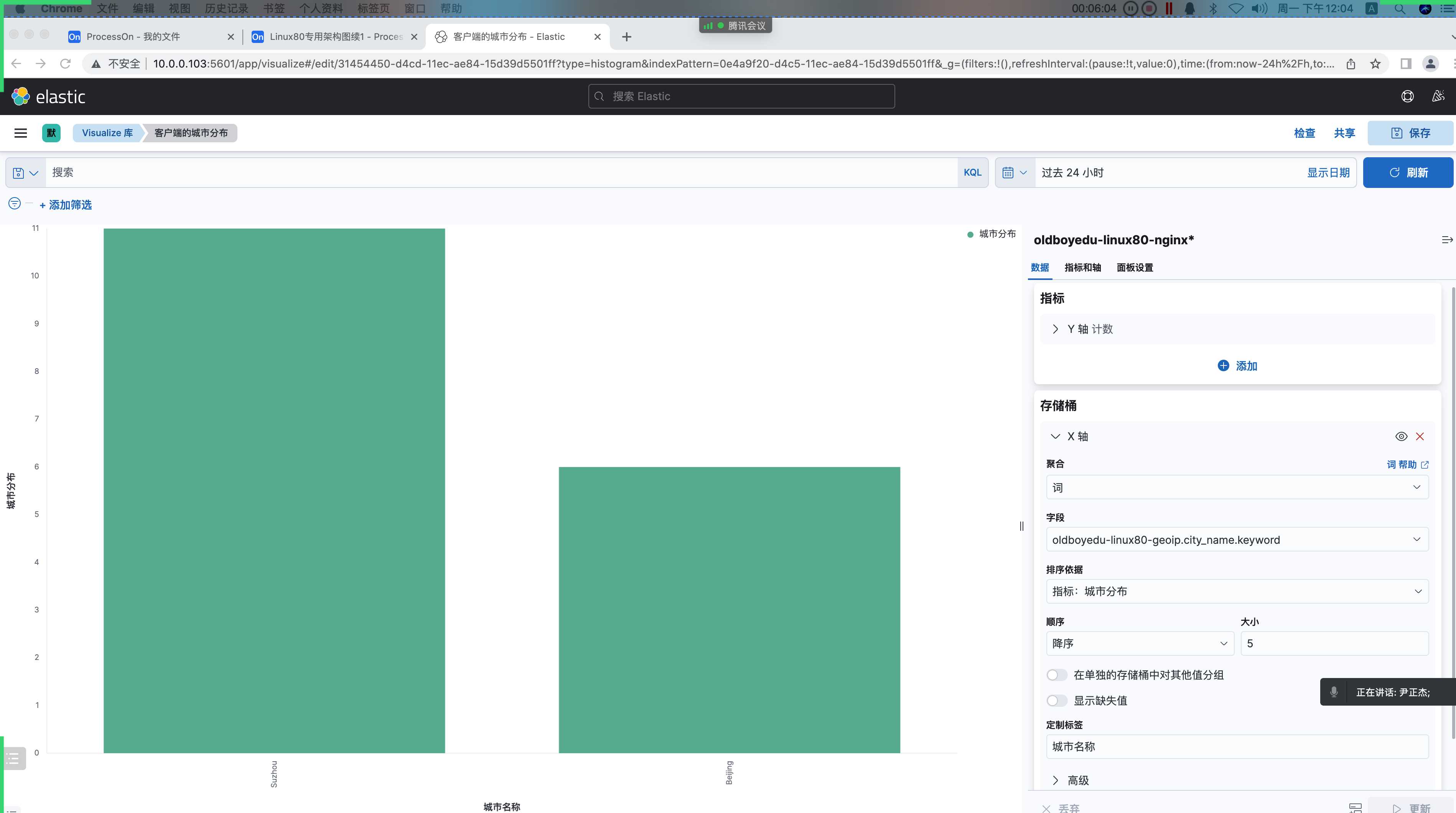
分析客户端的城市分布:
需要借助logstash的filter插件的geoip实现对客户端的IP地址进⾏地域解析。
kibana界⾯⿏标依次点击如下:
(1)菜单栏;
(2)Visualize Library(可视化库);
(3)创建可视化
(4)基于聚合
(5)垂直条形图
(6)选择索引模式(例如"oldboyedu-linux80-nginx*")
(7)指标栏中设置(即Y轴)
聚合: 计数
定制标签: 城市分布
(8)添加"存储痛",选择"X"轴
聚合: 词
字段: oldboyedu-linux80-nginx.city_name.keyword
...
定制标签: 城市名称6.城市分布百分比(饼图)
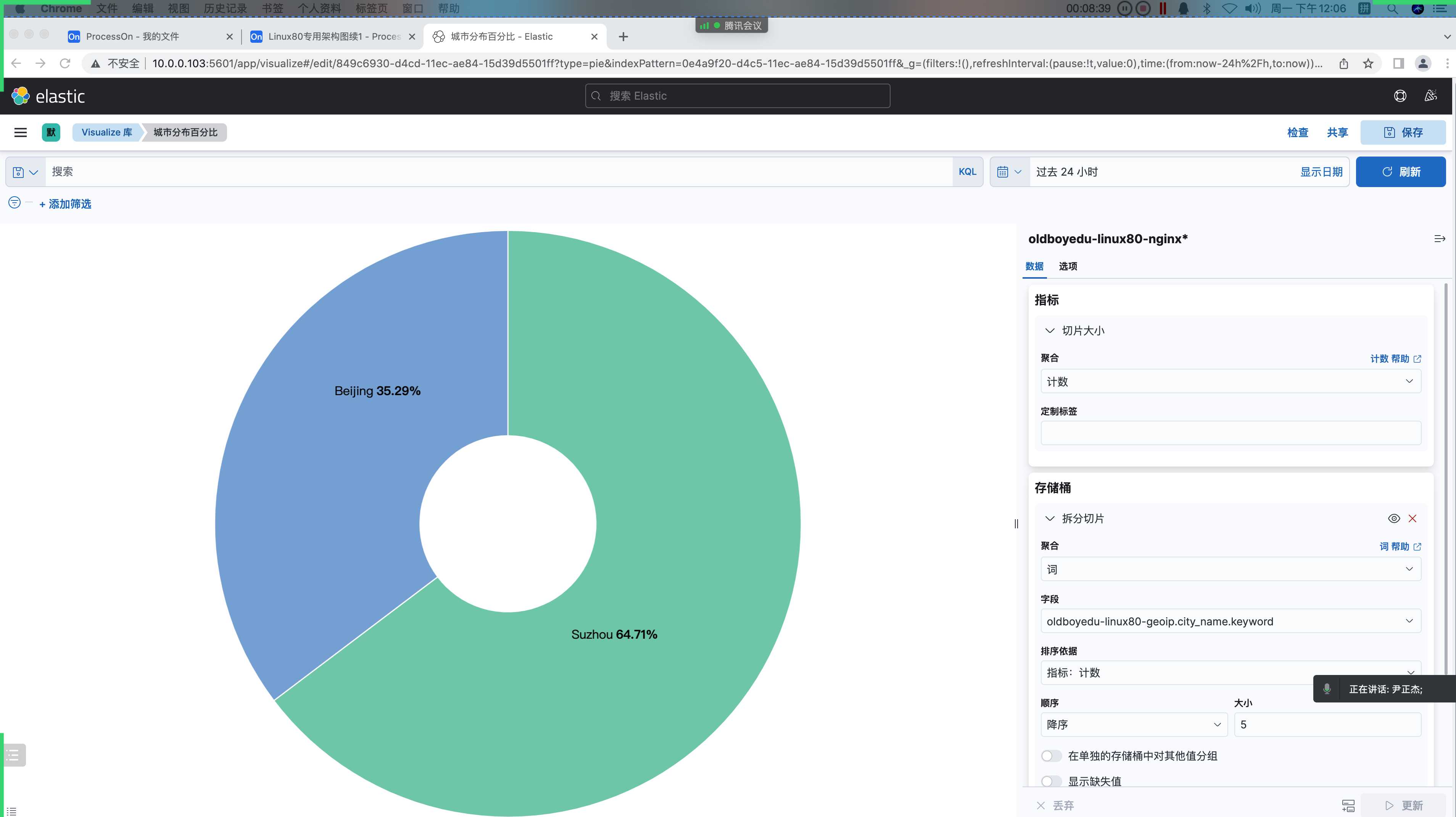
分析客户端的城市分布:
需要借助logstash的filter插件的geoip实现对客户端的IP地址进⾏地域解析。
kibana界⾯⿏标依次点击如下:
(1)菜单栏;
(2)Visualize Library(可视化库);
(3)创建可视化
(4)基于聚合
(5)饼图
(6)选择索引模式(例如"oldboyedu-linux80-nginx*")
(7)指标栏中设置(即Y轴)
聚合: 计数
定制标签: 城市分布
(8)添加"存储痛",选择"X"轴
聚合: 词
字段: oldboyedu-linux80-nginx.city_name.keyword
...
定制标签: 城市名称7.IP 的 TopN 统计(仪表盘)
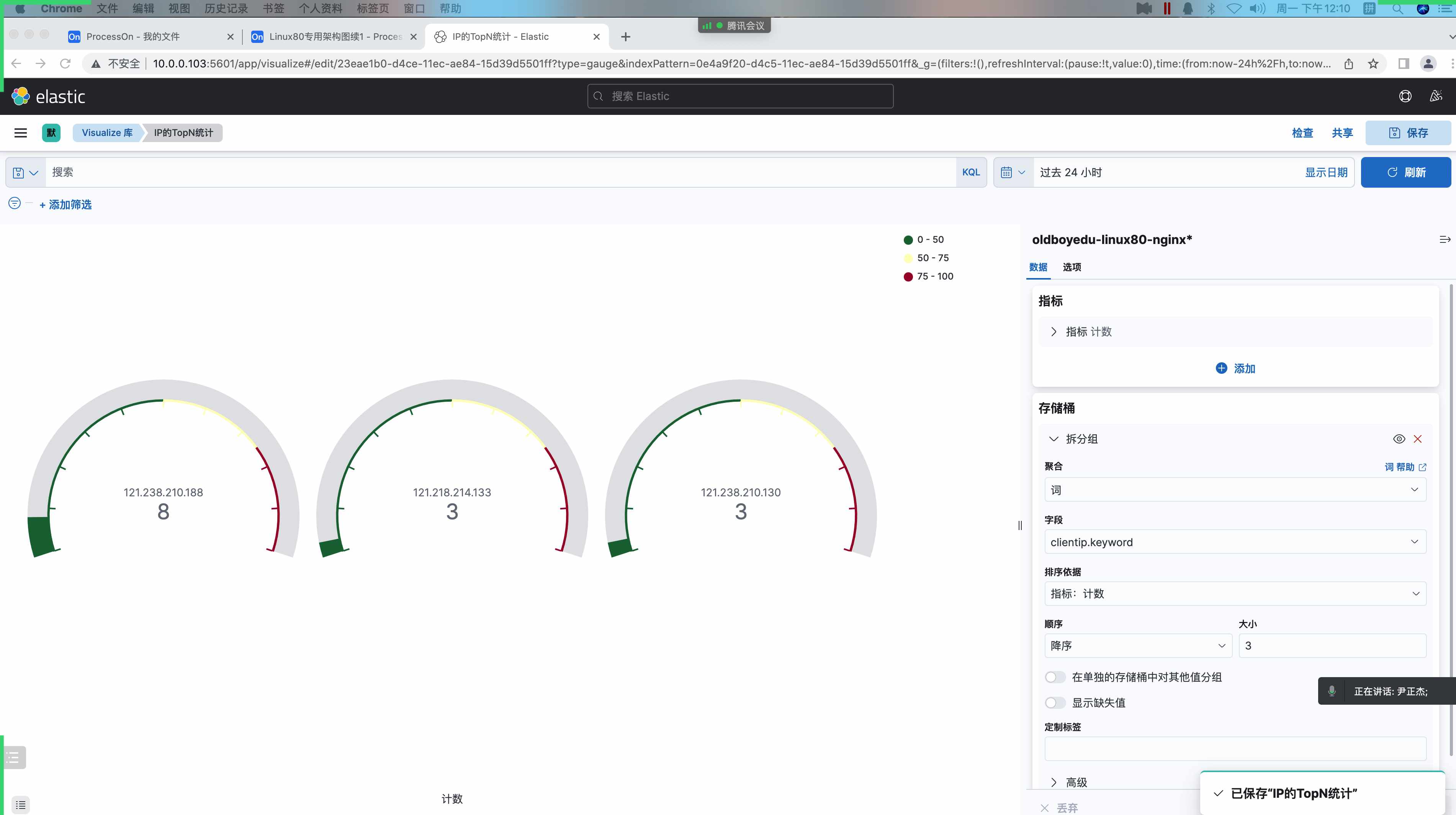
IP的TopN统计:
统计访问量的客户端IP最⼤的是谁。
kibana界⾯⿏标依次点击如下:
(1)菜单栏;
(2)Visualize Library(可视化库);
(3)创建可视化
(4)基于聚合
(5)仪表盘
(6)选择索引模式(例如"oldboyedu-linux80-nginx*")
(7)指标栏中设置(即Y轴)
聚合: 计数
(8)添加"存储痛",选择"X"轴
聚合: 词
字段: client.keyword
顺序: 降序
⼤⼩: 3
...8.自定义 dashboard
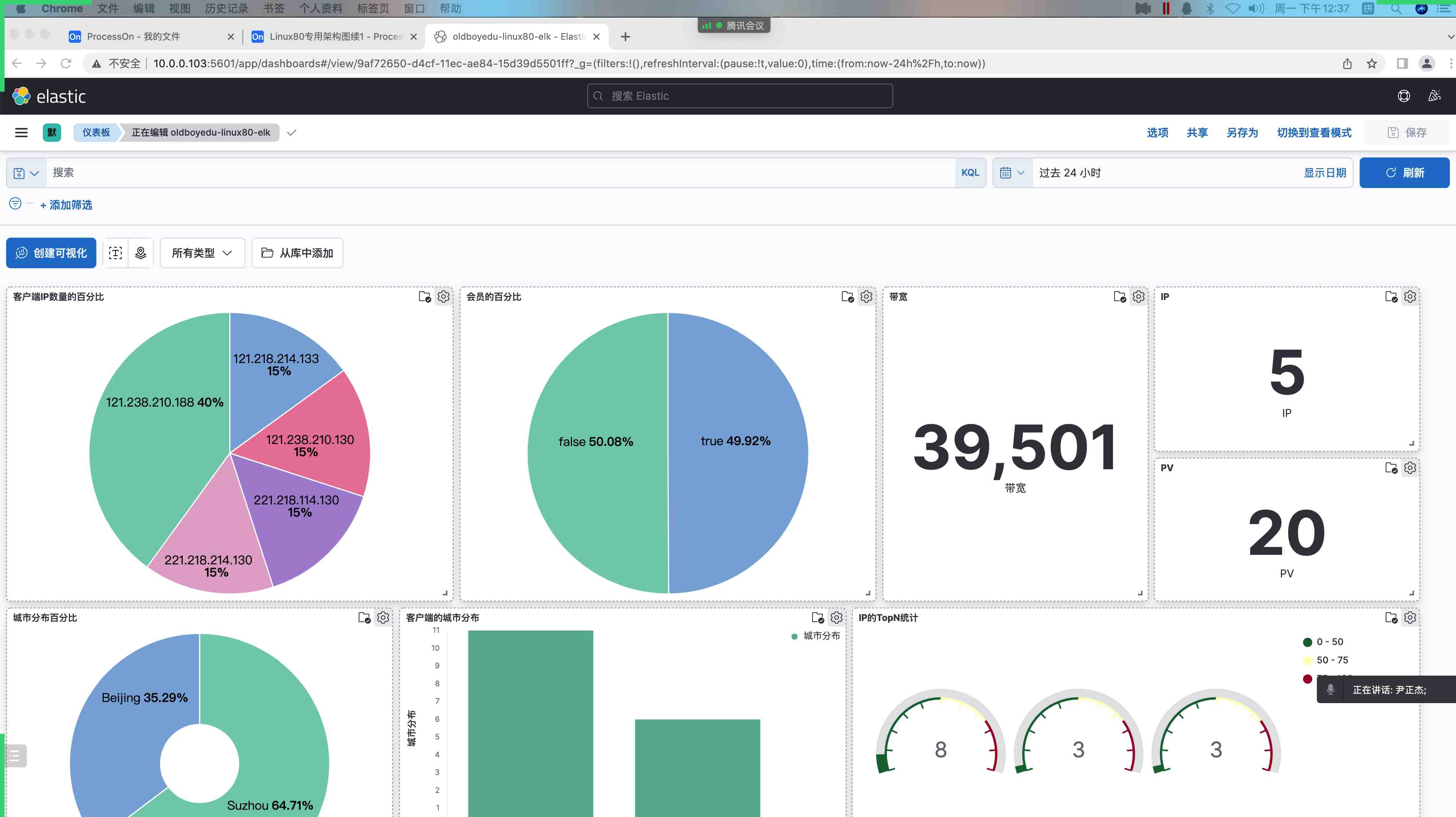
kibana界⾯⿏标依次点击如下:
(1)菜单栏;
(2)Dashboard
(3)创建仪表盘
(4)从可视化库中添加即可。
如上图和下图所示,为我添加到dashboard界⾯。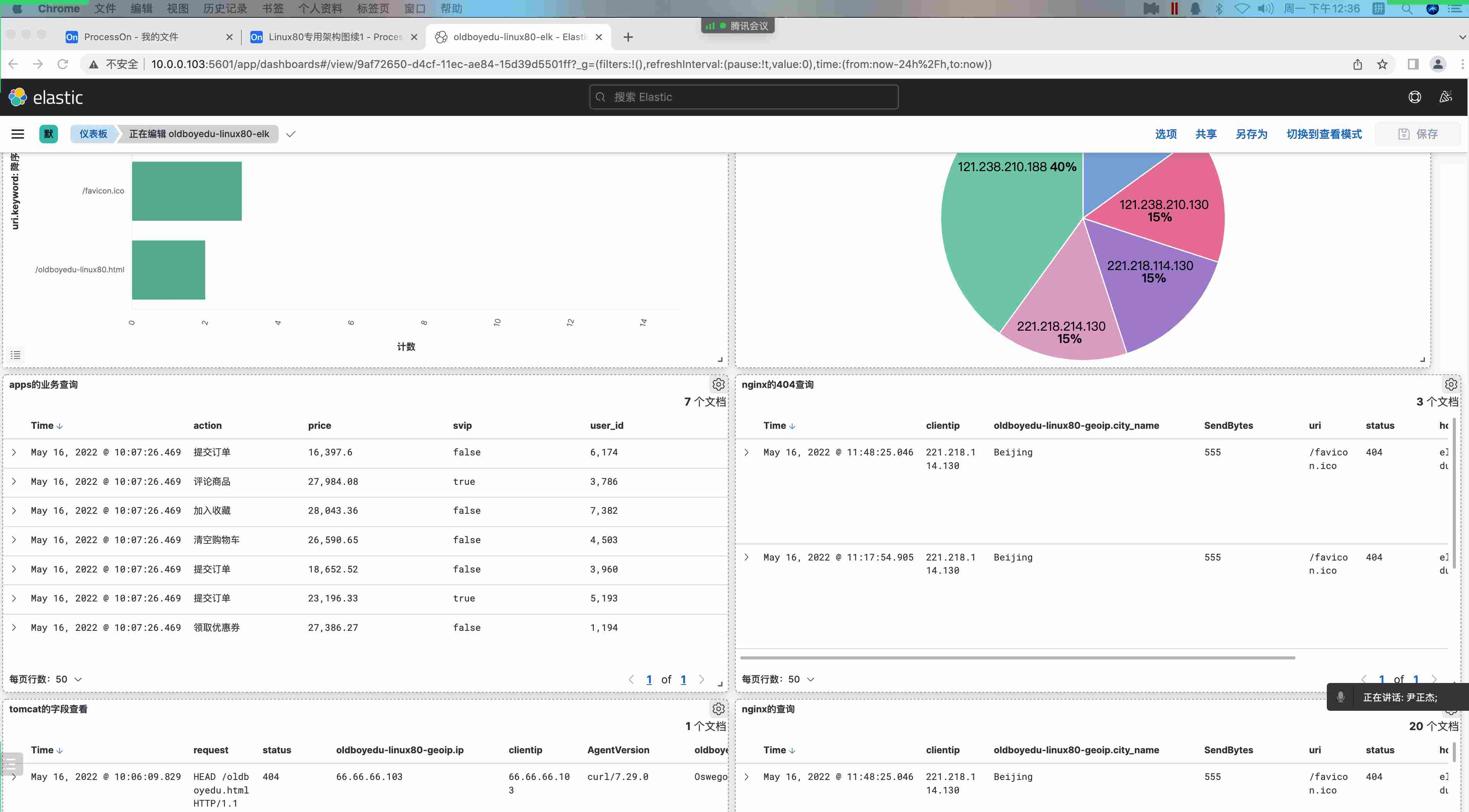
ElasticStack 二进制部署及排错
1.部署 Oracle JDK 环境
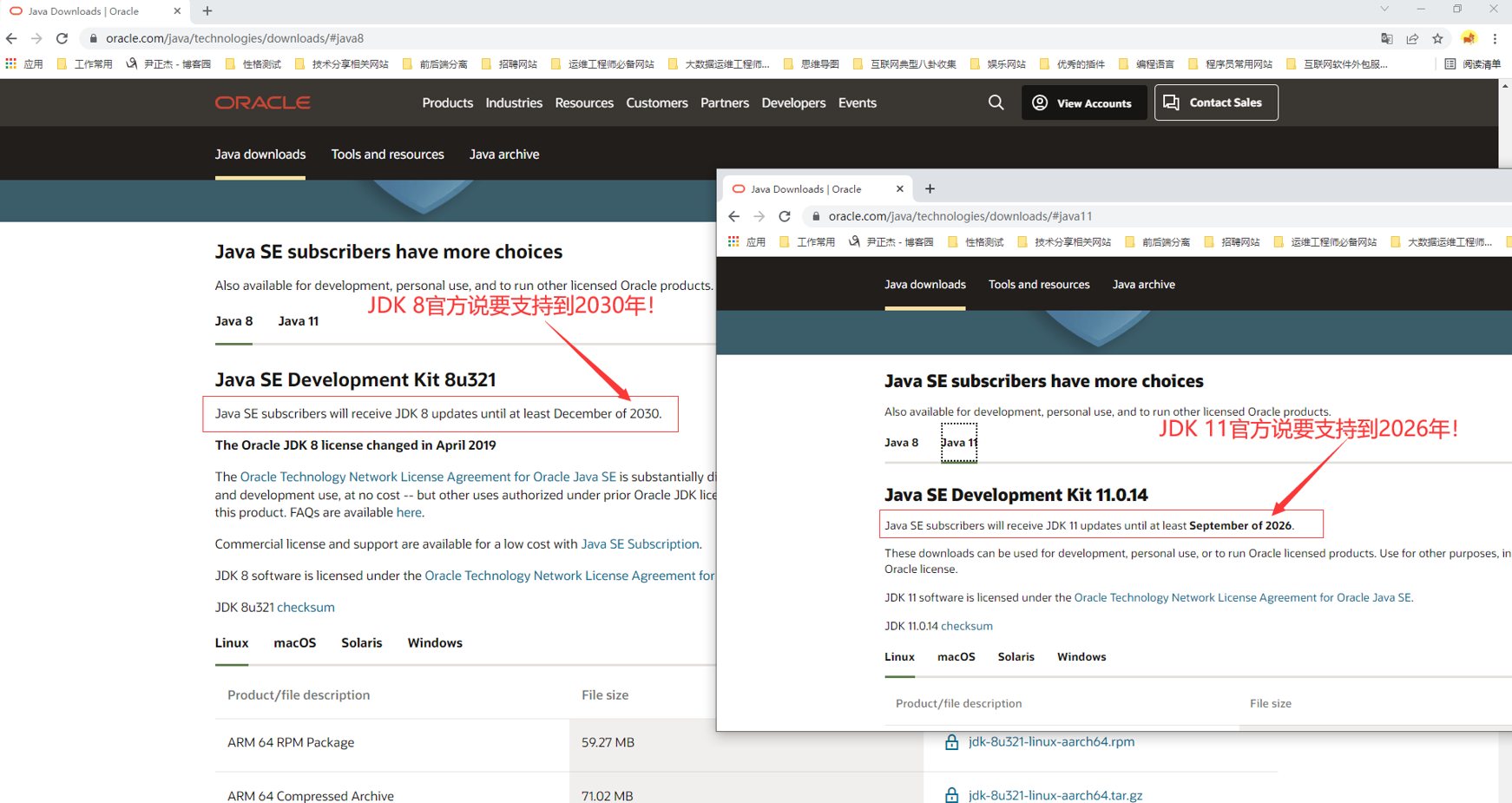
# 官⽅连接: https://www.oracle.com/java/technologies/downloads/#java8
# elk101单节点部署oracle jdk步骤:
# (1)创建⼯作⽬录
$ mkdir -pv /oldboyedu/softwares
# (2)解压JDK到指定的⽬录
$ tar xf jdk-8u291-linux-x64.tar.gz -C /oldboyedu/softwares/
# (3)创建符号链接
$ cd /oldboyedu/softwares/ && ln -sv jdk1.8.0_291 jdk
# (4)创建环境变量
$ cat > /etc/profile.d/elk.sh <<EOF
#!/bin/bash
export JAVA_HOME=/oldboyedu/softwares/jdk
export PATH=$PATH:$JAVA_HOME/bin
EOF
$ source /etc/profile.d/elk.sh
# (5)查看JDK的版本号
$ java -version
# 集群部署还需要做下⾯2个步骤:
# (1)同步jdk环境到其他节点
$ data_rsync.sh /oldboyedu/
$ data_rsync.sh /etc/profile.d/elk.sh
# (2)其他节点测试
$ source /etc/profile.d/elk.sh
$ java -version
2.单节点 ES 部署
# (1)下载ES软件
# 略,参考之前的视频。
# (2)解压ES
$ tar xf elasticsearch-7.17.3-linux-x86_64.tar.gz -C /oldboyedu/softwares/
# (3)创建符号链接
$ cd /oldboyedu/softwares/ && ln -sv elasticsearch-7.17.3 es
# (4)配置环境变量
$ cat >> /etc/profile.d/elk.sh <<EOF
export ES_HOME=/oldboyedu/softwares/es
export PATH=$PATH:$ES_HOME/bin
EOF
$ source /etc/profile.d/elk.sh
# (5)创建ES⽤户,⽤于运⾏ES服务
$ useradd oldboyedu
# (6)修改配置⽂件
$ vim /oldboyedu/softwares/es/config/elasticsearch.yml
...
cluster.name: oldboyedu-linux80-elk
network.host: 0.0.0.0
discovery.seed_hosts: ["10.0.0.101"]
cluster.initial_master_nodes: ["10.0.0.101"]
# (7)修改权限
$ chown oldboyedu:oldboyedu -R /oldboyedu/softwares/elasticsearch-7.17.3/
# (8)修改⽂件打开数量的限制(退出当前会话⽴即⽣效)
$ cat > /etc/security/limits.d/elk.conf <<EOF
* soft nofile 65535
* hard nofile 131070
EOF
# (9)修改内核参数的内存映射信息
$ cat > /etc/sysctl.d/elk.conf <<EOF
vm.max_map_count = 262144
EOF
$ sysctl -f /etc/sysctl.d/elk.conf
$ sysctl -q vm.max_map_count
# (10)启动服务("-d"选项代表是后台启动服务.)
$ su -c "elasticsearch" oldboyedu
$ su -c "elasticsearch -d" oldboyedu
# (11)验证服务
$ curl 10.0.0.101:9200
$ curl 10.0.0.101:9200/_cat/nodes3.修改 ES 的堆(heap)内存大小
前置知识:
jps快速⼊⻔:
作⽤:
查看java相关的进程信息。
常⽤参数:
-l: 显示包名称。
-v: 显示进程的相信信息
-V: 默认就是该选项,表示查看简要信息。
-q: 只查看pid。
jmap快速⼊⻔:
作⽤:
查看java的堆栈信息。
常⽤参数:
-heap: 查看堆内存的⼤⼩。
-dump: 下载堆内存的相关信息。
(1)修改堆内存⼤⼩
vim /oldboyedu/softwares/es/config/jvm.options
...
# 堆内存设置不建议超过32G.
-Xms256m
-Xmx256m
(2)重启服务
kill `jps | grep Elasticsearch | awk '{print $1}'`
su -c "elasticsearch -d" oldboyedu
(3)验证堆内存的⼤⼩
jmap -heap `jps | grep Elasticsearch | awk '{print $1}'`
推荐阅读:
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/advanced-configuration.html#set-jvm-heap-size4.ES 启动脚本编写
$ cat > /usr/lib/systemd/system/es.service <<EOF
[Unit]
Description=Oldboyedu linux80 ELK
After=network.target
[Service]
Type=forking
ExecStart=/oldboyedu/softwares/es/bin/elasticsearch -d
Restart=no
User=oldboyedu
Group=oldboyedu
LimitNOFILE=131070
[Install]
WantedBy=multi-user.target
EOF
$ systemctl daemon-reload
$ systemctl restart es5.部署 ES 集群
# (1)停⽌ES服务并删除集群之前的数据(如果是ES集群扩容就别删除数据了,我这⾥是部署⼀个"⼲净"的集群)
systemctl stop es
rm -rf /oldboyedu/softwares/es/{data,logs} /tmp/*
install -o oldboyedu -g oldboyedu -d /oldboyedu/softwares/es/logs
# (2)创建数据和⽇志⽬录
mkdir -pv /oldboyedu/{data,logs}
install -d /oldboyedu/{data,logs}/es7 -o oldboyedu -g oldboyedu
# (3)修改配置⽂件
vim /oldboyedu/softwares/es/config/elasticsearch.yml
...
cluster.name: oldboyedu-linux80-elk
path.data: /oldboyedu/data/es7
path.logs: /oldboyedu/logs/es7
network.host: 0.0.0.0
discovery.seed_hosts: ["10.0.0.101","10.0.0.102","10.0.0.103"]
cluster.initial_master_nodes: ["10.0.0.101","10.0.0.102","10.0.0.103"]
# (4)elk101节点同步数据到其他节点
data_rsync.sh /oldboyedu/
data_rsync.sh /etc/security/limits.d/elk.conf
data_rsync.sh /etc/sysctl.d/elk.conf
data_rsync.sh /usr/lib/systemd/system/es.service
data_rsync.sh /etc/profile.d/elk.sh
# (5)其他节点重连会话后执⾏以下操作
useradd oldboyedu
sysctl -f /etc/sysctl.d/elk.conf
sysctl -q vm.max_map_count
systemctl daemon-reload
# (6)启动ES集群
systemctl start es
# (7)验证ES的集群服务是否正常
curl 10.0.0.101:9200
curl 10.0.0.101:9200/_cat/nodes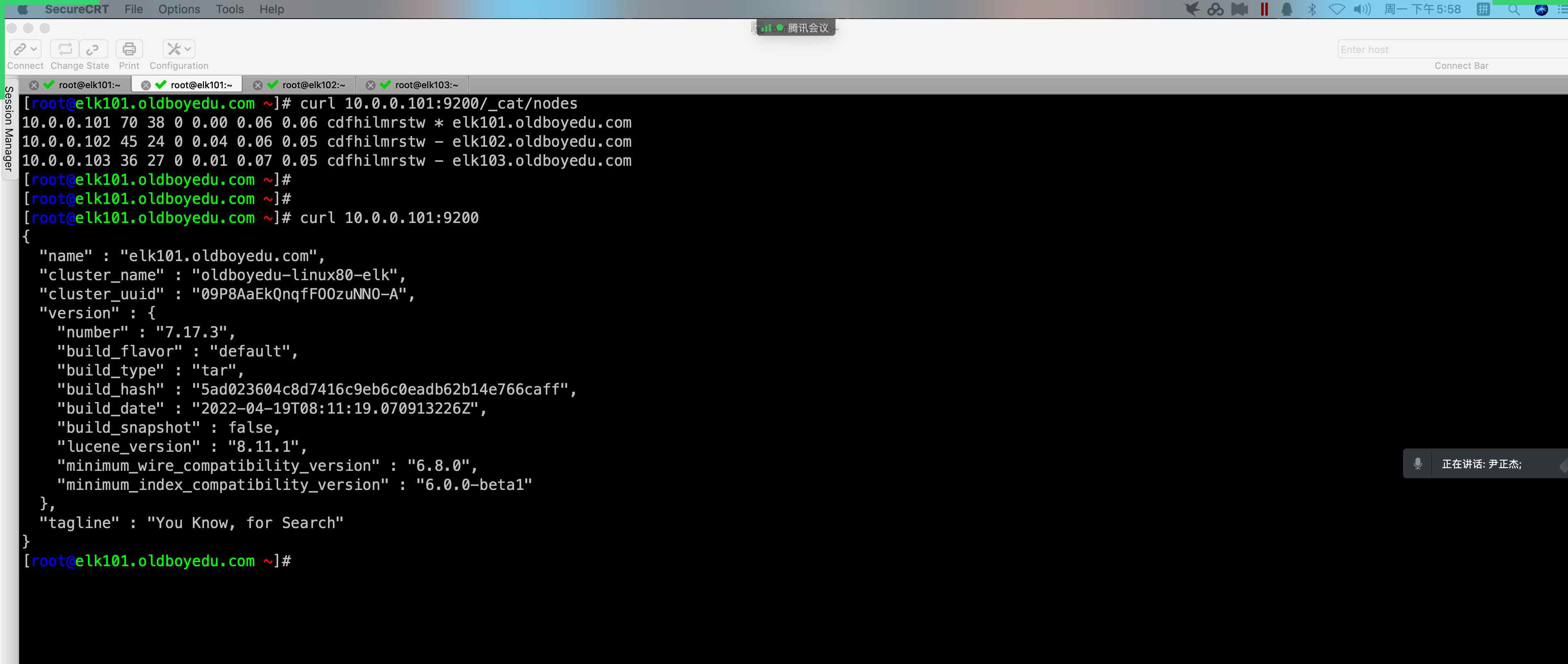
6.部署 kibana 服务
# (1)解压软件包
tar xf kibana-7.17.3-linux-x86_64.tar.gz -C /oldboyedu/softwares/
# (2)创建符号链接
cd /oldboyedu/softwares/ && ln -sv kibana-7.17.3-linux-x86_64 kibana
# (3)配置环境变量
cat >> /etc/profile.d/elk.sh <<EOF
export KIBANA_HOME=/oldboyedu/softwares/kibana
export PATH=$PATH:$KIBANA_HOME/bin
EOF
source /etc/profile.d/elk.sh
# (4)修改⽂件全选
chown oldboyedu:oldboyedu -R /oldboyedu/softwares/kibana-7.17.3-linux-x86_64/
# (5)修改配置⽂件
vim /oldboyedu/softwares/kibana/config/kibana.yml
...
server.host: "0.0.0.0"
server.name: "oldboyedu-linux80-kibana"
elasticsearch.hosts: ["http://10.0.0.101:9200","http://10.0.0.102:9200","http://10.0.0.103:9200"]
i18n.locale: "zh-CN"
# (6)启动服务
su -c "kibana" oldboyedu7.部署 logstash
# (1)解压logstash
tar xf logstash-7.17.3-linux-x86_64.tar.gz -C /oldboyedu/softwares/
# (2)创建符号链接
cd /oldboyedu/softwares/ && ln -sv logstash-7.17.3 logstsash
# (3)配置环境变量
cat >> /etc/profile.d/elk.sh <<EOF
export LOGSTASH_HOME=/oldboyedu/softwares/logstsash
export PATH=$PATH:$LOGSTASH_HOME/bin
EOF
source /etc/profile.d/elk.sh
# (4)编写测试案例
cat > conf-logstash/01-stdin-to-stdout.conf <<EOF
input {
stdin {}
}
output{
stdout {}
}
EOF
# (5)运⾏测试案例
logstash -f conf-logstash/01-stdin-to-stdout.conf
7.部署 filebeat
# (1)解压软件包
tar xf filebeat-7.17.3-linux-x86_64.tar.gz -C /oldboyedu/softwares/
cd /oldboyedu/softwares/filebeat-7.17.3-linux-x86_64
mkdir config-filebeat
# (2)编写配置⽂件
cat > config-filebeat/01-stdin-to-console.yml <EOF
filebeat.inputs:
- type: stdin
output.console:
pretty: true
EOF
# (3)启动filebeat实例
./filebeat -e -c config-filebeat/01-stdin-to-console.yml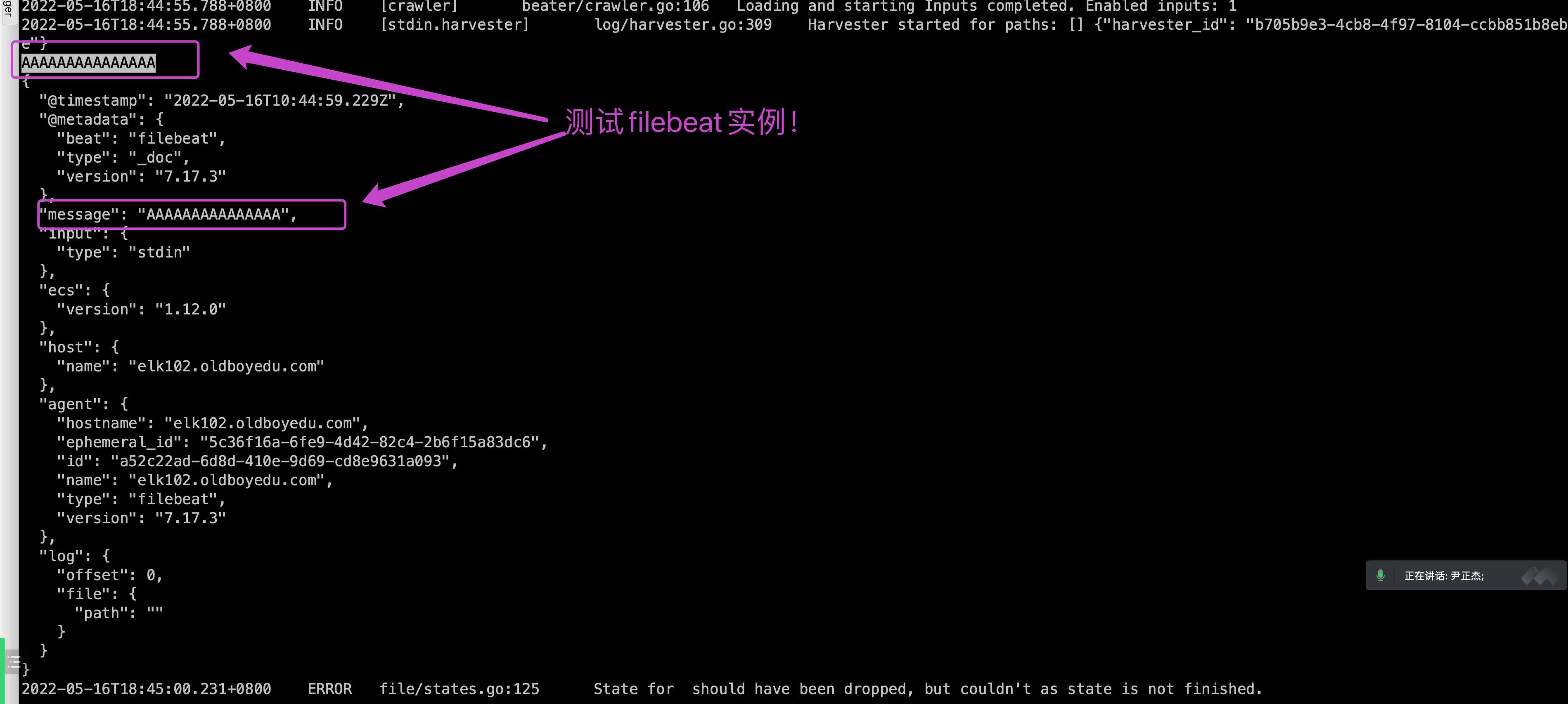
8.部署 es-head 插件
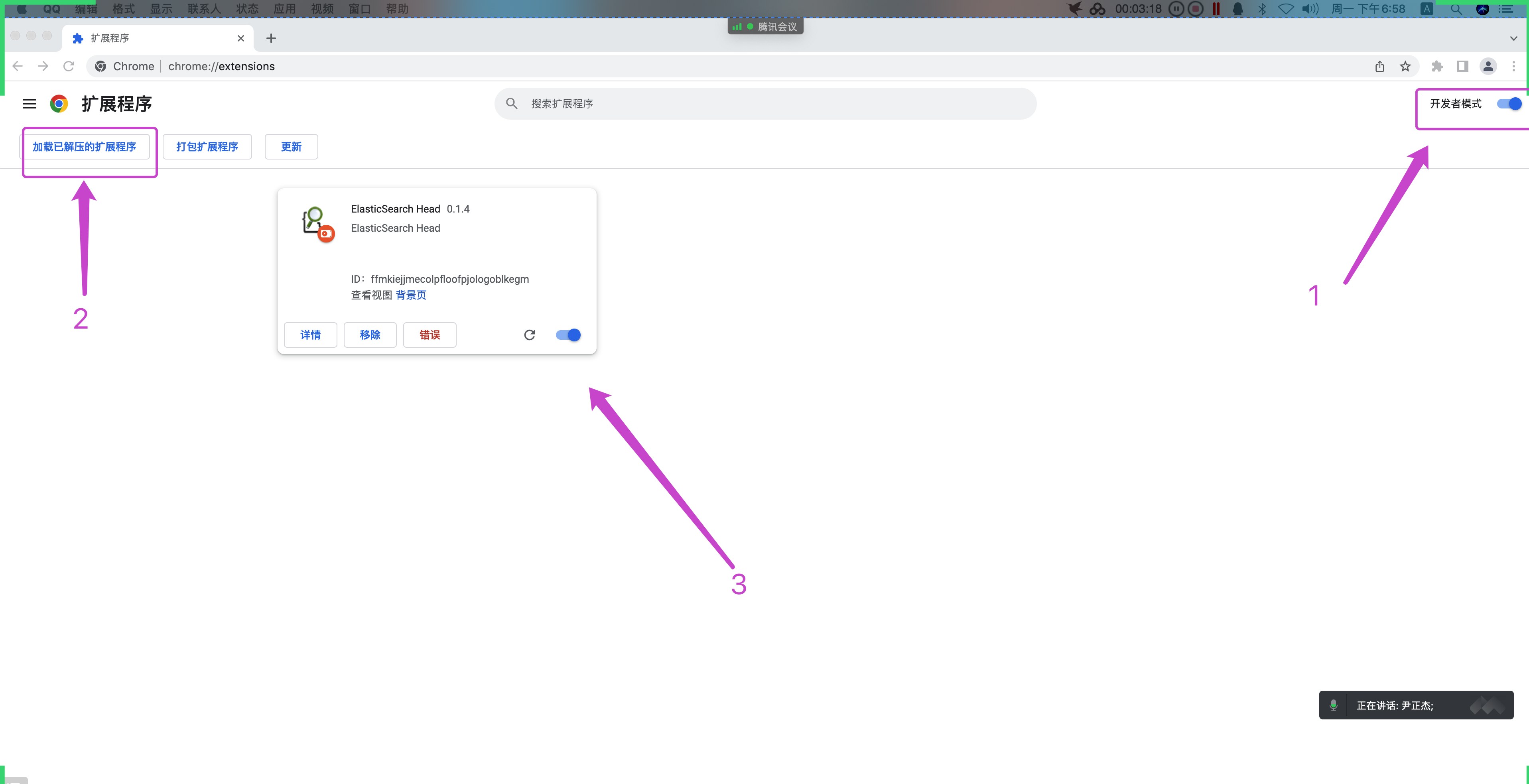
(1)解压es-head组件的软件包
unzip es-head-0.1.4_0.crx.zip
(2)⾕歌浏览器导⼊软件包
设置 ---> 扩展程序 ---> 勾选"开发者模式" ---> "加载已经解压的扩展程序" ---> 选择"上⼀步骤解压的⽬录"9.部署 postman 组件
(1)下载postman组件
https://www.postman.com/downloads/
(2)post的使⽤
后续讲解。
10.今⽇作业
(1)完成课堂的所有练习
(2)完善kibana的启动脚本,使⽤systemctl⼯具管理kibana并设置为开机⾃启动;
进阶作业:
调研logstash的多pipline编写。ElasticSearch 的 Restful 风格 API 实战
1.Restful 及 JSON 格式
| 数据类型 | 描述 | 举例 |
|---|---|---|
| 字符串 | 要求使⽤双引号(””)引起来的数据 | “oldboyedu” |
| 数字 | 通常指的是 0-9 的所有数字。 | 100 |
| 布尔值 | 只有 true 和 false 两个值 | true |
| 空值 | 只有 null 一个值 | null |
| 数组 | 使⽤⼀对中括号(”[]”)放⼊不同的元素(⽀持⾼级数据类型和基础数据类型) | [“linux”,100,false] |
| 对象 | 使⽤⼀对⼤括号(”{}”)扩起来,⾥⾯的数据使⽤ KEY-VALUE 键值对即可。 | {“class”:”linux80”,”age”:25} |
Restful⻛格程序:
RESTFUL是⼀种⽹络应⽤程序的设计⻛格和开发⽅式,基于HTTP,可以使⽤XML格式定义或
JSON格式定义。
REST(英⽂:Representational State Transfer,简称REST)描述了⼀个架构样式的⽹络系统,⽐如 web 应⽤程序。
REST⾸次出现在2000年Roy Fielding的博⼠论⽂中,Roy Fielding是HTTP规范的主要编写者之⼀。
JSON语法:
基础数据类型:
字符串:
"oldboyedu"
"⽼男孩IT教育"
"2022"
""
数字:
0
1
2
...
布尔值:
true
false
空值:
null
⾼级数据类型:
数组:
["oldboyedu","沙河",2022,null,true,{"school":"oldboyedu","class":"linux80"}]
对象:
{"name":"oldboy", "age":40, "address":"北京沙河", "hobby":["Linux","思想课"],"other":null}
课堂练习:
使⽤json格式记录你的名字(name),年龄(age),学校(school),爱好(hobby),地址(address)。2.ElasticSearch 的相关术语
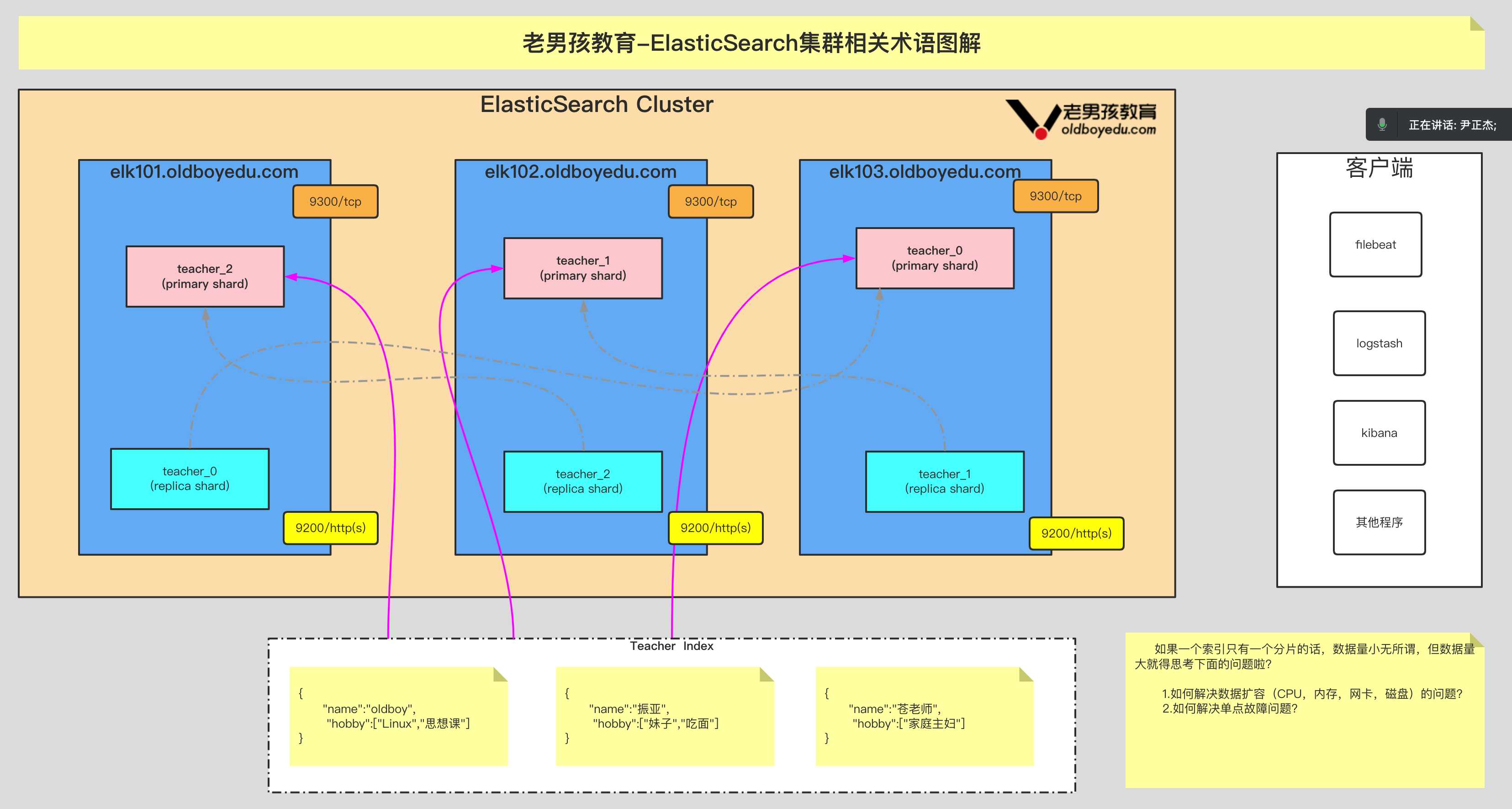
Document:
即⽂档,是⽤户存储在ES的⼀些数据,它是ES中最⼩的存储单元。换句话说,⼀个⽂档是不可被拆分的。
⼀个⽂档使⽤的是json的对象数据类型存储。
filed:
相当于数据库表的字段,对⽂档数据根据不同属性进⾏分类标示。
index:
即索引,⼀个索引就是⼀个拥有相似特征⽂档的集合。
shard:
即分⽚,是真正存储数据的地⽅,每个分⽚底层对应的是⼀个Lucene库。⼀个索引⾄少有1个或多个分⽚。
replica:
即副本,是对数据的备份,⼀个分⽚可以有0个或多个副本。
⼀旦副本数量不为0,就会引⼊主分⽚(primary shard)和副本分⽚(replica shard)的概念。
主分⽚(primary shard):
可以实现数据的读写操作。
副本分⽚(replica shard):
可以实现数据读操作,与此同时,需要去主分⽚同步数据,当主分⽚挂掉,副本分⽚会变为主分⽚。
Allocation:
即分配,将分⽚(shard)分配给某个节点的过程,包括主分⽚和副本分⽚。
如果是副本分⽚,还包含从主分⽚复制数据的过程,这个分配过程由master节点调度完成。
Type:
在es 5.x即更早的版本,在⼀个索引中,我们可以定义⼀种或多种数据类型。但在es7仅⽀持"_doc"类型。3.管理索引的 API
3.1 查看索引信息
GET http://10.0.0.101:9200/_cat/indices # 查看全部的索引信息
GET http://10.0.0.101:9200/_cat/indices?v # 查看表头信息
GET http://10.0.0.101:9200/_cat/indices/.kibana_7.17.3_001?v # 查看单个索引
GET http://10.0.0.101:9200/.kibana_7.17.3_001 # 查看单个索引的详细信息3.2 创建索引
PUT http://10.0.0.101:9200/oldboyedu-linux82 # 创建索引并指定分⽚和副本
{
"settings": {
"index": {
"number_of_shards": "3",
"number_of_replicas": 0
}
}
}
参数说明:
"number_of_shards": 指定分⽚数量。
"number_of_replicas": 指定副本数量。3.3 修改索引
PUT http://10.0.0.101:9200/oldboyedu-linux80/_settings
{
"number_of_replicas": 0
}
温馨提示:
分⽚数量⽆法修改,副本数量是可以修改的。3.4 删除索引
DELETE http://10.0.0.101:9200/oldboyedu-linux80
温馨提示:
删除索引,服务器的数据也会随之删除哟!3.5 索引别名
POST http://10.0.0.101:9200/_aliases # 添加索引别名
{
"actions": [
{
"add": {
"index": "oldboyedu-linux80",
"alias": "Linux容器运维"
}
},
{
"add": {
"index": "oldboyedu-linux82",
"alias": "DBA"
}
}
]
}
GET http://10.0.0.101:9200/_aliases # 查看索引别名
POST http://10.0.0.101:9200/_aliases # 删除索引别名
{
"actions": [
{
"remove": {
"index": "oldboyedu-linux80",
"alias": "Linux容器运维"
}
}
]
}
POST http://10.0.0.101:9200/_aliases # 修改索引别名
{
"actions": [
{
"remove": {
"index": "oldboyedu-linux82",
"alias": "DBA"
}
},
{
"add": {
"index": "oldboyedu-linux82",
"alias": "SRE"
}
}
]
}3.6 索引关闭
POST http://10.0.0.101:9200/oldboyedu-linux80/_close # 关闭索引
POST http://10.0.0.101:9200/oldboyedu-*/_close # 基于通配符关闭索引
温馨提示:
索引关闭意味着该索引⽆法进⾏任何的读写操作,但数据并不会被删除。3.7 索引打开
POST http://10.0.0.101:9200/oldboyedu-linux80/_open # 打开索引
POST http://10.0.0.101:9200/oldboyedu-*/_open # 基于通配符打开索引3.8 索引的其他操作
推荐阅读: https://www.elastic.co/guide/en/elasticsearch/reference/current/indices.html
4.管理文档的 API
4.1 文档的创建
POST http://10.0.0.101:9200/teacher/_doc # 创建⽂档不指定"_id"
{
"name": "oldboy",
"hobby": [
"Linux",
"思想课"
]
}
POST http://10.0.0.101:9200/student/_doc/1003 # 创建⽂档并指定ID
{
"name": "苍⽼师",
"hobby": [
"家庭主妇"
]
}4.2 文档的查看
GET http://10.0.0.101:9200/teacher/_search # 查看所有的⽂档
GET http://10.0.0.101:9200/teacher/_doc/4FHB0IABf2fC857QLdH6 # 查看某⼀个⽂档
HEAD http://10.0.0.101:9200/teacher/_doc/4FHB0IABf2fC857QLdH6 # 判断某⼀个⽂档是否存在,返回200,404.
温馨提示:
源数据:
指的是⽤户写⼊的数据。
元数据:
指的是描述数据的数据,由ES内部维护。4.3 文档的修改
POST http://10.0.0.101:9200/teacher/_doc/4FHB0IABf2fC857QLdH6 # 全量更新,会覆盖原有的⽂档数据内容。
{
"name": "oldboy",
"hobby": [
"Linux",
"思想课",
"抖⾳"
]
}
POST http://10.0.0.101:9200/teacher/_doc/4FHB0IABf2fC857QLdH6/_update # 局部更新,并不会覆盖原有的数据。
{
"doc":{
"name": "⽼男孩",
"age": 45
}
}4.4 文档的删除
DELETE http://10.0.0.101:9200/teacher/_doc/10014.5 文档的批量操作
POST http://10.0.0.101:9200/_bulk # 批量创建
{ "create": { "_index": "oldboyedu-linux80-elk"} }
{ "name": "oldboy","hobby":["Linux","思想课"] }
{ "create": { "_index": "oldboyedu-linux80-elk","_id": 1002} }
{ "name": "振亚","hobby":["妹⼦","吃⾯"] }
{ "create": { "_index": "oldboyedu-linux80-elk","_id": 1001} }
{ "name": "苍⽼师","hobby":["家庭主妇"] }
POST http://10.0.0.101:9200/_bulk # 批量删除
{ "delete" : { "_index" : "oldboyedu-linux80-elk", "_id" : "1001" } }
{ "delete" : { "_index" : "oldboyedu-linux80-elk", "_id" : "1002" } }
POST http://10.0.0.101:9200/_bulk # 批量修改
{ "update" : {"_id" : "1001", "_index" : "oldboyedu-linux80-elk"} }
{ "doc" : {"name" : "CangLaoShi"} }
{ "update" : {"_id" : "1002", "_index" : "oldboyedu-linux80-elk"} }
{ "doc" : {"name" : "ZhenYa"} }
POST http://10.0.0.101:9200/_mget # 批量查看
{
"docs": [
{
"_index": "oldboyedu-linux80-elk",
"_id": "1001"
},
{
"_index": "oldboyedu-linux80-elk",
"_id": "1002"
}
]
}温馨提示: 对于⽂档的批量写操作,需要使⽤_bulk的 API,⽽对于批量的读操作,需要使⽤_mget的 API。
参考链接:
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/docs-bulk.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/docs-multi-get.html
4.6 课堂的练习
将下⾯的数据存储到 ES 集群:
{"name":"oldboy","hobby":["Linux","思想课"]}
{"name":"振亚","hobby":["妹⼦","吃⾯"]}
{"name":"苍⽼师","hobby":["家庭主妇"]}5.使用映射(mapping)自定义数据类型
5.1 映射的数据类型
当写⼊⽂档时,字段的数据类型会被 ES 动态⾃动创建,但有的时候动态创建的类型并符合我们的需求。这个时候就可以使⽤映射解决。
使⽤映射技术,可以对 ES ⽂档的字段类型提前定义我们期望的数据类型,便于后期的处理和搜索。
- text: 全⽂检索,可以被全⽂匹配,即该字段是可以被拆分的。
- keyword: 精确匹配,必须和内容完全匹配,才能被查询出来。
- ip: ⽀持 Ipv4 和 Ipv6,将来可以对该字段类型进⾏ IP 地址范围搜索。
参考链接:
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/mapping.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/mapping-types.html
5.2 IP 案例
PUT http://10.0.0.101:9200/oldboyedu-linux80-elk # 创建索引时指定映射关系
{
"mappings" :{
"properties": {
"ip_addr" : {
"type": "ip"
}
}
}
}
GET http://10.0.0.101:9200/oldboyedu-linux80-elk # 查看索引的映射关系
POST http://10.0.0.101:9200/_bulk # 创建测试数据
{ "create": { "_index": "oldboyedu-linux80-elk"} }
{ "ip_addr": "192.168.10.101" }
{ "create": { "_index": "oldboyedu-linux80-elk"} }
{ "ip_addr": "192.168.10.201" }
{ "create": { "_index": "oldboyedu-linux80-elk"} }
{ "ip_addr": "172.31.10.100" }
{ "create": { "_index": "oldboyedu-linux80-elk"} }
{ "ip_addr": "10.0.0.222" }
GET http://10.0.0.101:9200/oldboyedu-linux80-elk/_search # 查看IP的⽹断
{
"query": {
"match" : {
"ip_addr": "192.168.0.0/16"
}
}
}5.3 其他类型类型案例
PUT http://10.0.0.101:9200/oldboyedu-linux80-elk-2022 # 创建索引
GET http://10.0.0.101:9200/oldboyedu-linux80-elk-2022# 查看索引信息
PUT http://10.0.0.101:9200/oldboyedu-linux80-elk-2022/_mapping # 为已创建的索引修改数据类型
{
"properties": {
"name": {
"type": "text",
"index": true
},
"gender": {
"type": "keyword",
"index": true
},
"telephone": {
"type": "text",
"index": false
},
"address": {
"type": "keyword",
"index": false
},
"email": {
"type": "keyword"
},
"ip_addr": {
"type": "ip"
}
}
}
POST http://10.0.0.101:9200/_bulk # 添加测试数据
{ "create": { "_index": "oldboyedu-linux80-elk-2022"} }
{ "ip_addr": "192.168.10.101" ,"name": "柳鹏","gender":"男性的","telephone":"33333333","address":"沙河","email":"liupeng@oldboyedu.com"}
{ "create": { "_index": "oldboyedu-linux80-elk-2022"} }
{ "ip_addr": "192.168.20.21" ,"name": "王岩","gender":"男性的","telephone":"55555","address":"松兰堡","email":"wangyan@oldboyedu.com"}
{ "create": { "_index": "oldboyedu-linux80-elk-2022"} }
{ "ip_addr": "172.28.30.101" ,"name": "赵嘉欣","gender":"⼥性的","telephone":"33333333","address":"于⾟庄","email":"zhaojiaxin@oldboyedu.com"}
{ "create": { "_index": "oldboyedu-linux80-elk-2022"} }
{ "ip_addr": "172.28.50.121" ,"name": "庞冉","gender":"⼥性的","telephone":"444444444","address":"于⾟庄","email":"pangran@oldboyedu.com"}
{ "create": { "_index": "oldboyedu-linux80-elk-2022"} }
{ "ip_addr": "10.0.0.67" ,"name": "王浩任","gender":"男性的","telephone":"22222222","address":"松兰堡","email":"wanghaoren@oldboyedu.com"}
GET http://10.0.0.101:9200/oldboyedu-linux80-elk-2022/_search # 基于gender字段搜索
{
"query":{
"match":{
"gender": "⼥"
}
}
}
GET http://10.0.0.101:9200/oldboyedu-linux80-elk-2022/_search # 基于name字段搜索
{
"query":{
"match":{
"name": "王"
}
}
}
GET http://10.0.0.101:9200/oldboyedu-linux80-elk-2022/_search # 基于email字段搜索
{
"query":{
"match":{
"email": "pangran@oldboyedu.com"
}
}
}
GET http://10.0.0.101:9200/oldboyedu-linux80-elk-2022/_search # 基于ip_addr字段搜索
{
"query": {
"match" : {
"ip_addr": "192.168.0.0/16"
}
}
}
GET http://10.0.0.101:9200/oldboyedu-linux80-elk-2022/_search # 基于address字段搜索,⽆法完成。
{
"query":{
"match":{
"address": "松兰堡"
}
}
}6. IK 中文分词器
6.1 内置的标准分词器 - 分析英文
GET http://10.0.0.101:9200/_analyze
{
"analyzer": "standard",
"text": "My name is Jason Yin, and I'm 18 years old !"
}温馨提示: 标准分词器模式使⽤空格和符号进⾏切割分词的。
6.2 内置的标准分词器 - 分析中文并不友好
GET http://10.0.0.101:9200/_analyze
{
"analyzer": "standard",
"text": "我爱北京天安⻔!"
}温馨提示: 标准分词器默认使⽤单个汉⼦进⾏切割,很明显,并不符合我们国内的使⽤习惯。
6.3 安装 IK 分词器
下载地址: https://github.com/medcl/elasticsearch-analysis-ik
安装 IK 分词器:
install -d /oldboyedu/softwares/es/plugins/ik -o oldboyedu -g oldboyed
cd /oldboyedu/softwares/es/plugins/ik
unzip elasticsearch-analysis-ik-7.17.3.zip
rm -f elasticsearch-analysis-ik-7.17.3.zip
chown -R oldboyedu:oldboyedu *重启 ES 节点,使之加载插件:
systemctl restart es测试 IK 分词器:
GET http://10.0.0.101:9200/_analyze # 细粒度拆分
{
"analyzer": "ik_max_word",
"text": "我爱北京天安⻔!"
}
GET http://10.0.0.101:9200/_analyze # 粗粒度拆分
{
"analyzer": "ik_smart",
"text": "我爱北京天安⻔!"
}6.4 自定义 IK 分词器的字典
# (1)进⼊到IK分词器的插件安装⽬录
cd /oldboyedu/softwares/es/plugins/ik/config
# (2)⾃定义字典
cat > oldboyedu-linux80.dic <<EOF
上号
德玛⻄亚
艾欧尼亚
亚索
EOF
chown oldboyedu:oldboyedu oldboyedu-linux80.dic
# (3)加载⾃定义字典
vim IKAnalyzer.cfg.xml
...
<entry key="ext_dict">oldboyedu-linux80.dic</entry>
# (4)重启ES集群
systemctl restart es
# (5)测试分词器
GET http://10.0.0.101:9200/_analyze
{
"analyzer": "ik_smart",
"text": "嗨,哥们! 上号,我德玛⻄亚和艾欧尼亚都有号! 我亚索贼6,肯定能带你⻜!!!"
}6.5 自定义分词器 - 了解即可
# (1)⾃定义分词器
PUT http://10.0.0.101:9200/oldboyedu_linux80_2022
{
"settings":{
"analysis":{
"char_filter":{
"&_to_and":{
"type": "mapping",
"mappings": ["& => and"]
}
},
"filter":{
"my_stopwords":{
"type":"stop",
"stopwords":["the","a","if","are","to","be","kind"]
}
},
"analyzer":{
"my_analyzer":{
"type":"custom",
"char_filter":["html_strip","&_to_and"],
"tokenizer": "standard",
"filter":["lowercase","my_stopwords"]
}
}
}
}
}
# (2)验证置⾃定义分词器是否⽣效
GET http://10.0.0.101:9200/oldboyedu_linux80_2022/_analyze
{
"text":"If you are a PERSON, Please be kind to small Animals.",
"analyzer":"my_analyzer"
}7. 今日作业
(1)将"shopping.json"⽂件的内容使⽤"_bulk"的API批量写⼊ES集群,要求索引名称为"oldboyedu-shopping";
(2)每⼈收集10条数据并写⼊ES集群,索引名称为"oldboyedu-linux80"7.1 shopping.json
{
"title": "戴尔(DELL)31.5英⼨ 4K 曲⾯ 内置⾳箱 低蓝光 影院级⾊彩 FreeSync技术 可壁挂 1800R 电脑显示器 S3221QS",
"price": 3399.00,
"brand": "Dell",
"weight": "15.25kg",
"item": "https://item.jd.com/100014940686.html"
},
{
"title": "三星(SAMSUNG)28英⼨ 4K IPS 10.7亿⾊ 90%DCI-P3 Eyecomfort2.0认证 专业设计制图显示器(U28R550UQC)",
"price": 2099.00,
"brand": "SAMSUNG",
"weight": "7.55kg",
"item": "https://item.jd.com/100009558656.html"
},
{
"title": "ALIENWARE外星⼈新品外设⾼端键⿏套装AW510K机械键盘cherry轴RGB/AW610M 610M ⽆线⿏标+510K机械键盘+510H⽿机",
"price": 6000.00,
"brand": "ALIENWARE外星⼈",
"weight": "1.0kg",
"item": "https://item.jd.com/10030370257612.html"
},
{
"title": "樱桃CHERRY MX8.0彩光87键游戏机械键盘合⾦⼥⽣樱粉⾊版 彩光-粉⾊红轴-粉⾊箱 官⽅标配",
"price": 4066.00,
"brand": "樱桃CHERRY",
"weight": "1.0kg",
"item": "https://item.jd.com/10024385308012.html"
},
{
"title": "罗技(G)G610机械键盘 有线机械键盘 游戏机械键盘 全尺⼨背光机械键盘 吃鸡键盘 Cherry红轴",
"price": 429.00,
"brand": "罗技",
"weight": "1.627kg",
"item": "https://item.jd.com/3378484.html"
},
{
"title": "美商海盗船(USCORSAIR)K68机械键盘⿊⾊ 防⽔防尘樱桃轴体 炫彩背光游戏有线 红光红轴",
"price": 499.00,
"brand": "美商海盗船",
"weight": "1.41kg",
"item": "https://item.jd.com/43580479783.html"
},
{
"title": "雷蛇(Razer) 蝰蛇标准版 ⿏标 有线⿏标 游戏⿏标 ⼈体⼯程学 电竞 ⿊⾊6400DPI lol吃鸡神器cf",
"price": 109.00,
"brand": "雷蛇",
"weight": "185.00g",
"item": "https://item.jd.com/8141909.html"
},
{
"title": "罗技(G)G502 HERO主宰者有线⿏标 游戏⿏标 HERO引擎 RGB⿏标 电竞⿏标 25600DPI",
"price": 299.00,
"brand": "罗技",
"weight": "250.00g",
"item": "https://item.jd.com/100001691967.html"
},
{
"title": "武极 i5 10400F/GTX1050Ti/256G游戏台式办公电脑主机DIY组装机",
"price": 4099.00,
"brand": "武极",
"weight": "5.0kg",
"item": "https://item.jd.com/1239166056.html"
},
{
"title": "变异者 组装电脑主机DIY台式游戏 i5 9400F/16G/GTX1050Ti 战胜G1",
"price": 4299.00,
"brand": "变异者",
"weight": "9.61kg",
"item": "https://item.jd.com/41842373306.html"
},
{
"title": "宏碁(Acer) 暗影骑⼠·威N50-N92 英特尔酷睿i5游戏台机 吃鸡电脑主机(⼗⼀代i5-11400F 16G 256G+1T GTX1650)",
"price": 5299.00,
"brand": "宏碁",
"weight": "7.25kg",
"item": "https://item.jd.com/100020726324.html"
},
{
"title": "京天 酷睿i7 10700F/RTX2060/16G内存 吃鸡游戏台式电脑主机DIY组装机",
"price": 7999.00,
"brand": "京天",
"weight": "10.0kg",
"item": "https://item.jd.com/40808512828.html"
},
{
"title": "戴尔(DELL)OptiPlex 3070MFF/3080MFF微型台式机电脑迷你⼩主机客厅HTPC 标配 i5-10500T/8G/1T+256G 内置WiFi+蓝⽛ 全国联保 三年上⻔",
"price": 3999.00,
"brand": "DELL",
"weight": "2.85kg",
"item": "https://item.jd.com/10025304273651.html"
},
{
"title": "伊萌纯种英短蓝⽩猫活体猫咪幼猫活体英国短⽑猫矮脚猫英短蓝猫幼体银渐层蓝⽩活体宠物蓝猫幼崽猫咪宠物猫短 双⾎统A级 ⺟",
"price": 4000.00,
"brand": "英短",
"weight": "1.0kg",
"item": "https://item.jd.com/10027188382742.html"
},
{
"title": "柴墨 ⾦渐层幼猫英短猫宠物猫英短⾦渐层猫咪活体猫活体纯种⼩猫银渐层 双⾎统",
"price": 12000.00,
"brand": "英短",
"weight": "3.0kg",
"item": "https://item.jd.com/10029312412476.html"
},
{
"title": "Redmi Note10 Pro 游戏智能5G⼿机 ⼩⽶ 红⽶",
"price": 9999.00,
"brand": "⼩⽶",
"weight": "10.00g",
"item": "https://item.jd.com/100021970002.html"
},
{
"title": "【⼆⼿99新】⼩⽶Max3⼿机⼆⼿⼿机 ⼤屏安卓 曜⽯⿊ 6G+128G 全⽹通",
"price": 1046.00,
"brand": "⼩⽶",
"weight": "0.75kg",
"item": "https://item.jd.com/35569092038.html"
},
{
"title": "现货速发(10天价保)⼩⽶11 5G⼿机 骁⻰888 游戏智能⼿机 PRO店内可选⿊⾊ 套装版 12GB+256GB",
"price": 4699.00,
"brand": "⼩⽶",
"weight": "0.7kg",
"item": "https://item.jd.com/10025836790851.html"
},
{
"title": "⼩⽶⼿环6 NFC版 全⾯彩屏 30种运动模式 24h⼼率检测 50⽶防⽔ 智能⼿环",
"price": 279.00,
"brand": "⼩⽶",
"weight": "65.00g",
"item": "https://item.jd.com/100019867468.html"
},
{
"title": "HUAWEI MateView⽆线原⾊显示器⽆线版 28.2英⼨ 4K+ IPS 98% DCI-P310.7亿⾊ HDR400 TypeC 双扬声器 双MIC",
"price": 4699.00,
"brand": "华为",
"weight": "9.8kg",
"item": "https://item.jd.com/100021420806.html"
},
{
"title": "华为nova7se/nova7 se 5G⼿机( 12期免息可选 )下单享好礼 绮境森林乐活版 8G+128G(1年碎屏险)",
"price": 2999.00,
"brand": "华为",
"weight": "500.00g",
"item": "https://item.jd.com/10029312412476.html"
},
{
"title": "华为HUAWEI FreeBuds 4i主动降噪 ⼊⽿式真⽆线蓝⽛⽿机/通话降噪/⻓续航/⼩巧舒适 Android&ios通⽤ 陶瓷⽩",
"price": 479.00,
"brand": "华为",
"weight": "137.00g",
"item": "https://item.jd.com/100018510746.html"
},
{
"title": "HUAWEI WATCH GT2 华为⼿表 运动智能⼿表 两周⻓续航/蓝⽛通话/⾎氧检测/麒麟芯⽚ 华为gt2 46mm 曜⽯⿊",
"price": 1488.00,
"brand": "华为",
"weight": "335.00g",
"item": "https://item.jd.com/100008492922.html"
},
{
"title": "Apple苹果12 mini iPhone 12 mini 5G ⼿机(现货速发 12期免息可选)蓝⾊ 5G版 64G",
"price": 4699.00,
"brand": "苹果",
"weight": "280.00g",
"item": "https://item.jd.com/10026100075337.html"
},
{
"title": "Apple iPhone 12 (A2404) 128GB 紫⾊ ⽀持移动联通电信5G 双卡双待⼿机",
"price": 6799.00,
"brand": "苹果",
"weight": "330.00g",
"item": "https://item.jd.com/100011203359.html"
},
{
"title": "华硕ROG冰刃双屏 ⼗代英特尔酷睿 15.6英⼨液⾦导热300Hz电竞游戏笔记本电脑 i9-10980H 32G 2T RTX2080S",
"price": 48999.00,
"brand": "华硕",
"weight": "2.5kg",
"item": "https://item.jd.com/10021558215658.html"
},
{
"title": "联想⼩新Air15 2021超轻薄笔记本电脑 ⾼⾊域学⽣办公设计师游戏本 ⼋核锐⻰R7-5700U 16G内存 512G固态 升级15.6英⼨IPS全⾯屏【DC调光护眼⽆闪烁】",
"price": 5499.00,
"brand": "苹果",
"weight": "10.0kg",
"item": "https://item.jd.com/33950552707.html"
},
{
"title": "苹果(Apple)MacBook Air 13.3英⼨ 笔记本电脑 【2020款商务灰】⼗代i7 16G 512G 官⽅标配 19点前付款当天发货",
"price": 10498.00,
"brand": "苹果",
"weight": "1.29kg",
"item": "https://item.jd.com/10021130510120.html"
},
{
"title": "科⼤讯⻜机器⼈ 阿尔法蛋A10智能机器⼈ 专业教育⼈⼯智能编程机器⼈学习机智能可编程 ⽩⾊",
"price": 1099.00,
"brand": "科⼤讯⻜",
"weight": "1.7kg",
"item": "https://item.jd.com/100005324258.html"
},
{
"title": "robosen乐森机器⼈六⼀⼉童节礼物⾃营孩⼦玩具星际特⼯智能编程机器⼈⼉童语⾳控制陪伴益智变形机器⼈",
"price": 2499.00,
"brand": "senpowerT9-X",
"weight": "3.01kg",
"item": "https://item.jd.com/100006740372.html"
},
{
"title": "优必选(UBTECH)悟空智能语⾳监控对话⼈形机器⼈⼉童教育陪伴早教学习机玩具",
"price": 4999.00,
"brand": "优必选悟空",
"weigth": "1.21kg",
"item": "https://item.jd.com/100000722348.html"
}7.2 oldboyedu-linux80.json
等你来完善...
要求如下:
(1)收集源数据,要求包含"title","price","brand","weigth","item","producer";
"title" 商品的标题。
"price" 商品的价格。
"brand" 商品的品牌。
"weigth" 商品的重量。
"item" 商品的链接。
"producer" 收集者姓名。
(2)要求使⽤ES的批量操作的API完成;参考案例 1
POST http://10.0.0.103:9200/_bulk
{"create":{"_index":"oldboyedu-shopping"}}{"title":"戴尔(DELL)31.5英⼨ 4K 曲⾯ 内置⾳箱 低蓝光 影院级⾊彩 FreeSync技术 可壁挂 1800R 电脑显示器 S3221QS","price":3399.00,"brand":"Dell","weight":"15.25kg","item":"https://item.jd.com/100014940686.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"三星(SAMSUNG)28英⼨ 4K IPS 10.7亿⾊ 90%DCI-P3 Eyecomfort2.0认证 专业设计制图显示器(U28R550UQC)","price":2099.00,"brand":"SAMSUNG","weight":"7.55kg","item":"https://item.jd.com/100009558656.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"ALIENWARE外星⼈新品外设⾼端键⿏套装AW510K机械键盘cherry轴RGB/AW610M 610M ⽆线⿏标+510K机械键盘+510H⽿机","price":6000.00,"brand":"ALIENWARE外星⼈","weight":"1.0kg","item":"https://item.jd.com/10030370257612.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"樱桃CHERRY MX8.0彩光87键游戏机械键盘合⾦⼥⽣樱粉⾊版 彩光-粉⾊红轴-粉⾊箱 官⽅标配","price":4066.00,"brand":"樱桃CHERRY","weight":"1.0kg","item":"https://item.jd.com/10024385308012.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"罗技(G)G610机械键盘 有线机械键盘 游戏机械键盘 全尺⼨背光机械键盘 吃技","weight":"1.627kg","item":"https://item.jd.com/3378484.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"美商海盗船(USCORSAIR)K68机械键盘⿊⾊ 防⽔防尘樱桃轴体 炫彩背光游戏有线 红光红轴","price":499.00,"brand":"美商海盗船","weight":"1.41kg","item":"https://item.jd.com/43580479783.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"雷蛇(Razer) 蝰蛇标准版 ⿏标 有线⿏标 游戏⿏标 ⼈体⼯程学 电竞 ⿊⾊6400DPI lol吃鸡神器cf","price":109.00,"brand":"雷蛇","weight":"185.00g","item":"https://item.jd.com/8141909.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"罗技(G)G502 HERO主宰者有线⿏标 游戏⿏标 HERO引擎 RGB⿏标 电竞⿏标25600DPI","price":299.00,"brand":"罗技","weight":"250.00g","item":"https://item.jd.com/100001691967.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"武极 i5 10400F/GTX1050Ti/256G游戏台式办公电脑主机DIY组装机","price":4099.00,"brand":"武极","weight":"5.0kg","item":"https://item.jd.com/1239166056.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"宏碁(Acer) 暗影骑⼠·威N50-N92 英特尔酷睿i5游戏台机 吃鸡电脑主机(⼗⼀代i5-11400F 16G 256G+1T GTX1650)","price":5299.00,"brand":"宏碁","weight":"7.25kg","item":"https://item.jd.com/100020726324.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"京天 酷睿i7 10700F/RTX2060/16G内存 吃鸡游戏台式电脑主机DIY组装机","price":7999.00,"brand":"京天","weight":"10.0kg","item":"https://item.jd.com/40808512828.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"戴尔(DELL)OptiPlex 3070MFF/3080MFF微型台式机电脑迷你⼩主机客厅HTPC 标配 i5-10500T/8G/1T+256G 内置WiFi+蓝⽛ 全国联保 三年上⻔","price":3999.00,"brand":"DELL","weight":"2.85kg","item":"https://item.jd.com/10025304273651.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"伊萌纯种英短蓝⽩猫活体猫咪幼猫活体英国短⽑猫矮脚猫英短蓝猫幼体银渐层蓝⽩活体宠物蓝猫幼崽猫咪宠物猫短 双⾎统A级 ⺟","price":4000.00,"brand":"英短","weight":"1.0kg","item":"https://item.jd.com/10027188382742.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"柴墨 ⾦渐层幼猫英短猫宠物猫英短⾦渐层猫咪活体猫活体纯种⼩猫银渐层 双⾎统","price":12000.00,"brand":"英短","weight":"3.0kg","item":"https://item.jd.com/10029312412476.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"Redmi Note10 Pro 游戏智能5G⼿机 ⼩⽶ 红⽶","price":9999.00,"brand":"⼩⽶","weight":"10.00g","item":"https://item.jd.com/100021970002.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"【⼆⼿99新】⼩⽶Max3⼿机⼆⼿⼿机 ⼤屏安卓 曜⽯⿊ 6G+128G 全⽹通","price":1046.00,"brand":"⼩⽶","weight":"0.75kg","item":"https://item.jd.com/35569092038.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"现货速发(10天价保)⼩⽶11 5G⼿机 骁⻰888 游戏智能⼿机 PRO店内可选⿊⾊ 套装版 12GB+256GB","price":4699.00,"brand":"⼩⽶","weight":"0.75kg","item":"https://item.jd.com/10025836790851.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"⼩⽶⼿环6 NFC版 全⾯彩屏 30种运动模式 24h⼼率检测 50⽶防⽔ 智能⼿环","price":279.00,"brand":"⼩⽶","weight":"65.00g","item":"https://item.jd.com/100019867468.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"HUAWEI MateView⽆线原⾊显示器⽆线版 28.2英⼨ 4K+ IPS 98% DCI-P310.7亿⾊ HDR400 TypeC 双扬声器 双MIC","price":4699.00,"brand":"华为","weight":"9.8kg","item":"https://item.jd.com/100021420806.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"华为nova7se/nova7 se 5G⼿机( 12期免息可选 )下单享好礼 绮境森林 乐活版 8G+128G(1年碎屏险)","price":2999.00,"brand":"华为","weight":"500.00g","item":"https://item.jd.com/10029312412476.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"华为HUAWEI FreeBuds 4i主动降噪 ⼊⽿式真⽆线蓝⽛⽿机/通话降噪/⻓续航/⼩巧舒适 Android&ios通⽤ 陶瓷⽩","price":479.00,"brand":"华为","weight":"137.00g","item":"https://item.jd.com/100018510746.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"HUAWEI WATCH GT2 华为⼿表 运动智能⼿表 两周⻓续航/蓝⽛通话/⾎氧检测/麒麟芯⽚ 华为gt2 46mm 曜⽯⿊","price":1488.00,"brand":"华为","weight":"335.00g","item":"https://item.jd.com/100008492922.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"Apple苹果12 mini iPhone 12 mini 5G ⼿机(现货速发 12期免息可选)蓝⾊ 5G版 64G","price":4699.00,"brand":"苹果","weight":"280.00g","item":"https://item.jd.com/10026100075337.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"Apple iPhone 12 (A2404) 128GB 紫⾊ ⽀持移动联通电信5G 双卡双待⼿机","price":6799.00,"brand":"苹果","weight":"330.00g","item":"https://item.jd.com/100011203359.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"华硕ROG冰刃双屏 ⼗代英特尔酷睿 15.6英⼨液⾦导热300Hz电竞游戏笔记本电脑 i9-10980H 32G 2T RTX2080S","price":48999.00,"brand":"华硕","weight":"2.5kg","item":"https://item.jd.com/10021558215658.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"联想⼩新Air15 2021超轻薄笔记本电脑 ⾼⾊域学⽣办公设计师游戏本 ⼋核锐⻰R7-5700U 16G内存 512G固态 升级15.6英⼨IPS全⾯屏【DC调光护眼⽆闪烁】","price":5499.00,"brand":"苹果","weight":"10.0kg","item":"https://item.jd.com/33950552707.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"苹果(Apple)MacBook Air 13.3英⼨ 笔记本电脑 【2020款商务灰】⼗代i7 16G 512G 官⽅标配 19点前付款当天发货","price":10498.00,"brand":"苹果","weight":"1.29kg","item":"https://item.jd.com/10021130510120.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"科⼤讯⻜机器⼈ 阿尔法蛋A10智能机器⼈ 专业教育⼈⼯智能编程机器⼈学习机智能可编程 ⽩⾊","price":1099.00,"brand":"科⼤讯⻜","weight":"1.7kg","item":"https://item.jd.com/100005324258.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"robosen乐森机器⼈六⼀⼉童节礼物⾃营孩⼦玩具星际特⼯智能编程机器⼈⼉童语⾳控制陪伴益智变形机器⼈","price":2499.00,"brand":"senpowerT9-X","weight":"3.01kg","item":"https://item.jd.com/100006740372.html"}
{"create":{"_index":"oldboyedu-shopping"}}{"title":"优必选(UBTECH)悟空智能语⾳监控对话⼈形机器⼈⼉童教育陪伴早教学习机玩具","price":4999.00,"brand":"优必选悟空","weight":"1.21kg","item":"https://item.jd.com/100000722348.html"}参考案例 2
# (1)启动filebeat
cat > config-filebeat/02-log-to-es.yml <<EOF
filebeat.inputs:
- type: log
paths:
- /tmp/shopping.json
json.keys_under_root: true
output.logstash:
hosts: ["10.0.0.101:8888"]
EOF
./filebeat -e -c config-filebeat/02-log-to-es.yml
# (2)启动logstash
cat > conf-logstash/02-beats-to-es.conf <<EOF
input {
beats {
port => 8888
}
}
filter {
mutate {
remove_field => ["host","@timestamp","tags","log","agent","@version", "input","ecs"]
}
}
output {
stdout {}
elasticsearch {
hosts => ["10.0.0.101:9200","10.0.0.102:9200","10.0.0.103:9200"]
index => "oldboyedu-linux80-shopping"
}
}
EOF
logstash -rf conf-logstash/02-beats-to-es.conf索引模板
1.什么是索引模板
索引模板是创建索引的⼀种⽅式。
当数据写⼊指定索引时,如果该索引不存在,则根据索引名称匹配相应索引模板的话,会根据模板的配置⽽建⽴索引。
索引模板仅对新创建的索引⽣效,对已经创建的索引是没有任何作⽤的。
推荐阅读: https://www.elastic.co/guide/en/elasticsearch/reference/7.17/index-templates.html
2.查看索引模板
GET http://10.0.0.103:9200/_template # 查看所有的索引模板
GET http://10.0.0.103:9200/_template/oldboyedu-linux80 # 查看单个索引模板3.创建/修改索引模板
POST http://10.0.0.103:9200/_template/oldboyedu-linux80
{
"aliases": {
"DBA": {},
"SRE": {},
"K8S": {}
},
"index_patterns": [
"oldboyedu-linux80*"
],
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 0
}
},
"mappings": {
"properties":{
"ip_addr": {
"type": "ip"
},
"access_time": {
"type": "date"
},
"address": {
"type" :"text"
},
"name": {
"type": "keyword"
}
}
}
}4.删除索引模板
DELETE http://10.0.0.103:9200/_template/oldboyedu-linux80ES 的 DSL 语句查询 - DBA 方向需要掌握!
1.什么是 DSL
Elasticsearch 提供了基于 JSON 的完整 Query DSL(Domain Specific Language,领域特定语⾔)来定义查询。
2.全文检索 - match 查询
POST http://10.0.0.103:9200/oldboyedu-shopping/_search
{
"query": {
"match" : {
"brand":"⼩苹华"
}
}
}
温馨提示:
查询品牌是"⼩苹华"的所有商品。背后的逻辑是会对中⽂进⾏分词。3.完全匹配 - match_phrase 查询
POST http://10.0.0.103:9200/oldboyedu-shopping/_search
{
"query": {
"match_phrase" : {
"brand":"⼩苹华"
}
}
}
温馨提示:
查询品牌是"⼩苹华"的所有商品。背后的逻辑并不会对中⽂进⾏分词。4.全量查询 - match_all
POST http://10.0.0.103:9200/oldboyedu-shopping/_search
{
"query": {
"match_all" : {}
}
}
温馨提示:
请求体的内容可以不写,即默认就是发起了全量查询(match_all)。5.分页查询 - size-from
POST http://10.0.0.103:9200/oldboyedu-shopping/_search
{
"query": {
"match_all" : {}
},
"size": 7,
"from": 28
}
相关参数说明:
size:
指定每⻚显示多少条数据,默认值为10.
from:
指定跳过数据偏移量的⼤⼩,默认值为0,即默认看第⼀⻚。
查询指定⻚码的from值 = "(⻚码 - 1) * 每⻚数据⼤⼩(size)"
温馨提示:
⽣产环境中,不建议深度分⻚,百度的⻚码数量控制在76⻚左右。6.查看“_source”对象的指定字段
POST http://10.0.0.103:9200/oldboyedu-shopping/_search
{
"query": {
"match_all" : {}
},
"size": 7,
"from": 28,
"_source": ["brand","price"]
}
相关参数说明:
_source:
⽤于指定查看"_source"对象的指定字段。7.查询包含指定字段的文档 - exists
POST http://10.0.0.103:9200/oldboyedu-shopping/_search
{
"query": {
"exists" : {
"field": "hobby"
}
}
}
相关参数说明:
exists
判断某个字段是否存在,若存在则返回该⽂档,若不存在,则不返回⽂档。8.语法高亮 - hightlight
POST http://10.0.0.103:9200/oldboyedu-shopping/_search
{
"query": {
"match": {
"brand": "苹果"
}
},
"highlight": {
"pre_tags": [
"<h1>"
],
"post_tags": [
"</h1>"
],
"fields": {
"brand": {}
}
}
}
相关参数说明:
highlight: 设置⾼亮。
fields: 指定对哪个字段进⾏语法⾼亮。
pre_tags: ⾃定义⾼亮的前缀标签。
post_tags ⾃定义⾼亮的后缀标签。9.基于字段进行排序 - sort
POST http://10.0.0.103:9200/oldboyedu-shopping/_search
{
"query": {
"match_phrase": {
"brand": "苹果"
}
},
"sort": {
"price" :{
"order": "asc"
}
}
}
相关字段说明:
sort: 基于指定的字段进⾏排序。此处为指定的是"price"
order: 指定排序的规则,分为"asc"(升序)和"desc"(降序)。10.多条件查询 - bool
POST http://10.0.0.103:9200/oldboyedu-shopping/_search
{
"query":{
"bool" :{
"must": [
{
"match_phrase": {
"brand" :" 苹果"
}
},
{
"match": {
"price": 5499
}
}
]
}
}
}
POST http://10.0.0.103:9200/oldboyedu-shopping/_search
{
"query":{
"bool" :{
"must_not": [
{
"match_phrase": {
"brand" :" 苹果"
}
},
{
"match": {
"price": 3399
}
}
]
}
}
}
POST http://10.0.0.103:9200/oldboyedu-shopping/_search
{
"query": {
"bool": {
"should": [
{
"match_phrase": {
"brand": " 苹果"
}
},
{
"match": {
"price": 5499
}
},
{
"match_phrase": {
"brand": " ⼩⽶"
}
}
],
"minimum_should_match": 2
}
}
}
温馨提示:
bool: 可以匹配多个条件查询。其中有"must","must_not","should"。
"must" 必须匹配的条件。
"must_not" 必须不匹配的条件,即和must相反。
"should" 不是必要条件,满⾜其中之⼀即可,可以使⽤"minimum_should_match"来限制满⾜要求的条件数量。11.范围查询 - filter
POST http://10.0.0.103:9200/oldboyedu-shopping/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"brand": " 苹果"
}
}
],
"filter": {
"range": {
"price": {
"gt": 5000,
"lt": 8000
}
}
}
}
}
}
相关字段说明:
filter 过滤数据。
range: 基于范围进⾏过滤,此处为基于的是"price"进⾏过滤。
常⻅的操作符如下:
gt: ⼤于。
lt: ⼩于。
gte: ⼤于等于。
lte: ⼩于等于。12.精确匹配多个值 - terms
POST http://10.0.0.103:9200/oldboyedu-shopping/_search
{
"query": {
"terms": {
"price": [
4699,
299,
4066
]
}
}
}13.多词搜索 - 了解即可
POST http://10.0.0.103:9200/oldboyedu-shopping/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": {
"query": "显示器曲⾯",
"operator": "and"
}
}
}
]
}
},
"highlight": {
"pre_tags": [
"<h1>"
],
"post_tags": [
"</h1>"
],
"fields": {
"title": {}
}
}
}
温馨提示:
当我们将"operator"设置为"and"则⽂档必须包含"query"中的所有词汇,"operator"的默认值为"or"。14.权重案例 - 了解即可
POST http://10.0.0.103:9200/oldboyedu-shopping/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"brand": {
"query": "⼩苹华"
}
}
}
],
"should": [
{
"match_phrase": {
"title": {
"query": "防⽔",
"boost": 2
}
}
},
{
"match_phrase": {
"title": {
"query": "⿊⾊",
"boost": 10
}
}
}
]
}
},
"highlight": {
"fields": {
"title": {},
"brand": {}
}
},
"_source": ""
}
温馨提示:
修改"boost"字段的值来提升相应权重。15.聚合查询 - 了解即可
POST http://10.0.0.103:9200/oldboyedu-shopping/_search # 统计每个品牌的数量。
{
"aggs": {
"oldboyedu_brand_group": {
"terms":{
"field": "brand.keyword"
}
}
},
"size": 0
}
POST http://10.0.0.103:9200/oldboyedu-shopping/_search # 统计苹果商品中最贵的。
{
"query": {
"match_phrase": {
"brand": "苹果"
}
},
"aggs": {
"oldboyedu_max_shopping": {
"max": {
"field": "price"
}
}
},
"size": 0
}
POST http://10.0.0.103:9200/oldboyedu-shopping/_search # 统计华为商品中最便宜的。
{
"query": {
"match_phrase": {
"brand": "华为"
}
},
"aggs": {
"oldboyedu_min_shopping": {
"min": {
"field": "price"
}
}
},
"size": 0
}
POST http://10.0.0.103:9200/oldboyedu-shopping/_search # 统计⼩⽶商品的品均架构。
{
"query": {
"match_phrase": {
"brand": "⼩⽶"
}
},
"aggs": {
"oldboyedu_avg_shopping": {
"avg": {
"field": "price"
}
}
},
"size": 0
}
POST http://10.0.0.103:9200/oldboyedu-shopping/_search # 统计⻢下⼩⽶所有商品的价格。
{
"query": {
"match_phrase": {
"brand": "⼩⽶"
}
},
"aggs": {
"oldboyedu_sum_shopping": {
"sum": {
"field": "price"
}
}
},
"size": 0
}ES 集群迁移
1.部署 ES6 分布式集群
# (1)下载ES 6的软件包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.8.23.tar.gz
# (2)解压软件包并创建数据⽬录和⽇志⽬录
tar xf elasticsearch-6.8.23.tar.gz -C /oldboyedu/softwares/
install -d /oldboyedu/{data,logs}/es6 -o oldboyedu -g oldboyedu
chown oldboyedu:oldboyedu -R /oldboyedu/softwares/elasticsearch-6.8.23/
# (3)修改配置⽂件
vim /oldboyedu/softwares/elasticsearch-6.8.23/config/elasticsearch.yml
.....
cluster.name: oldboyedu-linux80-es6
node.name: elk101
path.data: /oldboyedu/data/es6
path.logs: /oldboyedu/logs/es6
network.host: 0.0.0.0
http.port: 19200
transport.tcp.port: 19300
discovery.zen.ping.unicast.hosts: ["10.0.0.101","10.0.0.102","10.0.0.103"]
discovery.zen.minimum_master_nodes: 2
# (4)同步环境到其他节点
data_rsync.sh /oldboyedu/softwares/elasticsearch-6.8.23
# (5)其他节点修改⼀下⼏个参数即可修改各节点的"node.name"名称即可。
# (6)编写启动脚本
cat > /etc/sysconfig/jdk <<EOF
JAVA_HOME=/oldboyedu/softwares/jdk
EOF
cat > /usr/lib/systemd/system/es68.service <<EOF
[Unit]
Description=Oldboyedu linux80 ELK
After=network.target
[Service]
Type=forking
EnvironmentFile=/etc/sysconfig/jdk
ExecStart=/oldboyedu/softwares/elasticsearch-6.8.23/bin/elasticsearch -d
Restart=no
User=oldboyedu
Group=oldboyedu
LimitNOFILE=131070
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
# (7)启动服务
systemctl start es682.基于_reindex 的 API 迁移
POST http://10.0.0.103:9200/_reindex
{
"source": {
"index": "oldboyedu-shopping"
},
"dest": {
"index": "oldboyedu-shopping-new"
}
}
# 不同⼀个集群迁移索引
POST http://10.0.0.103:9200/_reindex
{
"source": {
"index": "oldboyedu-shopping",
"remote": {
"host": "http://10.0.0.101:19200"
},
"query": {
"match_phrase": {
"brand": "Dell"
}
}
},
"dest": {
"index": "oldboyedu-shopping-new-22222222222"
}
}
温馨提示:
(1)不同集群迁移时,需要修改9200端⼝对应的ES7的elasticsearch.yml配置⽂件,添加如下内容,并重启集群。
reindex.remote.whitelist: "*:*"
(2)跨集群迁移时,可以使⽤DSL语句来对源集群的数据进⾏过滤,⽐如上⾯的"query"语句。
推荐阅读:
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/docs-reindex.html3.基于 logstash 实现索引跨集群迁移
[root@elk101.oldboyedu.com ~]$ cat conf-logstash/03-es-to-es.conf
input {
elasticsearch {
index => "oldboyedu-shopping"
hosts => "10.0.0.101:19200"
query => '{ "query": { "match_phrase": { "brand": "dell" } }}'
}
}
output {
stdout { }
elasticsearch {
index => "oldboyedu-shopping-6666666666666666666"
hosts => "10.0.0.101:9200"
}
}
[root@elk101.oldboyedu.com ~]$
[root@elk101.oldboyedu.com ~]$ logstash -rf conf-logstash/03-es-to-es.conf
温馨提示:
对于低版本的数据迁移到⾼版本时,⽐如从ES5迁移到ES7,应该注意不同点:
(1)默认的分⽚数量和副本数量;
(2)默认的⽂档类型是否相同,尤其是在ES7版本中移除了type类型,仅保留了"_doc"这⼀种内置类型;ES 集群常用的 API
1.ES 集群健康状态 API(heath)

# (1)安装jq⼯具
yum -y install epel-release
yum -y install jq
# (2)测试取数据
curl http://10.0.0.103:9200/_cluster/health 2>/dev/null| jq
curl http://10.0.0.103:9200/_cluster/health 2>/dev/null| jq .status
curl http://10.0.0.103:9200/_cluster/health 2>/dev/null| jq
.active_shards_percent_as_number
相关参数说明:
cluster_name
集群的名称。
status
集群的健康状态,基于其主分⽚和副本分⽚的状态。
ES集群有以下三种状态:
green 所有分⽚都已分配。
yellow 所有主分⽚都已分配,但⼀个或多个副本分⽚未分配。如果集群中的某个节点发⽣故障,则在修复该节点之前,某些数据可能不可⽤。
red ⼀个或多个主分⽚未分配,因此某些数据不可⽤。这可能会在集群启动期间短暂发⽣,因为分配了主分⽚。
timed_out
是否在参数false指定的时间段内返回响应(默认情况下30秒)。
number_of_nodes
集群内的节点数。
number_of_data_nodes
作为专⽤数据节点的节点数。
active_primary_shards
可⽤主分⽚的数量。
active_shards
可⽤主分⽚和副本分⽚的总数。
relocating_shards
正在重定位的分⽚数。
initializing_shards
正在初始化的分⽚数。
unassigned_shards
未分配的分⽚数。
delayed_unassigned_shards
分配因超时设置⽽延迟的分⽚数。
number_of_pending_tasks
尚未执⾏的集群级别更改的数量。
number_of_in_flight_fetch
未完成的提取次数。
task_max_waiting_in_queue_millis
⾃最早启动的任务等待执⾏以来的时间(以毫秒为单位)。
active_shards_percent_as_number
集群中活动分⽚的⽐率,以百分⽐表示。2.ES 集群的设置及优先级(settings)
如果您使⽤多种⽅法配置相同的设置,Elasticsearch 会按以下优先顺序应⽤这些设置:
(1)Transient setting(临时配置,集群重启后失效)
(2)Persistent setting(持久化配置,集群重启后依旧⽣效)
(3)elasticsearch.yml setting(配置⽂件)
(4)Default setting value(默认设置值)
# (1)查询集群的所有配置信息
GET http://10.0.0.103:9200/_cluster/settings?include_defaults=true&flat_settings=true
# (2)修改集群的配置信息
PUT http://10.0.0.103:9200/_cluster/settings
{
"transient": {
"cluster.routing.allocation.enable": "none"
}
}
相关参数说明:
"cluster.routing.allocation.enable":
"all" 允许所有分⽚类型进⾏分配。
"primaries" 仅允许分配主分⽚。
"new_primaries" 仅允许新创建索引分配主分⽚。
"none" 不允许分配任何类型的分配。
参考链接:
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/cluster-get-settings.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/cluster-update-settings.html3.集群状态 API(state)
集群状态是⼀种内部数据结构,它跟踪每个节点所需的各种信息,包括:
(1)集群中其他节点的身份和属性
(2)集群范围的设置
(3)索引元数据,包括每个索引的映射和设置
(4)集群中每个分⽚副本的位置和状态
# (1)查看集群的状态信息
GET http://10.0.0.103:9200/_cluster/state
# (2)只查看节点信息。
GET http://10.0.0.103:9200/_cluster/state/nodes
# (3)查看nodes,version,routing_table这些信息,并且查看以"oldboyedu*"开头的所有索引
http://10.0.0.103:9200/_cluster/state/nodes,version,routing_table/oldboyedu*
推荐阅读:
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/cluster-state.html4.集群统计 API(stats)
Cluster Stats API 允许从集群范围的⻆度检索统计信息。返回基本索引指标(分⽚数量、存储⼤⼩、内存使⽤情况)和有关构成集群的当前节点的信息(数量、⻆⾊、操作系统、jvm 版本、内存使⽤情况、cpu 和已安装的插件)。
# (1)查看统计信息
GET http://10.0.0.103:9200/_cluster/stats
推荐阅读:
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/cluster-stats.html5.查看集群的分片分配情况(allocation)
集群分配解释 API 的⽬的是为集群中的分⽚分配提供解释。
对于未分配的分⽚,解释 API 提供了有关未分配分⽚的原因的解释。
对于分配的分⽚,解释 API 解释了为什么分⽚保留在其当前节点上并且没有移动或重新平衡到另⼀个节点。
当您尝试诊断分⽚未分配的原因或分⽚继续保留在其当前节点上的原因时,此 API 可能⾮常有⽤,⽽您可能会对此有所期待。
# (1)分析teacher索引的0号分⽚未分配的原因。
GET http://10.0.0.101:9200/_cluster/allocation/explain
{
"index": "teacher",
"shard": 0,
"primary": true
}
推荐阅读:
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/cluster-allocation-explain.html6.集群分片重路由 API(reroute)
reroute 命令允许⼿动更改集群中各个分⽚的分配。
例如,可以将分⽚从⼀个节点显式移动到另⼀个节点,可以取消分配,并且可以将未分配的分⽚显式分配给特定节点。
POST http://10.0.0.101:9200/_cluster/reroute # 将"teacher"索引的0号分⽚从elk102节点移动到elk101节点。
{
"commands": [
{
"move": {
"index": "teacher",
"shard": 0,
"from_node": "elk102.oldboyedu.com",
"to_node": "elk101.oldboyedu.com"
}
}
]
}
POST http://10.0.0.101:9200/_cluster/reroute # 取消副本分⽚的分配,其副本会重新初始化分配。
{
"commands": [
{
"cancel": {
"index": "teacher",
"shard": 0,
"node": "elk101.oldboyedu.com"
}
}
]
}推荐阅读: https://www.elastic.co/guide/en/elasticsearch/reference/7.17/cluster-reroute.html
7.今日作业
(1)完成课堂的所有练习;
进阶作业:
(2)使⽤zabbix健康ES集群的健康状态,包含以下2个指标:
curl http://10.0.0.103:9200/_cluster/health 2>/dev/null| jq .status
curl http://10.0.0.103:9200/_cluster/health 2>/dev/null| jq .active_shards_percent_as_numberES 集群理论篇
1.倒排索引
⾯试题: 分⽚底层时如何⼯作的?
答: 分⽚底层对应的是⼀个 Lucene 库,⽽ Lucene 底层使⽤倒排索引技术实现。
正排索引(正向索引)
我们 MySQL 为例,⽤ id 字段存储博客⽂章的编号,⽤ context 存储⽂件的内容。
CREATE TABLE blog (id INT PRIMARY KEY AUTO_INCREMENT, contextTEXT);
INDEX blog VALUES (1,'I am Jason Yin, I love Linux ...')此时,如果我们查询⽂章内容包含”Jason Yin”的词汇的时候,就⽐较麻烦了,因为要进⾏全表扫描。
SELECT * FROM blog WHERE context LIKE 'Jason Yin';倒排索引(反向索引)
ES 使⽤⼀种称为”倒排索引”的结构,它适⽤于快速的全⽂检索。
倒排索引中有以下三个专业术语:
1、词条:
指的是最⼩的存储和查询单元,换句话说,指的是您想要查询的关键字(词)。
对应英⽂⽽⾔通常指的是⼀个单词,⽽对于中⽂⽽⾔,对应的是⼀个词组。
2、词典(字典):
它是词条的集合,底层通常基于”Btree+”和”HASHMap”实现。
3、倒排表:
记录了词条出现在什么位置,出现的频率是什么。
倒排表中的每⼀条记录我们称为倒排项。
倒排索引的搜索过程:
- ⾸先根据⽤户需要查询的词条进⾏分词后,将分词后的各个词条字典进⾏匹配,验证词条在词典中是否存在;
- 如果上⼀步搜索结果发现词条不在字典中,则结束本次搜索,如果在词典中,就需要去查看倒排表中的记录(倒排项);
- 根据倒排表中记录的倒排项来定位数据在哪个⽂档中存在,⽽后根据这些⽂档的”_id”来获取指定的数据;
综上所述,假设有 10 亿篇⽂章,对于 mysql 不创建索引的情况下,会进⾏全表扫描搜索”JasonYin”。⽽对于 ES ⽽⾔,其只需要将倒排表中返回的 id 进⾏扫描即可,⽽⽆须进⾏全量查询。
2.集群角色

⻆⾊说明:
c: Cold data
d: data node
f: frozen node
h: hot node
i: ingest node
l: machine learning node
m: master eligible node
r: remote cluster client node
s: content node
t: transform node
v: voting-only node
w: warm node
-: coordinating node only
常⽤的⻆⾊说明:
data node: 指的是存储数据的节点。
node.data: true
master node: 控制ES集群,并维护集群的状态(cluster state,包括节点信息,索引信息等,ES集群每个节点都有⼀份)。
node.master: true
coordinating: 协调节点可以处理请求的节点,ES集群所有的节点均为协调节点,该⻆⾊⽆法取消。3.文档的写流程
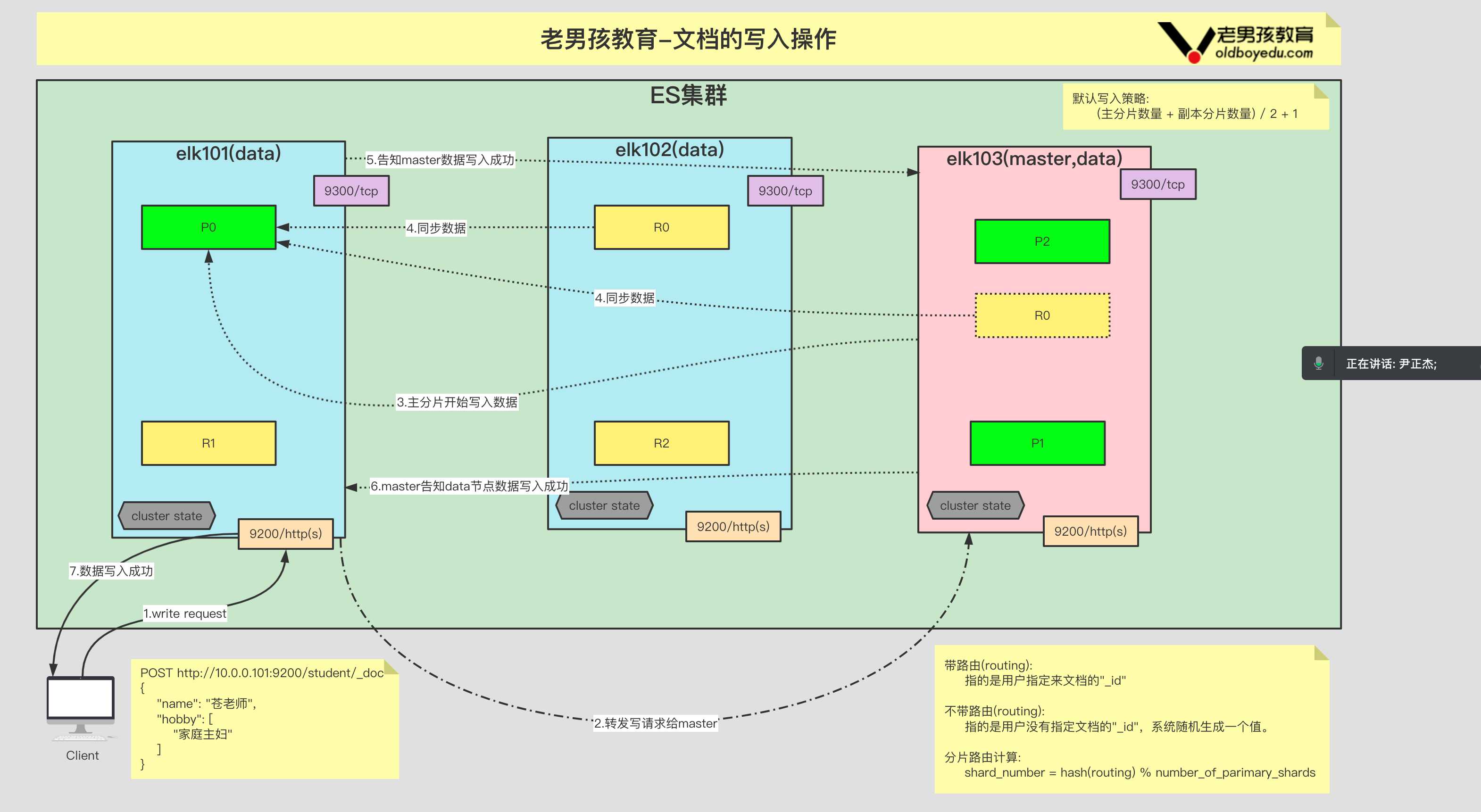
4.单个文档的读流程
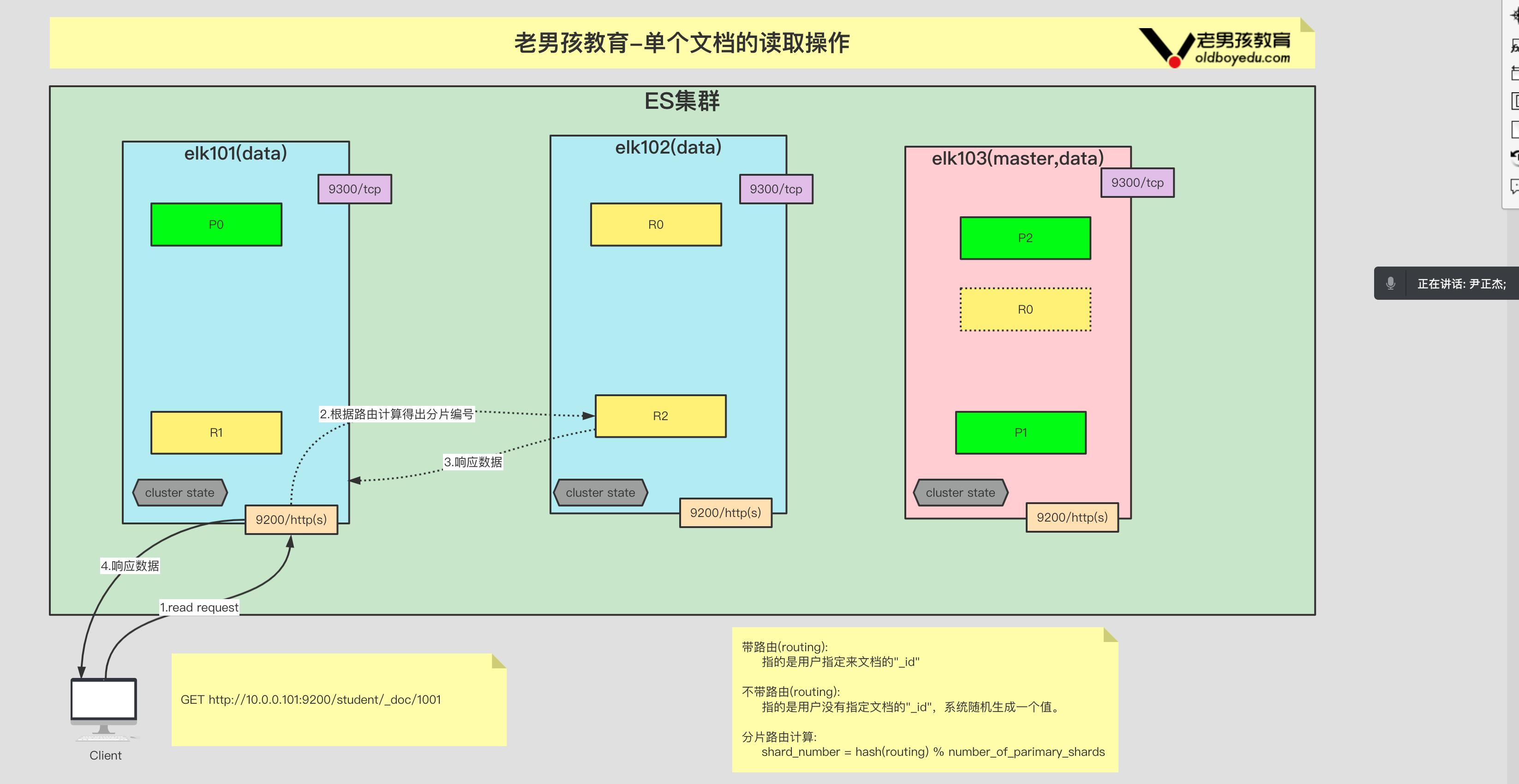
5.ES 底层存储原理剖析
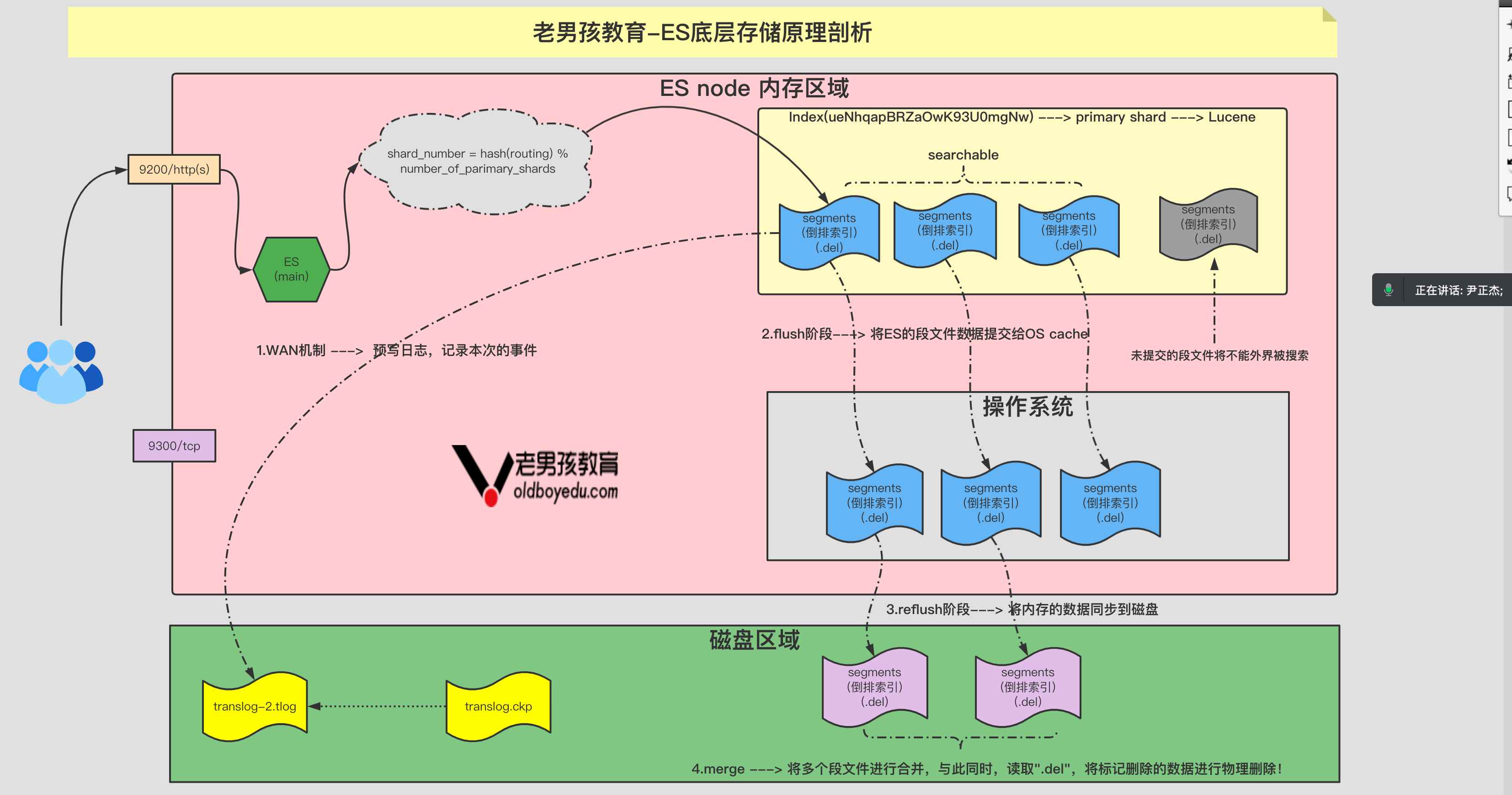
事务⽇志存储在哪⾥?
在索引分⽚⽬录下,取名⽅式如下:
translog-N.tlog: 真正的⽇志⽂件,N表示generation(代)的意思,通过它跟索引⽂件关联
tranlog.ckp: ⽇志的元数据⽂件,⻓度总是20个字节,记录3个信息:偏移量 & 事务操作数量 & 当前代什么时候删事务⽇志?
在flush的时候,translog⽂件会被清空。实际的过程是先删掉⽼⽂件,再创建⼀个新⽂件,取名时,序号加1,⽐如图2中,flush后你只会看到 translog-2.tlog,原来的translog-1.tlog已被删除。为什么要删?
因为数据修改已经写⼊磁盘了,之前的旧的⽇志就⽆⽤武之地了,留着只能⽩嫖存储空间。6.乐观锁机制 - 了解即可
两种⽅法通常被⽤来解决并发更新时变更不会丢失的解决⽅案:
1、悲观并发控制
这种⽅法被关系型数据库⼴泛使⽤,它假定有变更冲突可能发⽣,因此阻塞访问资源以防⽌冲突。⼀个典型的例⼦是修改⼀⾏数据之前像将其锁住,确保只有获得锁的线程能够对这⾏数据进⾏修改。
2、乐观锁并发控制
ES 中使⽤的这种⽅法假设冲突是不可能发⽣的,并且不会阻塞正在尝试的操作。然⽽,如果源数据在读写当中被修改,更新将会失败。应⽤程序接下来该如果解决冲突。例如,可以重试更新,使⽤新的数据,或者将相关情况报告给⽤户。
# (1)创建⽂档
PUT http://10.0.0.103:9200/oldboyedu_student/_doc/10001
{
"name": "王岩",
"age":25,
"hobby":["苍⽼师","⽼男孩","欧美"]
}
# (2)模拟事物1修改
POST http://10.0.0.103:9200/oldboyedu_student/_doc/10001/_update?
if_seq_no=0&if_primary_term=1
{
"doc": {
"hobby": [
"⽇韩",
"国内"
]
}
}
# (3)模拟事物2修改(如果上⾯的事物执⾏成功,则本事物执⾏失败,因为"_seq_no"发⽣变化)
POST http://10.0.0.103:9200/oldboyedu_student/_doc/10001/_update?
if_seq_no=0&if_primary_term=1
{
"doc": {
"hobby": [
"欧美"
]
}
}
# 扩展:(基于扩展的version版本来控制)
POST http://10.0.0.103:9200/oldboyedu_student/_doc/10001?version=10&version_type=external
{
"name": "oldboy",
"hobby": [
"⽇韩",
"国内"
]
}python 操作 ES 集群 API 实战
1.创建索引
#!/usr/bin/env python3
# _*_coding:utf-8_*_
from elasticsearch import Elasticsearch
es = Elasticsearch(['10.0.0.101:9200', '10.0.0.102:9200',
'10.0.0.103:9200'])
msg_body = {
"settings": {
"index": {
"number_of_replicas": "0",
"number_of_shards": "5"
}
},
"mappings": {
"properties": {
"ip_addr": {
"type": "ip"
},
"name": {
"type": "text"
},
"id": {
"type": "long"
},
"hobby": {
"type": "text"
},
"email": {
"type": "keyword"
}
}
},
"aliases": {
"oldboyedu-elstaicstack-linux80-python": {},
"oldboyedu-linux80-python": {}
}
}
result = es.indices.create(index="oldboyedu-linux80-2022", body=msg_body)
print(result)
es.close()2.写⼊单个⽂档
#!/usr/bin/env python3
# _*_coding:utf-8_*_
import sys
from elasticsearch import Elasticsearch
# 设置字符集,兼容Python2
reload(sys)
sys.setdefaultencoding('utf-8')
es = Elasticsearch(['10.0.0.101:9200', '10.0.0.102:9200',
'10.0.0.103:9200'])
# 写⼊单个⽂档
msg_body = {
"name": "Jason Yin",
"ip_addr": "120.53.104.136",
"blog": "https://blog.yinzhengjie.com/",
"hobby": ["k8s", "docker", "elk"],
"email": "yinzhengjie@oldboyedu.com",
"id": 10086,
}
result = es.index(index="oldboyedu-linux80-2022", doc_type="_doc", body=msg_body)
print(result)
es.close()3.写入多个文档
#!/usr/bin/env python3
# _*_coding:utf-8_*_
import sys
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
# 设置字符集,兼容Python2
reload(sys)
sys.setdefaultencoding('utf-8')
es = Elasticsearch(['10.0.0.101:9200', '10.0.0.102:9200',
'10.0.0.103:9200'])
# 批量写⼊多个⽂档
doc2 = {
"id": 10010,
"name": "⽼男孩",
"age": 45,
"hobby": ["下棋", "抖⾳", "思想课"],
"ip_addr": "10.0.0.101",
"email": "oldboy@oldboyedu.com"
}
doc3 = {
"id": 10011,
"name": "李导",
"age": 32,
"hobby": ["三剑客", "打枪"],
"email": "lidao@oldboyedu.com",
"ip_addr": "10.0.0.201"
}
doc4 = {
"id": 100012,
"name": "赵嘉欣",
"age": 24,
"hobby": ["⽇韩", "⼩说", "王岩"],
"email": "zhaojiaxin@oldboyedu.com",
"ip_addr": "10.0.0.222"
}
many_doc = [doc2, doc3, doc4]
write_number, _ = bulk(es, many_doc, index="oldboyedu-linux80-2022")
print(write_number)
es.close()4.全量查询
#!/usr/bin/env python3
# _*_coding:utf-8_*_
from elasticsearch import Elasticsearch
es = Elasticsearch(['10.0.0.101:9200', '10.0.0.102:9200',
'10.0.0.103:9200'])
# 全量查询
result = es.search(index="oldboyedu-linux80-2022")
print(result)
print(result["hits"])
print(result["hits"]["hits"])
print(result["hits"]["hits"][0]["_source"])
print(result["hits"]["hits"][0]["_source"]["name"])
print(result["hits"]["hits"][0]["_source"]["hobby"])
es.close()
5.查看多个文档
#!/usr/bin/env python3
# _*_coding:utf-8_*_
import sys
from elasticsearch import Elasticsearch
# 设置字符集,兼容Python2
reload(sys)
sys.setdefaultencoding('utf-8')
es = Elasticsearch(['10.0.0.101:9200', '10.0.0.102:9200',
'10.0.0.103:9200'])
# 获取多个⽂档
doc1 = {'ids': ["5gIk24AB2f3QZVpX1AxN", "5AIk24AB2f3QZVpX1AxN"]}
res = es.mget(index="oldboyedu-linux80-2022", body=doc1)
print(res)
print(res['docs'])
es.close()6.DSL 查询
#!/usr/bin/env python3
# _*_coding:utf-8_*_
import sys
from elasticsearch import Elasticsearch
# 设置字符集,兼容Python2
reload(sys)
sys.setdefaultencoding('utf-8')
es = Elasticsearch(['10.0.0.101:9200', '10.0.0.102:9200',
'10.0.0.103:9200'])
# DSL语句查询
dsl = {
"query": {
"match": {
"hobby": "王岩"
}
}
}
# DSL语句查询
# dsl = {
# "query": {
# "bool": {
# "should": [
# {
# "match": {
# "type": "pets"
# }
# },
# {
# "match": {
# "type": "lunxury"
# }
# }
# ],
# "minimum_should_match": 1,
# "filter": {
# "range": {
# "price": {
# "gt": 1500,
# "lt": 2500
# }
# }
# }
# }
# },
# "sort": {
# "price": {
# "order": "desc"
# }
# },
# "_source": [
# "title",
# "price",
# "producer"
# ]
# }
res = es.search(index="shopping", body=dsl)
print(res)
res = es.search(index="oldboyedu-linux80-2022", body=dsl)
print(res)
es.close()7.查看索引是否存在
#!/usr/bin/env python3
# _*_coding:utf-8_*_
from elasticsearch import Elasticsearch
es = Elasticsearch(['10.0.0.101:9200', '10.0.0.102:9200',
'10.0.0.103:9200'])
# 判断索引是否存在
print(es.indices.exists(index="oldboyedu-shopping"))
es.close()8.修改文档
#!/usr/bin/env python3
# _*_coding:utf-8_*_
from elasticsearch import Elasticsearch
es = Elasticsearch(['10.0.0.101:9200', '10.0.0.102:9200', '10.0.0.103:9200'])
new_doc = {
'doc': {"hobby": ['下棋', '抖⾳', '思想课', "Linux运维"], 'address': '中华⼈⺠共和国北京市昌平区沙河镇⽼男孩教育'}}
# 更新⽂档
res = es.update(index="oldboyedu-linux80-2022", id='5gIk24AB2f3QZVpX1AxN', body=new_doc)
print(res)
es.close()9.删除单个文档
#!/usr/bin/env python3
# _*_coding:utf-8_*_
from elasticsearch import Elasticsearch
es = Elasticsearch(['10.0.0.101:9200', '10.0.0.102:9200', '10.0.0.103:9200'])
# 删除单个⽂档
result = es.delete(index="oldboyedu-linux80-2022", id="5gIk24AB2f3QZVpX1AxN")
print(result)
es.close()10.删除索引
#!/usr/bin/env python3
# _*_coding:utf-8_*_
from elasticsearch import Elasticsearch
es = Elasticsearch(['10.0.0.101:9200', '10.0.0.102:9200', '10.0.0.103:9200'])
# 删除索引
result = es.indices.delete(index="oldboyedu-linux80-2022")
print(result)
es.close()ES 集群加密的 Kibana 的 RABC 实战
1.基于 nginx 反向代理控制 kibana
# (1)部署nginx服务 略,参考之前的笔记即可。
# (2)编写nginx的配置⽂件
cat > /etc/nginx/conf.d/kibana.conf <<EOF
server {
listen 80;
server_name kibana.oldboyedu.com;
location / {
proxy_pass http://10.0.0.103:5601$request_uri;
auth_basic "oldboyedu kibana web!";
auth_basic_user_file conf/htpasswd;
}
}
EOF
# (3)创建账号⽂件
mkdir -pv /etc/nginx/conf
htpasswd -c -b /etc/nginx/conf/htpasswd admin oldboyedu
# (4)启动nginx服务
nginx -t
systemcat restart nginx
# (5)访问nginx验证kibana访问 如下图所示。
2.配置 ES 集群 TLS 认证
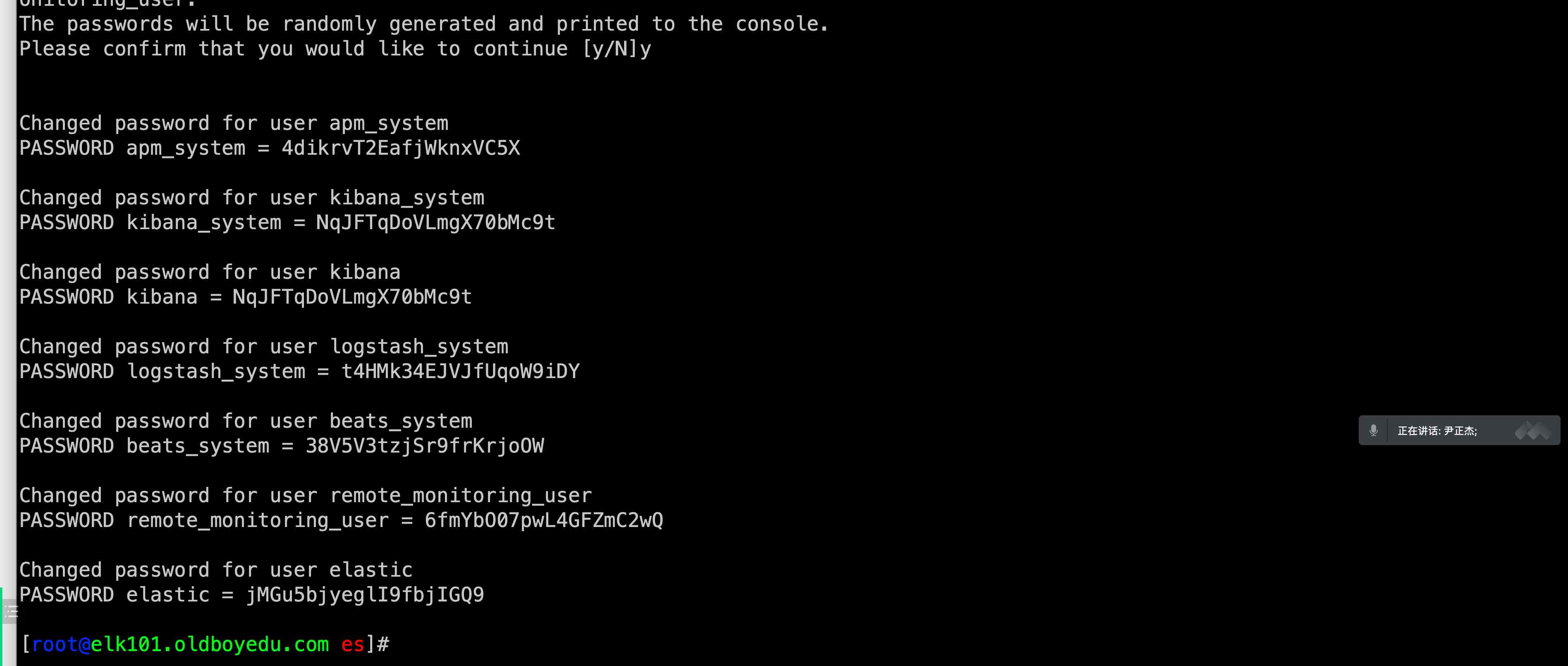
# (1)⽣成证书⽂件
cd /oldboyedu/softwares/es/
elasticsearch-certutil cert -out config/elastic-certificates.p12 -pass ""
# (2)为证书⽂件修改属主和属组
chown oldboyedu:oldboyedu config/elastic-certificates.p12
# (3)同步证书⽂件到其他节点
data_rsync.sh `pwd`/config/elastic-certificates.p12
# (4)修改ES集群的配置⽂件
vim/oldboyedu/softwares/es/config/elasticsearch.yml
...
# 在最后⼀⾏添加以下内容
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
# (5)同步ES配置⽂件到其他节点
data_rsync.sh `pwd`/config/elasticsearch.yml
# (6)所有节点重启ES集群
systemctl restart es
# (7)⽣成随机密码(如上图所示)
elasticsearch-setup-passwords auto
# (8)postman访问 如下图所示。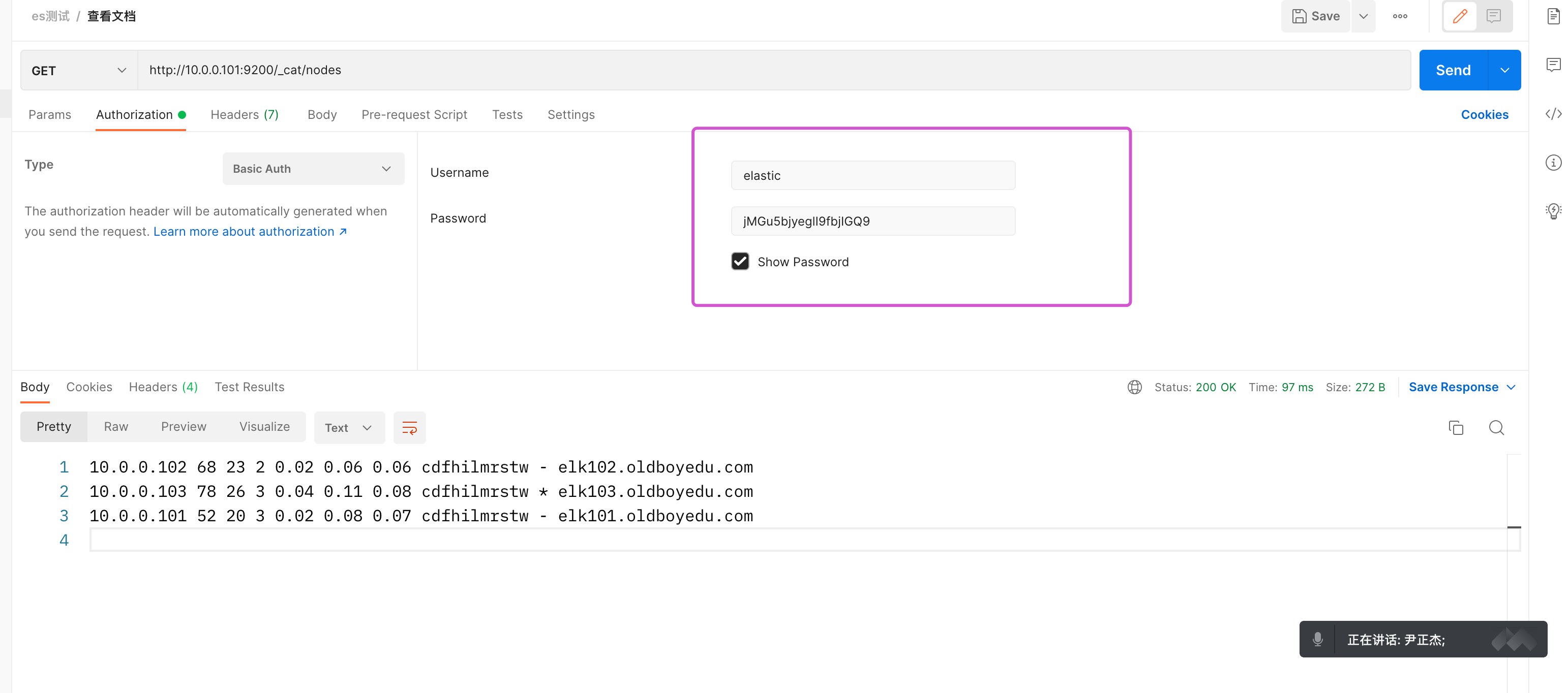
3.kibana 添加 ES 认证
# (1)修改kibana的配置⽂件
vim /oldboyedu/softwares/kibana/config/kibana.yml
...
elasticsearch.username: "kibana_system"
elasticsearch.password: "NqJFTqDoVLmgX70bMc9t"
# (2)重启kibana访问
su -c "kibana" oldboyedu
# (3)访问测试 如下图所示。
4.kibana 的 RBAC

具体实操⻅视频。
5.logstash 写入 ES 加密集群案例
input {
stdin {}
}
output {
stdout { }
elasticsearch {
index => "oldboyedu-linux80-logstash-6666666666666666666"
hosts => "10.0.0.101:9200"
user => "logstash-linux80"
password => "123456"
}
}温馨提示:
建议⼤家不要使⽤ elastic 管理员⽤户给 logstash 程序使⽤,⽽是创建⼀个普通⽤户,并为该⽤户细化权限。
6.filebeat 写入 ES 加密集群案例
filebeat.inputs:
- type: stdin
output.elasticsearch:
enabled: true
hosts: ["http://10.0.0.101:9200", "http://10.0.0.102:9200", "http://10.0.0.103:9200"]
index: "oldboyedu-linux80-stdin-%{+yyyy.MM.dd}"
username: "filebeat-linux80"
password: "123456"
setup.ilm.enabled: false
setup.template.name: "oldboyedu-linux"
setup.template.pattern: "oldboyedu-linux*"
setup.template.overwrite: true
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 0温馨提示:
建议⼤家不要使⽤ elastic 管理员⽤户给 filebeat 程序使⽤,⽽是创建⼀个普通⽤户,并为该⽤户细化权限。